
İNSAN HAFIZASI yapıları ve süreçleri
ARNOLD KLATSKY
İÇERİK
Çeviri editörünün önsözü
Önsöz
Bölüm 1 Giriş
Temel konseptler
Bölüm 2
Sistem ve bileşenleri
Hafızanın ikiliği teorisi. Bir hatıra mı yoksa iki mi?
Bölüm 3 Duyusal Kayıtlar
görsel kayıt
işitsel kayıt
Bölüm 4 Örüntü Tanıma
Bellek kodları ve tanıma
Tanıma ile ilgili süreçler
Dikkat
Genel Örüntü Tanıma Modeli
Bölüm 5
Tekrarlama
Kısa süreli belleğin yapısı ve kapasitesi
Bilinç ve kısa süreli hafıza
Bölüm 6
unutma teorileri
Distraktör ile deneyler
Diğer Çeldirici Deneyler
Bilişsel süreçlerin unutmaya etkisi
Bölüm 7
Kısa süreli bellekte görsel kodlar
Kısa süreli bellekteki anlamsal kodlar
Dualite teorisi hakkında birkaç kelime daha
Bölüm 8
Uzun süreli belleğin yapısı
Uzun süreli belleğin ağ modelleri
Anlamsal bellek verileri
DP'nin set-teorik modeli
Anlamsal özelliklere dayalı DP modeli
Bölüm 9
Proaktif ve geriye dönük frenleme
Girişim ve unutma
Unutma ve doğal dil
Girişim: bazı sonuçlar
10. Bölüm Kodlama süreçleri
Doğal dil ile arabuluculuk
Aracı olarak cümleler ve resimler
Ücretsiz geri çağırmada organizasyon
Bölüm 11
Tanıma
Bilgi alma ve geri çağırma
Tanıma ve çoğaltma işlemlerinin karşılaştırılması
Bölüm 12
Figüratif bilgi için hafıza
Zihinsel görüntüler ve hafıza
Görüntü Hipotezine İtirazlar
Hala "görüntüler" var mı? Anlaşmazlığı çözmenin olası yolu
Bölüm 13
Anımsatıcılar ve anımsatıcılar
Kaynakça
Çeviri editörünün önsözü
Şu anda, hafıza çalışmasına iki yaklaşım var. Yaklaşımlardan biri psikofizyolojik olarak adlandırılabilir: insan hafızasının psikofiziksel düzeyde analiziyle başlayan çalışma, daha sonra onun nöral mekanizmalarının açığa çıkarılmasıyla devam eder. Psikofiziksel ve nöral seviyelerde elde edilen sonuçların birleştirilmesi, çok sıkı gerekliliklerin dayatıldığı bir modelin inşasıyla sona erer. Nöron benzeri öğelerden oluşan bir bellek modeli, bir bütün olarak, psikofiziksel düzeyde saptanabilen özelliklere sahip olmalıdır. Aynı zamanda her bir nöron benzeri eleman, modelde fonksiyonel rolünü taklit ettiği o gerçek nöronun özelliklerini taşımalıdır. Model için bu kadar katı gereksinimler, tüm modeller arasından gerçek yapılara en yakın olanların seçilmesine yol açar.Genel olarak, psikofizyolojik analiz, "insan-nöron-modeli" şemasıyla temsil edilebilir.
Başka bir yaklaşıma genellikle psikolojik olan denir. Bu durumda araştırmacı, psikofiziksel düzeyde bulunan bu hafıza kalıplarını oluşturma görevini kendisine koyar. Nöral mekanizmalar dikkate alınmaz. Bu durumda teorik genelleme, bir modelin inşasıyla da sona erer. Bununla birlikte, modelin bellek süreçlerini en genel biçimde yeniden üretmesi gerektiğinden, buradaki olası modellerin aralığı psikofizyolojik yaklaşımdan çok daha geniştir. R. L. Klatsky'nin kitabında sunulan hafıza sorununa bu psikolojik yaklaşımdır.
Kitabın bir özelliği, hafızanın bilişsel psikoloji çerçevesinde bilgi süreçleri açısından ele alınmasıdır. "Uyaran-tepki" ilkesi üzerine inşa edilen davranışçılığın aksine, bilişsel psikoloji, hiyerarşik olarak organize edilmiş bir bilişsel süreçler sisteminin önemini vurgular. Bu sistem, yeniden kodlama ve bilgi depolama blokları olarak tasarlanmıştır. Aynı zamanda, bilgi dönüşümleri, değerlendirilmeleri için katı önlemler alınmadan en genel biçimde ele alınır. Son yıllarda, bilgisayar teknolojisindeki gelişimin bilişsel psikoloji üzerinde güçlü bir etkisi olmuştur. Bu, yazarın kullandığı terminolojiye de yansımıştır. Kitabın kavramsal yapısını oluşturan modeller de büyük ölçüde bilgisayar teorisi alanından ödünç alınmıştır.
Hafıza çalışmasına yönelik psikofizyolojik yaklaşımı bilişsel bilgi yaklaşımıyla karşılaştırırken, bu yaklaşımlardan ikincisi çerçevesinde ele alınan modellerin oldukça keyfi olması her şeyden önce dikkat çekicidir. Açıklamalarına yönelik doğal bir adım , hafıza süreçlerinin gerçekleştirildiği beynin bu sinirsel mekanizmalarına bir çağrı olmalıdır . Başka bir deyişle, bilişsel enformasyonel yaklaşımın ilerlemesi, belleğin psikofizyolojik analizine doğru bir hareketle ilişkilidir.
O halde bilişsel-bilgisel yaklaşımın önemi nedir? Gerçek şu ki, anlamsal dönüşümler de dahil olmak üzere hafıza süreçlerinin önemli bir kısmı o kadar karmaşık ki, şu anda henüz sinirsel kalıplar temelinde yorumlanamıyor. Bilişsel bilgi yöntemi, bu karmaşık bellek biçimlerinin analizine oldukça etkili bir yaklaşım sağlar.
R. L. Klatsky'nin kitabı hafızanın üç seviyesini tartışıyor: ikonik, kısa vadeli ve uzun vadeli. Uzun süreli belleğin analizinde özel zorluklar ortaya çıkar. Bu seviye, verilerin anlamsal olarak işlenmesini ve bunların genelleştirilmesini içerir. Bununla birlikte, gerçekler, uzun süreli hafızada birçok algı detayının korunmasından bahseder. Yazar, uzun süreli bellekte tam olarak nelerin depolandığı ve belleğin kavramsal yönünün görsel yönüyle nasıl bağlantılı olduğu sorusuna esasen bir yanıt vermemektedir. Bununla birlikte, bunun, bu sorunun incelenmesinde ortaya çıkan gerçek zorlukları yansıttığı vurgulanmalıdır.
Kitap, ayrıntılı olarak açıklanan ve iyi sistematik hale getirilmiş büyük miktarda deneysel malzeme içeriyor. Okuyucu, ikonik ve ekoik bellek gibi, hâlâ çok az incelenmiş bellek biçimleri hakkında yeni olan pek çok şey bulacaktır. Kitap, proaktif ve geriye dönük inhibisyon sorununu ayrıntılı olarak ele alıyor. Bellekte depolanan izler arasındaki "öznel mesafelerin" ölçümüyle ilgili deneylerin açıklaması oldukça ilgi çekicidir. Bu yaklaşım, önde gelen özelliklerden oluşan çok boyutlu bir uzayda noktalar olarak temsil ederek, hafıza izlerinin organizasyon ilkelerini oluşturmayı mümkün kılar. Daha önce duyusal eşiklerin incelenmesinde etkili olan tekniklerin burada kullanılmasıyla, hafıza çalışmasında önemli ilerleme kaydedilmiştir. Bu öncelikle istatistiksel karar verme teorisi için geçerlidir. Tanıma işlemiyle ilgili olarak alıcının çalışma özelliğinin kullanılması, tanıma eyleminde iki niceliği ayırmayı mümkün kıldı: sinyalin bellek izlerinden birine yakınlığı ve karşılık gelmelerine ilişkin kararı belirleyen kriter birbirlerine.
Kitabın sonunda hafızanın bir satranç oyununa katılımı ele alınıyor.
Sonuç olarak, R. Klacki'nin kitabının öğretimin etkililiği konularını da tartıştığı vurgulanmalıdır. Verileri yapılandırmanın ve materyalleri bellekte tutmak için düzenlemenin olumlu etkisine özellikle dikkat çekilmektedir.
Kitap, okuyucuyu yalnızca hafıza sorununun mevcut durumuyla tanıştırmakla kalmıyor, aynı zamanda bu konunun daha fazla araştırılmasını da teşvik ediyor.
E. N. Sokolov
HAFIZAYA ADANMIŞTIR
ARNOLD KLATSKY
Önsöz
Her birimizin bir anısı vardır. Onu o kadar kolay kullanırız ki, kendi bilgi edinme ve onu kullanma becerimize nadiren şaşırırız. Bu arada, insan hafızası çok karmaşık bir şeydir ve psikologlar onu yıllardır incelemelerine rağmen, onun tüm karmaşıklığını yeni yeni anlamaya başlıyorlar. Ancak yine de, son yirmi yılda, insan hafızası üzerine yapılan çalışmaların bir sonucu olarak, karşılık gelen işlevsel sistemin giderek daha net bir resmi oluşturuldu; Bu kitapta anlatmaya çalışacağımız şey, yavaş yavaş ortaya çıkan bu tablodur.
Bellek, burada sürekli olarak bilgi alma, değiştirme, depolama ve geri çağırma ile meşgul olan bir bilgi sistemi olarak kabul edilir. Bu yaklaşımla, algılama ve öğrenme hafıza alanına aittir ve bu nedenle bu kitapta da kısmen tartışılmaktadır. Bellek çalışmalarına katılanların ilgisini çekebilecek tüm konuları kapsamaya çalışmadık, ancak seçtiğimiz konular, bu alandaki mevcut araştırma durumunu ve teorik fikirleri oldukça geniş bir şekilde özetlememize izin veriyor. Önce algıya bakacağız, ardından "kısa süreli bellek" ile ilgili sorulara geçeceğiz ve son olarak anlamsal bellek, kodlama ve geri çağırma kalıpları ve unutmayı içeren "uzun süreli bellek" e bakacağız.
Eleştirmenler bu kitabı yazmamda çok yardımcı oldular. Eleştirel yorumları için Richard Atkinson, Robert Crowder, Douglas Hinzman, Earl Hunt, James Juol, Thomas Landauer ve Edward Smith'e minnettarım. Bu sözler her zaman pohpohlayıcı olmasa da her zaman yardımcı oldu ve kitabın aldığım tavsiyeden yararlandığına inanıyorum. Rehberliği ve yardımı için Buck Rogers'a ve bu kitabın geliştirilmesi boyunca gösterdiği ilgi, destek ve dostluk için Jim Geivitz'e teşekkür etmek istiyorum.
Robert L. Clank
Bölüm 1
giriiş
hatırlamak ne demek? Ünlü psikolog William James'in bir zamanlar dediği gibi, hatırlamak, geçmişte yaşanan ve daha önce hemen düşünmediğimiz bir şeyi düşünmektir (James, 1890). James'in tanımı ilk bakışta başarılı gibi görünse de "hafıza" kavramını tek bir cümleyle tanımlamak o kadar kolay değil.
Bu kitap hafıza problemine adanmıştır. Çevremizdeki dünyaya dair bilgimizi içsel olarak depoladığımız biçimle ilgili soruları tartışır; ihtiyaç duyduğumuzda bu bilgiye nasıl erişiriz; neden onlara her zaman ulaşamıyoruz; yeni bilgileri zaten birikmiş bilgi sistemine nasıl dahil ettiğimiz. Bu soruların her biri, hafıza probleminin bir parçasıdır ve bu kitap, psikologların bu problemi incelerken kullandıkları yöntemlerden bazılarını tartışacaktır. Yol boyunca, her biri bizi ilgilendiren ana soruyla doğrudan ilgili olan bir dizi farklı konu ve fikre değinilecektir: hatırlamak (hatırlamak, hatırlamak) ne anlama gelir?
Bu kitapta benimsenen insan hafızası çalışmasına yönelik yaklaşıma genellikle bilişsel veya bilgisel yaklaşım denir. Benimsediğimiz bilişsel yaklaşımı, çağrışımcılık fikirlerine veya uyaran-tepki teorisine dayanan daha eski, ancak hala modası geçmiş olmayan yaklaşımla karşılaştırırsak, bunun ne anlama geldiğini daha iyi anlayacağız. Bu teoriye göre, hatırlama yeteneği, uyarıcılar ve tepkiler arasındaki çağrışımların veya bağlantıların oluşumunun sonucudur ve hatırlama kolaylığı, bu tür bağlantıların gücüne bağlıdır (alışkanlığın gücü olarak adlandırılır). Yeterince kararlı bir bağlantı ortaya çıktıysa (örneğin, "2x2 =" ve "4" arasındaki bağlantı gibi), güçlü bir bellek izinin varlığından bahsedebiliriz; bu izin türü, içinde yer alan uyaranlara ve reaksiyonlara bağlıdır.
Örneğin, çoğumuz arabayı kırmızı ışıkta durdurmayı hemen hemen her zaman hatırlarız. Bu alışkanlık, belirli bir uyaran (kırmızı ışık) ile belirli bir tepki (frene basma) arasında bir ilişki kurmamıza bağlanabilir. Elbette oldukça basit bir örnek aldık - hemen hemen her hayvan kırmızı ışıkta durmayı öğrenebilir ve bu anlamda bir hafızası vardır. Ancak çağrışımcılar, uyarıcı-tepki teorisinin insan davranışının daha incelikli ve karmaşık biçimlerini de açıklayabileceğini savunuyorlar. Bu, özellikle içsel uyaranların ve tepkilerin, yani doğrudan gözlemlenemeyen (ve bu nedenle kırmızı ışıkta veya fren pedalına basılmış gibi görünmeyen) uyaranların ve tepkilerin var olduğu varsayılarak elde edilebilir. Aslında, bir kişinin çevresindekilere verdiği tepkilerin çoğu muhtemelen içseldir ve eğer dışsal olarak ifade edilirlerse, fark edilemeyecek kadar zayıftırlar. Bu gizli reaksiyonlar, diğer reaksiyonlar için uyarıcı görevi görebilir; bu şekilde, gözlem için erişilemeyen uyaran ve tepki zincirleri ortaya çıkabilir. Bu, teorinin daha karmaşık zihinsel süreçlere genişletilmesine izin verir.
Bununla birlikte, çağrışımcı yaklaşım bir dizi zorlukla karşı karşıyadır. Birincisi, çağrışımcılar, uyarıcı ve tepki arasındaki ilişkinin gerçeğine ve şartlı tepkilerin yasalarına odaklanırlar - çağrışımların nasıl oluştuğunu ve bir becerinin gücünün nasıl düzenlenebileceğini bulmaya çalışırlar. Uyaran ile tepki arasında geçen olaylar hakkında neredeyse hiçbir şey söyleyemezler. İkinci olarak, çağrışımcı yaklaşım bizi pek çok şeyi anlamaya daha fazla yaklaştıramadı: en ilginç fenomenler hafızayla ilgili: hipotezleri nasıl inşa ettiğimiz ve onları nasıl test ettiğimiz hala belirsizliğini koruyor; "dilin ucunda dönüp duran" bir kelimeyi neden bu kadar sık hatırlayamadığımız; tanıdık yüzlerin görüntülerini nasıl hatırladığımız vb.
Bilişsel aktivitenin bir bileşeni olarak hafızayı incelerken, ana vurgu, çağrışımcı yaklaşıma kıyasla önemli ölçüde değişmiştir. Cognitio, yani bilgi kelimesinden gelen "bilişsel" sıfatı, sadece uyaran ve tepkilerden değil, zihinsel süreçlerden bahsettiğimizi vurgular. Bu kayma - uyaranları algılayan ve otomatik olarak "uyarıcı-tepki" zincirleri yaratan pasif bir sistem fikrinden zihinsel aktivite kavramına geçiş - bilişsel hafıza teorilerini karakterize eder. "Bilişsel Psikoloji" adlı kitabında (Neisser, 1967) bu yaklaşımın gelişimine gerçek bir ivme kazandıran Neisser'e göre, bilgi sorunu bilişsel bellek teorisinde merkezi bir yer tutar - bilgiyi edinme, onu değiştirme yolları , onu işlemek, kullanmak, depolamak vb. e "kısaca insan vücudunda işlenme biçimleridir. Dolayısıyla "bilgi işleme" terimi (bilgi psikolojisi ile ilgilenenlerin uzmanlardan ödünç aldığı) bilgisayarlarda) bir kişinin etrafındaki dünya hakkında bilgi ile aktif etkileşiminin tüm yönlerini kapsar Uyaran ve tepki arasında yer alan zihinsel süreçler, bu işleme sürecinde merkezi bir rol oynar. -yanıt" zinciri (ancak daha sonra göreceğimiz gibi, çağrışım kavramı bilişsel psikolojide kendine bir yer bulsa da).
Haber (Haber, 1969), psikolojiye bilgisel yaklaşımın ilişkili olduğu bir dizi temel varsayıma işaret etmiştir. Biraz değiştirilmiş, 1) aşamalı bir bilgi işleme varsayımı ve 2) bilgi işleme süreçlerinin sürekliliği fikrinin takip ettiği ilgili sistemlerin sınırlı kapasitesinin varsayımı olarak formüle edilebilirler.
İlk olarak bu varsayımlardan ilkini ele alalım. "İncelenen sürecin - bazı bilgilerin işlenmesinin - bir dizi alt sürece veya aşamaya bölünebileceğini varsayıyoruz. Başka bir deyişle, uyaran ile tepki arasındaki aralık, her biri daha kısa aralıklara bölünebilir. Bilginin bir aşamadan diğerine geçerken inanılmaz dönüşümler geçirebildiğini nasıl göreceğiz.Kırmızı ışık örneğimize dönersek, tüm süreci aşağıdaki aşamalara ayırabiliriz: birincisi, bizim görsel sistem kırmızı ışığı kaydeder ve ikincisi, belirli bir görsel duyumun gerçekte ne olduğunu tanırız - kırmızı trafik ışığı gibi (bunun için hafızamızda depolanan bilgileri, yani kırmızı trafik ışığının neye benzediği bilgisini kullanmalıyız) ); hafızamıza kaydettiğimiz kuralı uyguluyoruz: “Kırmızı sinyal gördüğünüzde arabayı durdurun.” Tabii istenirse tüm bu süreç evet'e tabi tutulabilir. daha fazla kırma. Ancak açıklanan aşamalarda ilk bilgilerin (görsel: sinyal) ardışık dönüşümlere uğradığına dikkat edin. Görsel bir duyumdan tanınabilir bir kategoriye (kırmızı ışık algısı) dönüştü, ardından tekrar değişti ve belirli bir kuralın uygulanmasını gerektiren bir koşul haline geldi (ne zaman arabayı durdur). Bu örnek genel durumu göstermektedir: bilgi işleme sürecinde bir veya başka bir aşamanın tahsisi keyfi olmamalıdır: bu sürecin her aşaması (bazen işleme düzeyi olarak adlandırılır) genellikle bilginin bir veya daha fazla temsiline karşılık gelir. uyaran aşamayı diğerine taşır, temsili buna göre değişir.
Kırmızı ışık örneği, sistemin bilgi kapasitesi açısından da değerlendirilebilir. Her aşama için, "kişinin bilgi işleme yeteneği üzerinde bilinen sınırlar" oluşturmak mümkündür. Örneğin, kırmızı ışığa bir trafik polisi, birkaç dikkatsiz yaya ve bir ambulans eklersek, o zaman tüm bu uyaranlar tersine dönebilir. görsel sistemin bunları aynı anda kaydedebilmesi için çok fazla olması gerekir. Sonuç olarak, duyusal kayıtta aşırı yüklenme olur ve bu tür bir aşırı yüklenme çeşitli komplikasyonlara yol açabilir. Her şeyden önce, kısım bilgilerin bir kısmı sisteme girmeyebilir (yayalardan birini veya hatta kırmızı ışığı hiç fark etmeyebiliriz). Veya uyaran durumunu yeniden kodlayabiliriz, yani onu yeni bir uyarana dönüştürebiliriz (örneğin, bunu basitçe "tehlikeli bir durum" olarak algılayın.) Son olarak, bilgilerin daha seçici bir şekilde işlenmesi de mümkündür - trafik ışıklarını, yayaları veya ambulansları fark etmeden tüm dikkatimizi trafik kontrolörüne verebiliriz.
Az önce açıklanan iki temel varsayımın önemli bir sonucu, belleğe bir bilgi işleme süreci olarak yaklaşarak, kaçınılmaz olarak psikolojinin genellikle bellek çalışmasından ayrı olan alanlarına girmiş olmamızdır. Örneğin öğrenme şu şekilde görülebilir: insan hafıza sistemini yenileme veya değiştirme süreci. Algı (yani, bir uyaranın ilk kaydı) da bellekten ayrılamaz ve sürekli bir bilgi işleme sürecinde ilk adım olarak görülebilir.
Burada açıklanan yaklaşım neden "bilişsel psikoloji" olarak adlandırılıyor? Bu yaklaşımın bilişsel doğası, daha önce de belirttiğimiz gibi, insan vücudunun aktif olarak bilgi arayan ve bilgiyi işleyen bir sistem olduğu fikrine, yani insanların bilgi üzerinde çeşitli etkilere sahip olduğu fikrine dayanmaktadır. . Örneğin, bilgileri işlerken, bir kişi başka bir forma yeniden kodlanıp kodlanmayacağına karar verebilir, daha fazla işlem için belirli bilgileri seçebilir veya belirli bilgileri sistemden hariç tutabilir. Göreceğimiz gibi, aktif olarak bilgi işleyen bir sistem olarak bir kişi fikri, en son hafıza teorilerinin tümüne nüfuz eder. Hafıza çalışmasına bilişsel yaklaşımın destekçileri, algıyı ve hatırlamayı, bir kişinin aktif olarak etrafındaki dünyanın zihinsel görüntülerini yarattığı yaratıcı eylemler olarak görür.
TEMEL KONSEPTLER
Bellek çalışmalarına geçmeden önce, birkaç temel kavram ve tanım üzerinde anlaşmak gerekir. Sibernetikten ödünç alınan ve insan hafızasının değerlendirilmesine uygulanan üç ana terimi ayırt ederek başlayalım: kodlama, depolama ve bilginin geri alınması. Kodlama, bilgilerin sisteme girilme şeklini ifade eder. Kodlama işlemine, bilginin girileceği sisteme (insan ya da makine) karşılık gelen uygun forma dönüştürülmesi eşlik edebilir (örneğin, bir bilgisayar için bilgi şu şekilde kodlanabilir: standart delikli kartlarda delme delikleri). Depolanan bilgileri kodlama yöntemine genellikle belleğin "kodu" denir. Depolama, kelimenin tam anlamıyla, bilginin bir sistemde depolanması anlamına gelen olağan anlamına karşılık gelir; Elbette hafızada saklanan bilgilere bir şey olabilir: daha sonra gelen bilgilerin etkisi altında değişebilir veya tamamen kaybolabilir. Alma , saklanan bilgilere erişim elde etme eylemidir. Bu üç süreçten herhangi biri şu veya bu nedenle bozulabilir - bir kişide bu, şu veya bu olayı hatırlayamamaya yol açar. Başarılı bir geri çağırma için üç işlemin de sıralı olması gerekir: bilgiyi kodlamalı, ihtiyaç duyulana kadar saklamalı ve sonra tekrar geri getirebilmeliyiz.
Kitapta sıkça karşımıza çıkacak bir diğer terim de "model", özellikle "bellek modeli". Bu teorik modeldir. Dolayısıyla, yukarıda ele alınan örnekle ilgili olarak, bir kişinin kırmızı ışıkta bir arabayı yavaşlattığı sırada meydana gelen zihinsel süreçlerin bir modelini oluşturduğumuzu söyleyebiliriz. Bazen teorik bir model "matematiksel" bir modele dönüşür, yani bizi ilgilendiren süreçleri daha ayrıntılı olarak açıklamak için içine matematik eklenir. Belirli bir zihinsel sürecin bir modelini oluşturmanın avantajlarından biri, modelin davranış yapmanıza izin vermesidir, bu nedenle bu "tahminler insanların gerçek davranışlarıyla karşılaştırılabilir ve hatalı oldukları ortaya çıkarsa, bu yeni bir model oluşturmanız gerektiği anlamına gelir.
LİSTE ÖĞRENME YÖNTEMİ
İnsan hafızasını göz önünde bulundurarak, geleneksel deneysel yöntemlerin kullanıldığı birçok deneyin sonuçlarını anlatacağız. Bu kitapta sadece bu yöntemlere değinmekle kalmayacağız, bir dereceye kadar standart kabul edilebilirler ve birçok deneyde kullanılıyorlar. Tüm bu yöntemlerin ortak bir temeli vardır: her birinde denek (üzerinde deney yapılan kişi) kendisine sunulan elementlerin listelerini ezberler. Bu tür unsurlar, tek kelimeler, kelime çiftleri veya "anlamsız heceler" olabilir. (Anlamsız heceler ayrıca С-Г-С - "ünsüz-ünlü-ünsüz-ünsüz" olarak da adlandırılır; örneğin, DAK, BUP veya LOC kombinasyonlarıdır.) Bir dizi öğe ezberlenir tekrarlanan denemeler yoluyla - denemeler . Her test, özneye bir dizi öğe sunmaktan ve ardından hatırlayabildiği ortaya çıkan yeniden üretmekten oluşur.
Liste öğrenme yöntemi, hatırlama ve unutma süreçlerinin sistematik çalışmasına öncülük eden Hermann Ebbinghaus (1885) tarafından tanıtıldı. Ebbinghaus, bir konuda, kendi üzerinde çok sayıda deney yaptı. Deneylerinde anlamsız heceleri ezberledi. Bu heceleri bulan Ebbinghaus'du; bunu yaptı çünkü kendi bakış açısından istenmeyen bir faktörü - yani anlamı - deneyden çıkarmak istedi . Ebbinghaus, dizisini oluşturmak için gerçek kelimeler kullanırsa, bu kelimelerin anlamının deneylerin sonuçlarını etkileyeceğine inanıyordu. Ve mevcut olanlardan bağımsız olarak yeni çağrışımların oluşumunu ve hafızasında tutulmasını incelemek istedi . Bu istenmeyen "çarpıtma" kaynağından kaçınmak için, herhangi bir anlamsal ilişkiden nispeten bağımsız olduklarını düşünerek anlamsız heceleri kullanmaya karar verdi.
Ebbinghaus, poi'nin kendisine sabit bir hızda sunduğu bir dizi anlamsız hece oluşturdu. Bu dizileri, ezberlemiş gibi görünene kadar okudu ve bazı durumlarda onları hatasız bir şekilde ezberden yeniden üretebiliyordu. Bir süre sonra yine böyle bir kendi kendine muayene yaptı. Unutmanın nicel ölçüsü, belirli bir süre sonra aynı satırları tekrar ezberlemek için gereken ek tekrarların sayısıydı. Bu, öğrenilenlerin hangi kısmının hafızada tutulduğuna karar vermeyi mümkün kıldı.
Ebbinghaus, hafıza çalışmalarına birçok katkı yaptı. Hata kaynaklarını ortadan kaldırmak için yalnızca deneysel yöntemler yaratmadı; bu yöntemleri uygulayarak insan hafızası ve ezberleme süreci hakkında birçok yeni şey keşfetti. Ebbinghaus'un önemli keşiflerinden biri, bir öğe kümesi çok büyük değilse -diyelim ki yalnızca yedi veya daha az öğe içeriyor- o zaman bir okumadan hatırlanabilir. Öğe sayısını sekize veya daha fazlasına çıkarırsanız, ezberleme için gereken süre önemli ölçüde artar. Yedi element düzeyinde, bir tür "ara" vardır - bu seviyenin altında, ezberlemek için bir okuma yeterlidir ve üzerinde, sayısı öğe sayısıyla artan birkaç sunum gereklidir. Sınırlayıcı sayı ( yedi) bir kerede ezberlenen öğelere hafıza miktarı denir ve bunu Bölüm 1'de daha ayrıntılı olarak ele alacağız. 2.
Ebbinghaus'un bir başka önemli keşfi de, bellekte tutulan materyal miktarının, ilk ezberleme ile sonraki doğrulama arasındaki zaman aralığına bağlı olmasıydı. Kısa bir süre için daha büyük olduğu ve zamanla istikrarlı bir şekilde azaldığı, yani unutulan malzeme miktarının zamanla arttığı ortaya çıktı. Unutma eğrisi, şek. 1.1. İlk birkaç dakikada unutmanın çok hızlı gerçekleştiği (yani, tutulan materyal miktarının hızla azaldığı), ancak yavaş yavaş unutma oranının düştüğü görülmektedir.
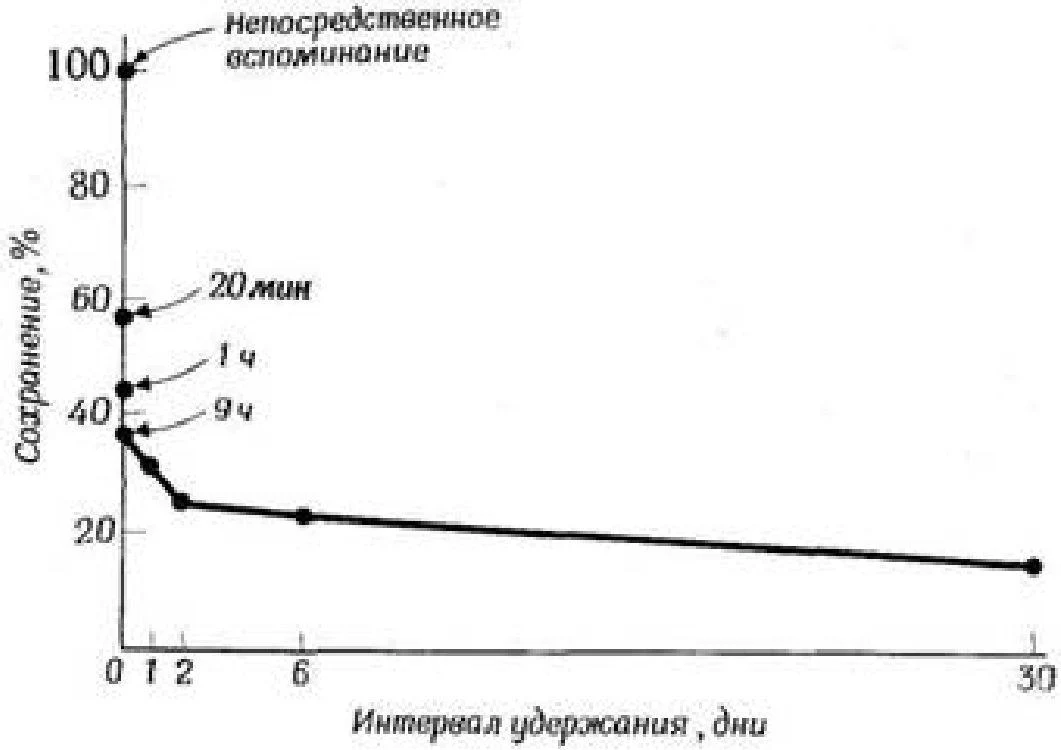
Pirinç. ].!. Evbngause'nin unutma eğrisi [Ebblnglibus, 10fi5>, mi Ordinat'a göre - listede tutulan anlamsız hecelerin sayısı ve apsis eksenine kadar - tutma aralığı, yani ilk ezberleme ile kontrol yeniden üretimi arasındaki süre
Ebbinghaus tarafından geliştirilen orijinal yöntem, şimdi sıralı öğrenme yöntemi olarak adlandırılan yönteme benzer. Bu yöntemle denek, belirli bir sıraya göre düzenlenmiş bir dizi öğeyi ezberlemelidir. Örneğin, sıramızın çok küçük olduğunu varsayalım - KİTAP BORUSU, KONİ, KURULU, LEVHALAR. Bu beş kelime özneye sunulur ve ardından bunları aynı sırayla tekrar etmesi gerekir. Sözcüklerden birini unutur veya yanlış yerde söylerse bu hata sayılır.
Dizilerin ezberlenmesi iki şekilde test edilebilir. Bunun bir yolu, özneye tüm diziyle birlikte sunulması ve ardından onu ne kadar iyi hatırladığı kontrol edilmesidir. Bu yönteme ezberleme-yeniden üretme yöntemi denir , çünkü denek önce bir dizi öğeyi ezberler ve ardından tüm dizi için bir bütün olarak test edilir. Diğer bir yöntem ise tahmin yöntemi olarak adlandırılır . Bu yöntemle denek, serinin tamamını bir kerede ezberleyip sonra bütünü ile yeniden üretmeye çalışmak yerine, öğeleri birbiri ardına yeniden üretir ve ezberler. Bunu yapmak için, her öğeyi görmeden önce adlandırmaya çalışması önerilir. İlk olarak, kendisine satırın başlangıcını gösteren bir tür işaret (örneğin bir yıldız işareti) sunulur. İşaretçiyi gördükten sonra denek, dizinin ilk öğesini adlandırmaya çalışır (bu, ilk öğe için bir testtir). Daha sonra özneye birinci öğe sunulur (ezberleme) ve ikinci öğeyi adlandırmaya çalışır (ikinci öğeyi kontrol edin) ve bu dizi boyunca böyle devam eder. Denek ilk kez, elbette, neredeyse kesinlikle herhangi bir öğeyi adlandıramayacak, ancak sonunda, birkaç denemeden sonra, görevle iyi bir şekilde başa çıkmaya başlayacaktır.
Dizilerin ezberlenmesini birçok faktörün etkilediği tespit edilmiştir. Bunlardan biri, öğelerin sunum hızıdır (hatırladığınız gibi Ebbinghaus, bunları sabit bir hızda sunmuştur). Genellikle, daha düşük sunum hızlarında ezberleme daha hızlı gerçekleşir. Dizileri ezberlemenin bir diğer önemli özelliği de, belirli bir öğeyi hatırlama kolaylığının dizideki yerine bağlı olmasıdır (yani, birinci öğe mi, ikinci öğe mi olacağına bağlıdır). Serinin orta elemanlarının çoğaltılmasındaki hata sayısı, ilk veya son elemanlara göre daha fazladır. Bu etki, konumsal etki (seri konum etkisi) olarak adlandırılır ve bellek miktarını aşan herhangi bir uzunluktaki satırlar için oluşur.
Bellek deneylerinde sıklıkla kullanılan diğer bir yöntem , her bir öğenin iki parçadan oluşan bir kompleks olma özelliğine sahip olan çift ilişkilendirme yöntemidir . Örneğin, bir eleman bir kelime ve bir sayıdan oluşabilir ("KİTAP-7" deyin). Bu tür çiftleri ezberledikten sonra, özne, kendisine birinci sunulduğunda öğenin ikinci bölümünü adlandırmalıdır ("KİTAP" kelimesini "7" ile yanıtlar). Genellikle, ikili ilişkilendirme yöntemiyle, öğeler belirli bir sırayla ezberlenmez. Bir örnekten diğerine sıraları değişebilir, ancak çiftlerin kendileri sabit kalır. Örneğin, bir örnekte BOOK-7 ve DOG-8 elementleri birbirini takip edebilir ve diğerinde birkaç başka elementle ayrılabilirler; ancak, KİTAP her zaman 7 ile ve DOG ile 8 ile gider.
Basit bir öğe dizisinin yanı sıra, eşleştirilmiş kombinasyonların bir listesi, öğrenme-yeniden üretme yöntemi veya tahmin yöntemi kullanılarak öğrenilebilir. İlk durumda, önce tüm öğeler sunulur ve ardından ezberlenmeleri kontrol edilir. Doğrulama genellikle öğelerin yalnızca ilk kısımlarını sunmaktan oluşur ve denek cevabında ikinci kısımlarını adlandırmaya çalışır. Örneğin, deneyi yapan kişi "KİTAP-?" sunar ve denek "7" yanıtını verir. Beklenti yönteminde (ezberleme dizilerinde olduğu gibi), özneden sunumundan önce bir öğeyi adlandırması istenir, ardından bu öğe sunulur gptri prgd lig yut, "başka bir öğe söyle, ardından sunulur, vb. burada çoğaltma ezberden önce gelir.Örneğin konu "KİTAP-?" "vb.
Çift ilişkilendirme yönteminin varsayılan avantajlarından biri, bir unsurun hem uyarıcı (ilk kısım) hem de tepki (ikinci kısım) olarak düşünülebilmesidir. Bazı teorisyenlere göre bu yöntem, uyarıcı ve tepki arasındaki ilişkileri doğrudan incelemeyi mümkün kılar. Bununla birlikte, belirli bir öğenin ezberlenmesinin, henüz uyaran ve tepki arasında basit bir bağlantının kurulmasının kanıtı olarak kabul edilemeyeceğini göreceğiz. Özneler genellikle, öğeleri kendilerine özgü bir şekilde değiştirmelerinden oluşan arabuluculuğun bir sonucu olarak bir öğeyi ezberlerler . Örneğin, "CAT AM" öğesi zihinsel olarak "KEDİ VE FARE" ye dönüştürülebilir. Bu durumda, hatırlanan şey doğrudan "KOTIK A-M" çağrışımının içerdiğinden tamamen farklıdır.
Üçüncü yöntem ücretsiz hatırlamadır. Serbest hatırlamada, dizilerin yeniden üretilmesinin aksine, denek öğeleri herhangi bir sırayla adlandırabilir. Birkaç örnekte aynı eleman dizisi kullanılıyorsa, sunum sırası her seferinde değişir. (Serbest hatırlama ile ilgili deneyler genellikle ezberleme-kontrol yeniden üretimi ile gerçekleştirilir, çünkü tahmin yöntemi kaçınılmaz olarak serinin öğelerinin adlandırılması gereken sırayı sabitler, yani serbest hatırlama sırasında istenmeyen olanı tam olarak ortaya koyar.)
Dizilerin çoğaltılmasında olduğu gibi, serbest hatırlama ile konumsal bir etki gözlenir (Şekil 1.2), yani bir satırın başında ve sonunda bulunan öğeler, bir satırın ortasında bulunan öğelere göre nispeten daha sık geri çağrılır. Şek. 1.2, belirli bir öğenin arka arkaya yerine başarılı çoğaltma sayısının bağımlılık eğrisinin farklı bölümlerinin özel adları vardır. Serinin ilk öğelerine karşılık gelen eğrinin yukarı doğru sapmasına başlangıç etkisi, son birkaç öğeye karşılık gelen sapmasına ise bitiş etkisi denir.

Rle. 1.İ, Zavyasnmaet İslam frekansları інізті ня Menent yerinden Serbest hatırlama ile <4 izzet listesinde ( Murdock'a göre, 1962). Zapіtrvkhoyannye alanları, sallanma etkisinin (A) sonun (B) etkisine tezahür ettiği alanlara karşılık gelir.
Dizi ezberleme ile ilgili bir diğer yöntem de tanıma testidir . Bu yöntem, doğrulama biçiminde diğerlerinden farklıdır. Konuya ezberlediği kelimelerden çeşitli kelimeler sunulur ve bunları orijinal dizinin unsurları olarak tanıyıp tanımadığı sorulur. Bu nedenle, tanıma yöntemi, test sırasında özneye bunları hatırlamasının istenmesi yerine belirli sayıda öğenin yeniden sunulması gerçeğiyle karakterize edilir. Tabii sadece ezberlenen listede yer alan unsurlar kendisine sunulsa, o zaman her seferinde “Evet, öyleydi” diyebilir ve hata yapmaz. Listede yer alan öğeleri tanıma yeteneğini gerçekten test etmek için, test öğelerinin sayısına sözde çeldiricileri - orijinal listede olmayan öğeleri dahil etmek gerekir.
Konu, örneğin evet-hayır yöntemiyle kontrol edilebilir. Birbiri ardına bir dizi öğe sunulur ve kendisine göre bu öğe zaten listedeyse "evet" veya ona bu öğe listede yokmuş gibi görünüyorsa "hayır" demelidir. liste. Genellikle sunulan öğelerin yarısı listede yer alan öğeler, diğer yarısı ise çeldiricilerdir. Evet-hayır yöntemi, okullarda kullanılan doğru-yanlış yöntemine benzer .
Tanıma testinin bir başka biçimi de zorunlu seçim yöntemidir. Bu yöntemle konu her seferinde bir değil, aynı anda iki veya daha fazla öğe sunulur. Bunlardan biri orijinal listedeydi ve geri kalanı orada değildi. Konu, listedeki öğeyi seçmelidir. Konuya iki öğe sunulursa, "iki alternatifli zorunlu seçim", üç öğe sunulursa, ardından "üç alternatifli" bir seçim vb. Fark etmiş olabileceğiniz gibi, zorunlu seçim yöntemi, çoktan seçmeli yöntemin bir çeşididir.
Son olarak, deneğe her şeyi, yani listedeki tüm kelimeleri ve tüm çeldiricileri bir kerede sunarak bir tanıma testi yapılabilir. Bu durumda denek, orijinal listede hangi kelimelerin yer aldığını belirtmeye çalışır. Çoğu zaman, böyle bir çekte kullanılan tüm unsurlar bir kağıda basılır ve kişiden kendisine göre listede yer alan kelimelerin altını çizmesi istenir.
Tanıma testinin bazen yukarıda açıklanan diğer yöntemlerle birlikte kullanıldığını not etmek önemlidir. Örneğin, süjeye her çiftin bir uyaran görevi gören bir üyesi ve bir tepki görevi görebilecek birkaç üye eşlik ederek sunarak çift ilişkilendirme yöntemiyle birleştirilebilir. Örneğin, daha önce bir DAK-7 öğesi sunulan bir özne, doğrulama sırasında sunulabilir.
DAK-? 5 8 7 1 (birini seçin) .
Tanıma testi ayrıca dizi ezberleme ile birleştirilebilir. Bu durumda, özneden kendisine sunulan sıraların kedisinde öğelerin daha önce sunuldukları sırayla yer aldığını belirtmesini isteyebilirsiniz.
Bu nedenle, listeleri ezberlemek için temel prosedürler aşağıdaki gibi tanımlanabilir:
Bir diziyi ezberlerken, öğeler belirli bir sırayla ezberlenir.
Eşli ilişkilendirmeleri ezberlerken, listedeki öğeler çiftler halinde düzenlenir.
Ücretsiz geri çağırma ile listenin öğeleri herhangi bir sırayla adlandırılabilir.
Tanıma kontrolü yapılırken özneye belirli bir öğe grubu sunulur.
Dizileri ezberleme yöntemine gelince, bu kitapta buna pek değinmeyeceğiz, ancak diğer tüm yöntemler bizi ilgilendiren konuları incelemede önemli bir rol oynamaktadır. Örneğin, çift ilişkilendirme görevleri unutma çalışmasında büyük önem taşır (Bölüm 9); serbest hatırlama yöntemi, belleğin organizasyonuyla ilgili deneylerde yaygın olarak kullanılır (Bölüm 10) ve tanıma görevleri, bilgi çıkarma teorilerinin değerlendirilmesinde önemli bir yer tutar (Bölüm 11).
Bölüm 2
İnsan bilgi işleme sistemine genel bakış
Birinci bölümde, insan hafızası bilgiyi işleyen bir sistem olarak nitelendirildi; böyle bir sistemin iki önemli özelliği not edildi: 1) bilgi işlemeyi birkaç aşamaya ayırma yeteneği ve 2) sınırlı miktarda bilgi her aşamada işlenir. Bu bölümde, insan bilgi işleme sistemini daha ayrıntılı olarak ele alacağız. Bu sistemin olası bir teorik modeli önerilecektir. Daha sonraki bölümlerde, bu birincil model büyük ölçüde genişletilecektir, ancak şimdilik sistem hakkında genel bir fikir edinmek bizim için önemlidir.
SİSTEM VE BİLEŞENLERİ
İnsanlardaki bilgileri işleyen bir sistemin olası modellerinden biri Şekil 1'de gösterilmektedir. 2.1. Burada sunulan şema, sistemden geçerken "gerçek dünya"dan alınan herhangi bir uyaran hakkındaki bilgilere ne olduğunu genel terimlerle yansıtır.
İlk aşamada, bir uyaranın sunumundan hemen sonra, bu uyaranla ilgili (sistemin dışında henüz ortaya çıkan) bilinen bilgiler kaydedilir veya sisteme girilir. Bu kaydın gerçekleştiği yere "duyusal kayıt" diyeceğiz. Bu isim, bilginin kişinin sahip olduğu beş duyu organından biri (veya birkaçı) aracılığıyla sisteme girmesi ve kısa bir süre duyusal formda saklanması (örneğin, sesin işitsel bir sinyal şeklinde olması) gerçeğini yansıtır; bu nedenle, duyu organlarının her birinin kendi duyusal kaydı vardır. Bilgi bir süre böyle bir kayıtta kalabilir, ancak orada ne kadar uzun süre kalırsa iz o kadar zayıflar ve sonunda tamamen kaybolana kadar. Duyusal izin bu kademeli zayıflamasına sönümleme denir ve bu aşamada sistemin kapasitesini sınırlayan da budur - izin sicilde solmadan saklanabileceği süreyi sınırlar.
İnsan hafıza sistemi

Pirinç. 2.1. che.іchAyk'ta і'nfchriacip işleme sisteminin modeli,
Bilgiler duyusal kayıttayken bir takım önemli işlemler devreye girer. Birincisi , duyusal kayıtta tutulan bilgi ile geçmişte birikmiş bilgi arasındaki temastan kaynaklanan karmaşık bir süreç olan örüntü tanımadır . Bir görüntü, duyusal özelliklerinin bazı belirli kavramlara uygunluğunu şu ya da bu şekilde kurmak mümkünse, tanınmış olarak kabul edilir. Daha dar anlamda, "örnek tanıma" adlandırma anlamına gelir. Uyarana belirli bir ad verirsek, örneğin "A harfi", o zaman bu, belirli görsel bilgileri algıladığımız anlamına gelir - (uyaranın iki kenarı tabanının ötesine uzanan bir ikizkenar üçgen olduğunu belirledik) ) ve bizim bildiğimiz kavramla ("a harfi") karşılaştırdı. Bununla birlikte, örüntü tanıma her zaman adlandırma anlamına gelmez (bazı örüntüleri adlandırmadan tanıyabiliriz); bu nedenle, örüntü tanımayı daha genel anlamda - belirli bir uyarana belirli bir anlam atamak olarak - anlamak daha iyidir.
ile yakından ilgili olan, dikkat adı verilen başka bir süreçtir . Bilişsel süreçlerin psikolojisindeki "dikkat" kelimesinin birkaç anlamı vardır. "Bekliyor" anlamına gelebilir - örneğin, bir telefon aramasını beklerken dinlediğinizde. Bu kelimenin başka bir anlamı basitçe "kapasite"dir (bilgi kanalları): bazı uyaranlara "dikkat vermek" bazen basitçe "sistemin mevcut sınırlı kapasitesinin bir kısmını ona ayırmak" anlamına gelir. "Dikkat" kelimesi, belirli bir şeye odaklanma eğiliminde olduğumuz ve dikkatimizin dağılmaması durumunda, bazı bilgilere özel bir vurgu anlamına da gelebilir. (Örneğin, dersinde yer alan önemli bilgileri kaçırmak istemiyorsanız, dikkatinizi öğretmenin söylediklerine odaklamalısınız.) Genellikle "seçici dikkat" olarak adlandırılan bu son tür dikkattir. bizi en çok ilgilendiren
Sisteme giren giriş sinyalleri, tanındıktan ve dikkat nesnesi haline geldikten sonra (onları ayarladık), bir sonraki işleme aşamasına geçebilirler. Bu aşamada, bilgi kısa bir süre için kısa süreli bellekte (ST) saklanır - duyusal kayıtlardan birinde tutulduğu gibi, artık orijinalinde olmaması farkıyla, yani. duyusal, biçim Örneğin, CP'de A harfi artık tanınmayan bir görsel uyaran olarak değil, A harfi olarak sunulur. Görsel kayıtta iz, yaklaşık bir saniye içinde oldukça hızlı bir şekilde kaybolurken, CP'de "tekrar" adı verilen bir işlemle süresiz olarak tutulabilir. Tekrar, bilgilerin CP'den tekrar tekrar geçmesini mümkün kılar; aynı zamanda bilgiler yenilenir ve tamamen yok olması gerçekleşmez. Ancak böyle bir tekrar olmadan CP'de yer alan bilgi duyusal kayıtta kaybolduğu gibi kaybolur ve bu da sistemin kapasitesini sınırlar. Aslında, kısa süreli belleğin iki sınırlaması vardır: tekrar yoluyla CP'de aynı anda tutulabilen uyaranların sayısı ve belirli bir birimin CP'de tekrar olmaksızın tutulabileceği süre . CP'den bilgi kaybı, "unutma" türlerinden biridir ("unutma" terimi, bellek sisteminin herhangi bir bölümünden bilgi kaybı anlamına gelir).
Son olarak, CP'den gelen bilgiler, sistemin neredeyse süresiz olarak depolanabileceği daha derin seviyelerine, sözde uzun süreli belleğe (LT) aktarılabilir. Uzun süreli bellekte büyük miktarda çok çeşitli bilgi depolanır: her türlü kelimenin anlamı; önceki gün yaşanan olaylar; tanıdığımız kişilerin isimleri; sıradan nesnelerin isimleri; gramer kuralları vb. Özünde, çevremizdeki dünya hakkında bildiğimiz her şeyi içerir.
Hafıza sisteminin bu kısa tanımından, çok farklı iki şeyle uğraşmamız gerektiği açıkça görülüyor. Bir yandan bilgi depoları var - duyusal kayıtlar, KP ve DP; sistemin kendisinin, yapısal bileşenlerinin ayrılmaz parçalarıdır. Öte yandan uyaran dikkati, uyaran tanıma, bilginin tekrarı gibi süreçlerden bahsetmiştik. Sistemin bu yönleri, yapısının bir parçası olarak değil, bir uyarandan diğerine değişen süreçler olarak görülmelidir. Bu süreçler bilgi akışını düzenlemek için kullanıldıklarından, kontrol süreçleri veya düzenleyici süreçler olarak adlandırılırlar (Atkinson ve Shiffrin, 1968'e göre).
Biraz geriye gidelim. Gerçek dünyadan gelen bilgilerin hareketini hafızamızın en ücra köşelerine kadar takip ettik ama son derece karmaşık bir sistemin sadece birkaç kilit noktasına değindik. Bu sistemi incelemeye devam etmeden önce, bahsettiğimiz yapısal bileşenlerin ve süreçlerin her birini daha ayrıntılı olarak ele alalım.
SENSÖR KAYITLARI
Önce duyusal kayıtlarla ilgilenelim. Görme organı aracılığıyla alınan uyaranları algılayan görsel kayıttan daha önce bahsetmiştik. Diğer dört duyu için de kayıtlar olduğunu varsayıyoruz: işitme, dokunma, koku alma ve tatma. Psikologlar en çok iki kayda dikkat ettiler: Neisser'in (1967) "ikonik hafıza" olarak adlandırdığı görsel kayıt ve bizim (yine Neisser'in ardından) "ekoik hafıza" olarak adlandıracağımız işitsel kayıt.
Kural olarak, duyusal kayıt, uyaran hakkındaki bilgileri, başlangıçta sunulduğu bireysel, belirli biçimde kısaca tutmaya yarar; daha sonra bu bilgi, daha fazla iletileceği yeni bir forma dönüştürülebilir. Daha önce de belirtildiği gibi, duyusal kayıtta, iz burada hızla kaybolduğu için bilgi zaten çok kısa bir süre kalır. Ek olarak, yeni bilgilerin girilmesi sonucunda duyusal kayıttan bilgi kaldırılabilir ("silinebilir"). Bunun neden gerekli olduğunu görmek kolaydır: Örneğin, ikonik iz (görsel kayıttaki) bu şekilde "silinmemiş" olsaydı, o zaman sürekli olarak üst üste binen birkaç görsel görüntü görürdük ve ayrı resimler görmezdik.
DİKKAT VE DESEN TANIMA
Bilginin sistemin daha derin seviyelerine aktarılmasından, iki önemli düzenleyici süreç sorumludur - daha önce duyusal kayıt ile kısa süreli hafıza arasında bir aşama olarak sunduğumuz örüntü tanıma ve dikkat (bu temsilin olduğunu daha sonra göreceğiz) tamamen doğru değil). Seçici dikkatin işlevi nedir? Bu sorunun cevabı, sistemin bilgi işleme yeteneğinin sınırlı olduğu varsayımından kaynaklanmaktadır. Herhangi bir anda, duyularımız büyük miktarda bilgi alır. Bu satırları okurken görsel uyarılar alıyorsunuz; aynı zamanda dokunma duyusu size bir şeyin üzerine oturduğunuzu (veya ayakta durduğunuzu) ve parmaklarınızın bu kitaba dokunduğunu bildirir; ek olarak, tabii ki ses geçirmez bir odada değilseniz, muhtemelen bazı sesler duyarsınız. Tüm bu bilgilerin bir kısmı önemlidir ve geri kalanı değildir. .Dikkatin seçiciliği, doğru bilgiye odaklanmamızı, ona odaklanmamızı ve diğer her şeyi bir kenara atmamızı sağlar. Bu nedenle, dikkatin seçiciliği nedeniyle, sisteme yalnızca sınırlı kapasite ile önemli bilgiler girer ve eskimiş bilgiler girmez (aksi takdirde önemli bilgiler kaybolur).
Dikkatin seçiciliği, genellikle "parti fenomeni" olarak bilinen aşağıdaki örnekte gösterilmektedir. Bir partide olduğunuzu ve ilginç bir sohbete daldığınızı hayal edin. Aniden, başka bir konuk grubundan birinin adınızı söylediğini duyarsınız. Dikkatinizi hızla bu konuklar arasında geçen sohbete çevirirsiniz ve kendinizle ilgili çok ilginç bir şey duyarsınız. Ancak bu arada, daha önce yaptığınız sohbetin başlığını kaçırdınız. Seçici dikkat yoluyla, Grup 2'ye uyum sağlayabilirsiniz, ancak bunu yalnızca Grup 1 pahasına yapabilirsiniz.
Bahsettiğimiz bir diğer önemli konu da örüntü tanıma, yani gelen duyusal verilerin daha önce edinilmiş ve uzun süreli bellekte depolanan bilgilerle karşılaştırılmasıdır. Bu sürecin amacını anlamak zor değil. Sistem için görece yararsız olan "ham" bilgiyi (örneğin, görsel veya sesli uyaranların bazı kombinasyonları) anlamlı bir şeye dönüştürmekten oluşur. Örneğin, belirli bir uyaran için gerekli olmasa da belirli bir ad bulunabilir. Örüntü tanımanın önemi de oldukça açıktır. Gelen görsel bilgileri "ayı" olarak etiketlemek yerine yanlışlıkla "at" başlığı altında etiketlerseniz neler olabileceğini bir düşünün. Tanıma sisteminde böyle bir hata ölümcül olabilir.
Örüntü tanıma basit bir mesele değildir. Oldukça basit bir örneği ele alalım. Günlük yaşamda, sürekli olarak çok çeşitli el yazısı, basılı ve bazen karalanmış harflerle karşı karşıyayız. Onları tüm olası stil ve boyutlarda tanımayı nasıl başarabiliriz? Bu görev o kadar zor ki, hiç kimse bununla başa çıkabilecek, örneğin mektuplardaki adresleri okuyabilecek bir makine yapmayı başaramadı. Böyle bir makine tasarlayabilen herkes bir servet kazanacaktır, çünkü örüntü tanımanın artık insanlar tarafından yapılması gerekmektedir (banka veznedarları, postanedeki tasnifçiler vb.). Onları tanımak çok zordur çünkü aynı görüntü birçok farklı konfigürasyonla temsil edilebilir. Örneğin A harfi YLn a olarak da gösterilebilir . Ayrıca aynı stille bir harf farklı bir boyuta sahip olabilir veya farklı bir şekilde konumlandırılabilir: A, A, ^ Bir kişinin daha önce hiç görmediği tamamen yeni harf stillerini bile neden tanıdığını açıklamak daha da zordur, çünkü örnek! Aslında, çoğu durumda, elle çizilen harfler yalnızca yeni değil, aynı zamanda benzersizdir; muhtemelen her biri diğerinden farklıdır. Buradan, aynı kategoriye ait olarak tanınması gereken farklı figürlerin sayısının neredeyse sonsuz olduğu ve örüntülerin makine tarafından tanınması görevini bu kadar zorlaştıran şeyin bu ezici çeşitlilik olduğu görülebilir.
KIRMIZI GEÇİCİ HAFIZA
Bu örüntünün tanınması, nasıl yapılırsa yapılsın (bu konuya daha sonra döneceğiz), elde edilen bilginin birincil, anlık veya işleyen bellek olarak da adlandırılan kısa süreli belleğe (ST) gönderilebileceği anlamına gelir. SP esas olarak sözlü materyaller üzerinde çalışıldı - harfler, kelimeler vb. Bu nedenle, bu bilgi deposu hakkındaki bilgilerimizin çoğu özellikle sözlü materyallerle ilgilidir. Örneğin, sözel olarak kodlanmış bir öğenin (yani, bir sözcük olarak sunulan bir öğe, bir harf kombinasyonu, vb.) 30 saniyeden daha kısa bir süre tekrarlanmadan CP'de tutulduğuna ve CP'nin aynı anda yaklaşık olarak tutabileceğine inanılmaktadır. 5-6 gibi elemanlar. Tekrarlama kendi içinde KP'nin doğasında var olan son derece ilginç bir olgudur. Bazı teorisyenler, tekrar sürecinin, hatırlanacak öğenin adının "kendi kendine" tekrarlanan sessiz telaffuzuna benzer olduğuna ve her tekrarın, aynı öğenin CP'ye ilk girişiyle aynı işleve sahip olduğuna inanırlar, yani. öğenin belleğe güvenli ve sağlam bir şekilde döndürülmesi. Burada içsel konuşmanın gerçekleşip gerçekleşmediği sorusu yanıtsız kalsa da, görünüşe göre tekrar, SP'deki unsurları korumak için kullanılıyor. Tekrarın bir diğer işlevi de bilgilerin uzun süreli belleğe aktarılmasıdır. Daha fazla bilgi tekrarlandıkça ve CP'de ne kadar uzun süre tutulursa, gelecekte hatırlanma olasılığının o kadar yüksek olduğu öne sürülmüştür (örneğin bkz. Atkinson a. Shiffrin, 1968). Bu, esas olarak, tekrarlama sürecinin, daha sonra hatırlamanın daha kolay olması için DP'deki bilgilerin düzeltilmesine yardımcı olabileceği anlamına gelir.
Kısa süreli belleğin bir özelliği daha sıklıkla not edilir - kelimelerin görüntüleri burada görsel olarak değil, işitsel bir biçimde tutulur. Verilen kelime görsel bir görüntü ile sisteme girilse bile bu oluyor. Bu, CP'de depolanan bilgilerin yetersiz çoğaltılmasının bir sonucu olarak, yanlış bir yanıt verildiğinde (böyle bir yanıta "karıştırma hatası" denir, çünkü CP'de olmayan bilgiler CP ile karıştırılmıştır. oraya girilen bilgiler), özne genellikle ses olarak benzer olan ve görünüşte olmayan öğeleri karıştırır (Conrad, 1964). Örneğin, kendisine görsel olarak sunulan ve CP'ye giren V harfini hatırlaması gerekiyorsa, bir hata durumunda X yerine B harfini adlandıracaktır, çünkü B ve V ses bakımından benzerdir, X harfi görünüş olarak v'de daha benzer olmasına rağmen.
UZUN SÜRELİ HAFIZA
Son derece karmaşık bir bilgi depolama sistemi olan uzun süreli bellek, genellikle uzun listeler şeklinde sunulan sözlü materyallerde de kapsamlı bir şekilde incelenmiştir. Göreceğimiz gibi, bu yaklaşım bir dizi son derece önemli sonuç elde etmemizi sağladı, ancak aynı zamanda kusursuz sayılamaz. Ne de olsa, kelime listelerini hatırlamak, bir sohbeti, bir yemek tarifini veya bir film olay örgüsünü hatırlamaktan hala biraz farklıdır. Son zamanlarda, sadece tek tek kelimeler değil, anlamlı dilsel yapılar ezberlendiğinde, tutarlı sözlü materyalin özümsenmesi sürecinde DP'nin işlevini incelemeye başladılar. Bu tür materyalleri kullanarak hafıza çalışması, DP'nin günlük yaşamdaki faaliyetleri hakkında çok daha fazla bilgi sağlar.
DP ile ilgili olarak bahsetmeyi hak eden birkaç önemli hipotez öne sürülmüştür. Onlardan biri. kısa süreli hafıza ve duyusal kayıtların aksine, bilgi DP'de süresiz olarak saklanır. Ama eğer bu hipotez doğruysa, o zaman neden şimdiye kadar bildiğimiz her şeyi hatırlayamıyoruz? Bu hipotezin destekçileri, unutmanın gerekli bilgileri çıkaramamaktan kaynaklandığına inanıyor - orada, ancak ona ulaşamıyoruz.
LTP ile ilgili bir başka ilginç hipotez, bilginin farklı şekillerde - işitsel, görsel veya anlamsal (anlamsal) biçimde - kodlanabileceği hipotezidir. Örneğin, uzun süreli hafızam yaklaşan bir trenin gürültüsü hakkında bilgi içermelidir çünkü bu gürültüyü duyduğumda tanırım. Kız kardeşimin görüntüsü de DP'de saklanıyor çünkü onu tanıştığımızda tanıyorum. DP ayrıca yaşadığım şehrin adını da kaydetmeli, böylece istenirse adını verebilirim.
DP sisteminin ne kadar karmaşık olması gerektiğini anlamak için, çevremizdeki dünya hakkında bildiğimiz her şeyin ona kaydedildiğini anlamanız gerekir. George Washington asla yalan söylemedi; köpekler yaşamak için yemelidir; ayaklara ayakkabı vb. giyilir. Bu büyük miktarda bilgi yalnızca DP'de depolanmaz, aynı zamanda öğelerinin her birine ve dahası birçok yoldan erişilebilir. Örnek olarak "gülümseme" kelimesini ele alalım. Buna giden yol, tanımında yatıyor olabilir: "Bir kişinin mutlu olduğu zaman ağzının ana hatları için kelimeyi adlandırın." Onu da çoğaltabiliriz
bu geminin bayrağı!" satırındaki boşluğu dolduruyor . Daha birçok yol var
bizi bu söze götürecektir.
Genel olarak, DP'deki bilgiler, görünüşe göre çıkarılması nispeten kolay olacak şekilde yerleştirilmiştir. Bazı bilgiler alırsak (örneğin, "gülümseme" kelimesini duyarız), o zaman çok zorlanmadan DP'de onunla ilişkili diğer bilgilerin depolandığı yeri buluruz ("içeriğe göre adresleme" adı verilen bir hafıza özelliği ve şu anlama gelir: içeriğinin önemli bir kısmına sahipsek, bu bilgilerin yerini veya adresini bulabiliriz). Dahası, DP'de bu tür bilgileri çok hızlı buluyoruz ve bu hız, ilk olarak, çıkarmanın bir tür rastgele, yönlendirilmemiş süreç olmadığını ve ikinci olarak, DP'nin oldukça düzenli bir sistem olduğunu gösteriyor.
Bu, insan bilgi işleme sistemine genel bakışımızı sonlandırıyor, ancak açıklanan modeli herhangi bir çekince olmadan kabul edemeyiz. Bu ön modelin birçok düzeltmeye ihtiyaç duyduğunu sonraki bölümlerde göreceğiz. Ancak bu aşamada, konunun bir yönünü, KP ile DP arasındaki ayrım sorununu açıklığa kavuşturmak özellikle önemlidir.
BELLEĞİN İKİLİLİK TEORİSİ.
BİR HAFIZA MI, İKİ mi?
Modelimize göre, bellek sisteminde bilgi duyusal kayıtlarda, CP'de ve DP'de saklanabilir. Bu üç tür bilgi depolama arasında ayrım yapmak için hem mantıksal hem de ampirik gerekçeler vardır. Örneğin, duyusal kayıtların varlığına ilişkin hipotez lehine argümanlar bulmak zor değildir, çünkü bellek sisteminde duyulardan alınan bilgilerin birincil anlamı olana kadar tutulabileceği bazı yerler olması gerektiği açıktır. tanındı. Bu tür kayıtların varlığı, deneysel verilerle de kanıtlanmaktadır. (Bu verilerin çoğu nispeten yenidir ve Bölüm 3'te ele alınacaktır.)
Bununla birlikte, duyusal kaydın üzerindeki alt sistemin CP ve DP olmak üzere iki depoya bölündüğü teorisi ("ikilik teorisi"), bazı teorisyenler tarafından daha az kabul görmektedir. Bu nedenle, önce bu teori lehine bir takım önemli verileri ele alacağız, ardından eksikliklerini ve bazı alternatif teorik yaklaşımları tartışacağız.
Dualite teorisini desteklemek için alıntılanan bir dizi veri fizyolojik niteliktedir. 1959'da Brenda Milner, hipokampusun hasar görmesinden sonra gözlemlenen bir dizi patolojik olayı tanımladı. Bu fenomenlerin kombinasyonu "Milner sendromu" olarak adlandırılmaya başlandı. Milner sendromlu bir kişi, uzak geçmişte - beyni hasar görmeden önce - meydana gelen olayları hatırlasa da, son olayları hatırlayamıyor gibi görünmektedir. Hipokampusun hasar görmesinden önce edindiği bilgi ve becerileri korur. Ayrıca bilgiyi kendisine sunulduktan hemen sonra hatırlayabilir: kendisine söyleneni tekrarlayabilir ve hatta defalarca tekrar etme fırsatı verilirse materyali birkaç dakika hafızasında tutabilir. kesintisiz Ancak hasta, yeni bilgileri ancak tekrarlayabildiği sürece hafızasında tutabiliyor gibi görünmektedir. Tüm bunlar, hipokampusu hasar görmüş bir kişinin hem uzun süreli belleğe (uzak geçmişteki olayların depolandığı yer) hem de kısa süreli belleğe (anında hatırlama veya içsel tekrar için kullanılan) sahip olduğunu gösterir. Görünüşe göre KP ile DP arasında kopuk bir bağlantı var ve bu nedenle "yeni bilgileri DP'ye çevirme" yeteneğini kaybetti. Dolayısıyla, Milner sendromu dualite teorisi ile oldukça tutarlıdır; bu teori, böyle bir hafızanın nasıl olduğunu anlamaya yardımcı olur. bozuklukları ortaya çıkabilir.
Dualite teorisi lehine diğer veriler deneysel çalışmalar sonucunda elde edilmiştir. Hatırlama sırasında yapılan hataların incelenmesi ilginç bilgiler sağlar. Bu tür hataların meydana geldiği durumlardan biri, "bellek boyutu" veya "anlık bellek" ile ilgili problemlerde yaratılır (anlık belleğin CP'nin başka bir adı olduğunu hatırlayın). Bu tür görevlerde özneye harfler gibi kısa bir dizi öğe sunulur ve bunları hemen tekrarlaması istenir. Teorik olarak, bu görevi yerine getirirken, mektuplar oldukça yakın zamanda sunulduğu için CP'deki bilgiler kullanılır. Denek sıradaki harf yerine sıradaki olmayan bir harfi söylediğinde "karıştırma hatalarından" söz etmektedir. Daha önce de belirtildiği gibi, bu tür hatalarla, ses bakımından benzer olan B ve V gibi harfler, farklı sese sahip harflerden daha sık karıştırılır ve bu, harflerin görsel sunumu durumunda da görülür.
Şimdi uzun süreli bellekle ilgili benzer bir deneyi ele alalım. Deneğe bir dizi kelime sunulur ve bir saat sonra bunları hatırlaması istenir. Bunu yaparken yaptığı hatalar, kural olarak, akustik değil anlamsal olacaktır. Örneğin, sunulan liste İŞ kelimesini içeriyorsa, denek bunun yerine bir CESET yerine İŞ kelimesini adlandıracaktır. Böylece anlam bakımından benzer bir kelimeyi adlandırır, ancak kelimeleri seslerine göre karıştırmaz. Kısacası, SP'den hatırlamada yapılan hatalar genellikle anlamsal niteliktedir (Baddeley ve Dale, 1966), SP'den hatırlamada yapılan hatalar ise çoğu durumda işitseldir. Bu, CP'de depolanan bilgilerin muhtemelen "işitsel biçimde" kodlandığını ve DP'de depolanan bilgilerin "anlamsal", anlamsal biçimde kodlandığını gösterir.
Serbest hatırlama ile yapılan deneylerin sonuçları da dualite teorisi lehine konuşuyor. Bu sonuçlardan, hatırlama sıklığının dizideki yere bağımlılığına ilişkin bir eğri oluşturmanın mümkün olduğunu ve bu eğride başlangıç bölümünü, orta platoyu ve bitişi ayırt etmenin mümkün olduğunu daha önce belirtmiştik. bölüm (Şekil 2.2, A). Hafızanın dualite teorisi bu eğriyi şu şekilde açıklar. Başlangıç etkisi, DP'den hatırlamanın sonucudur. Dizinin ilk kelimelerinin "boş" bir CP'ye düşmesinden kaynaklanır: öznenin odaklanacak başka bir şeyi yoktur ve bu nedenle ilk birkaç kelimeyi tekrar tekrar tekrarlayabilir. Ama sonunda - ilk altı kelimeden sonra diyelim - CP'de aynı anda tutabileceğinden daha fazla kelimeyi özümsemesi gerekiyor (sınırlı hacmi nedeniyle). Sonraki her kelime, CP'den kaybolmadan önce yalnızca birkaç kez tekrarlanabilir. Böylece dizinin ilk kelimeleri daha çok tekrarlanır ve bu nedenle DP'ye daha verimli bir şekilde çevrilir. Bunun aksine, sıranın ortasındaki kelimeler zaten dolduğunda CP'ye girer; hepsi yaklaşık olarak aynı (küçük) sayıda tekrar edilebilir ve bu nedenle tüm bu kelimelerin hatırlama sıklığı aynı nispeten düşük seviyededir.
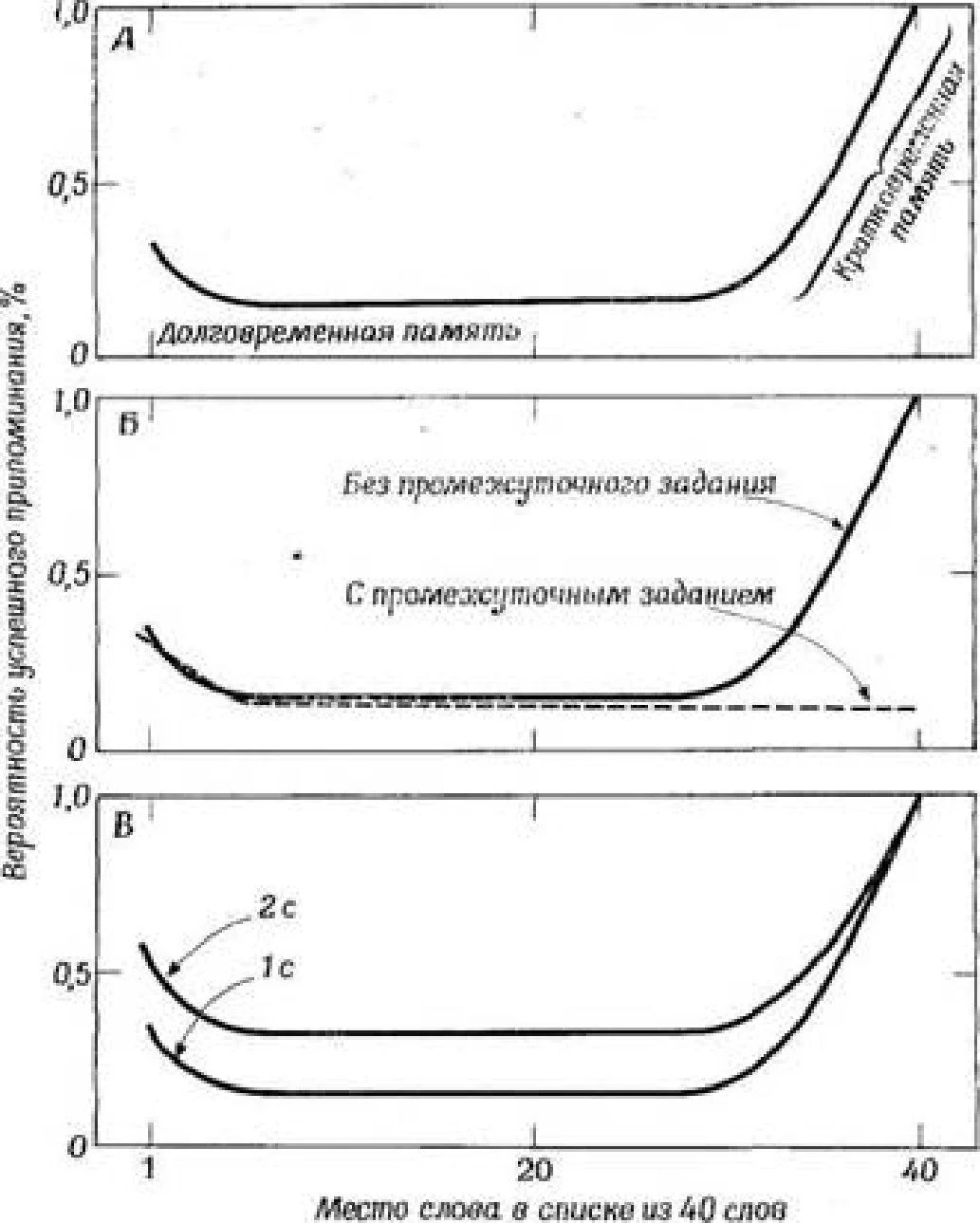
Rns. 2 2 Yüksek hatırlama deneyleri (Laggayn Murdoek'e göre, 1962; Pnstmaria ve Phillips, 1965). L, ducis ve ost frekansları için ücretsiz asponnnapnn b listesinden; DL'IgOyrSmsEilSіy GІYA.and yati'nin (eğrinin ilk ve orta kısımları) ve kısa süreli istihdamın (Eğrinin son bölümü) OTmsChsnS katılımı. B. Özneye sunulan aritmetik problemini listenin sunumu ile boş hafıza arasındaki aralıkta etkileriz : eğrinin uç kısmı düzleşir. B. Sunum hızının eğri üzerindeki etkisi <listedeki yer - hatırlama sıklığı"; daha yüksek bir sunum hızında (aralık ! s), eğrinin ilk ve orta segmentleri daha aşağıda, daha düşük bir hızda (2 s aralığı) bulunur; Kenscheago bölümüne gelince, sunum hızının etkisi çok az.
Bitiş etkisi şu şekilde açıklanır: satırın sonundaki öğeler, geri çağırma başladığında hala CP'dedir; bu nedenle denek onları doğrudan CP'den yeniden üretir ve onlar için hatırlama sıklığı çok yüksektir. Bu açıklama, deneklerin genellikle sıranın sonundaki kelimeleri yeniden üretmeye başlar başlamaz adlandırmaları ile de desteklenmektedir.
Dualite teorisine dayanan bu açıklamalar, eğrinin başlangıç ve bitiş bölümlerinin ayrı ayrı etkilenebileceğini gösteren deneylerle pekiştirilmiştir. Açıkçası, bu sırasıyla DP ve CP'yi etkiler (Şekil 2.2). Örneğin, özneye bir dizi sözcük sunduğumuzu ve yalnızca 30 saniye sonra yeniden üretmeye başlamasını önerdiğimizi varsayalım. Arada, CP tarafından alınan kelimeleri tekrar etme fırsatından mahrum kaldığına inanarak ona birkaç aritmetik örnek veriyoruz. Böyle bir prosedürün bir şekilde eğrinin sonunu etkilemesi beklenmelidir, çünkü özne artık son kelimeleri doğrudan CP'den yeniden üretemeyecek. Gerçekte böyle olur: Bu tür deneylerde nihai bir etki yoktur (örneğin bkz. Postman ve Phillips, 1965; Şekil 2.2, B).
Ayrıca kelimelerin sunulma hızını değiştirerek DP'yi etkilemeye çalışabilirsiniz. Yüksek hızda - saniyede bir kelime - öznenin tekrarlamak için çok az zamanı vardır ve sunumun iki kat daha yavaş - her iki saniyede bir kelime - yapılması durumunda olduğundan çok daha az kelime DP'ye düşebilir. (Ancak bu, CP'deki depolamayı etkilemeyecektir: denek, her iki sunum hızında da CP'deki son birkaç kelimeyi tutabilecektir.) Bu hipotez de doğrulandı. Düşük bir sunum hızında ücretsiz geri çağırma eğrisinin ilk ve orta bölümleri daha yüksekte yer alır, çünkü böyle bir hızda daha fazla sayıda tekrar mümkündür, bu da DP'de daha verimli depolama sağlar. Aynı zamanda sunum hızının eğrinin terminal bölümü üzerinde pratik olarak hiçbir etkisi yoktur (Murdock, 1962; Şekil 2.2, B).
Son on yılda dualite teorisi geniş çapta kabul gördü, ancak göründüğü kadar mükemmel değil. Her şeyden önce, bu teori lehine sunulan kanıtların çoğu, DP'den ayrı bir CP'nin varlığını varsaymadan açıklanabilir. Wickelgren (1973), bellek ikiliği teorisi lehine dokuz ana kanıt grubunu inceledi ve bu nedenle altı tanesini reddetti. Örneğin, bir ara görevin tanıtıldığı yukarıda açıklanan deneyi düşünün (yani, bir dizi öğenin sunumu ile serbest hatırlama arasındaki aralıkta sunulan bir görev). Böyle bir görev yapıldığında eğrinin uç kısmının düzleştiğini, başlangıç kısmının ise neredeyse hiç değişmediğini biliyoruz; ara görevin etkisindeki bu fark, dualite teorisi lehine bir argüman olarak verilir. Bununla birlikte, herhangi bir deneyimde dizinin başındaki öğelerin ara malzemeden etkilendiğini fark edersek, bu argüman inandırıcılığını kaybeder. Ne de olsa, serinin diğer tüm üyeleri onları takip ediyor ve ancak bundan sonra üremeleri başlıyor. Böylece serinin, ilk unsurların sunumu ile onların hatırlanması arasına sıkışan son unsurları da özünde bir ara malzeme rolü oynuyor. Ayrıca, Bölüm'de göreceğimiz gibi. Şekil 9'da, bir ara görev kendisinden hemen önceki bilgilerin hatırlanmasını büyük ölçüde etkileyebilse de, ancak daha fazla ara malzeme eklendikçe, her yeni öğenin etkisi giderek zayıflayacaktır. Bu nedenle, listenin sunumunun sonunda sunulan görevin, listenin ilk bölümündeki öğelerin çoğaltılması üzerindeki etkisinin küçük olması şaşırtıcı değildir: böyle bir görev gerçekleştirildiğinde, bu ilk bölüm listenin ikinci bölümünü oluşturan unsurların etkisini çoktan deneyimlemiştir. Başka bir deyişle, listenin sonunda sunulan görevin uç elemanlarının geri çağrılması üzerindeki etkisi, orta ve uç kısımların ilk parçanın hatırlanması üzerindeki etkisi ile karşılaştırılabilir. Ancak bu böyleyse, ara görevlerin performansının eğrinin farklı bölümlerini farklı şekillerde etkilediği ve dolayısıyla listeden sonra sunulan görevlerin etkisine dayalı olarak dualite teorisi lehine argümanlar ileri sürülemez. belirleyici sayılamaz.
Dualite teorisinin geçerliliği hakkında şüphe uyandıran başka deneysel veriler de var. İlerleyen bölümlerde kısa süreli ve uzun süreli belleğe daha detaylı baktığımız için bu tür bir takım verilerle uğraşmamız gerekecek ama şimdi bunlardan bazılarına değineceğiz.
, CP'de ve CP'de farklı bilgi gösterimi biçimleriyle (farklı hafıza kodu ) ilgilidir . DP. Daha önce de söylediğimiz gibi, CP'de bilgi işitsel biçimde ve DP'de - anlamsal biçimde kodlanmıştır. Bununla birlikte, CP'de görsel ve anlamsal (ve sadece işitsel değil) kodlamaya da tanıklık eden deneysel verilerle çok yakında tanışacağız. DP'nin işitsel ve görsel bilgiler (ayrıca kokular, tatlar ve dokunma duyumları hakkında bilgiler) içermesi gerektiği zaten söylendi; yoksa uzun zamandır görmediğimiz yüzleri veya sesleri nasıl tanıyabilirdik? duymadı? Dolayısıyla, iki bellek türü arasındaki kod türüne (işitsel veya anlamsal kod) göre ayrım, bazı deneylerin sonuçlarından göründüğü kadar tartışılmaz değildir.
Ayrıca, tekrar olmaksızın ezberlenen öğelerin CP'de yalnızca birkaç saniye tutulduğunu, DP'de ise süresiz olarak saklanabileceğini de not ettik. Bu, bunları ayırt etmek için bir kriter görevi görebilir; Bununla birlikte, iki bilgi deposu, CP'de bilgi saklama süresine ilişkin tahminlerin büyük farklılıklar göstermesi gerçeğiyle mesele karmaşıklaşıyor. Aynı şey CP'nin hacmi için de söylenebilir; yani içinde aynı anda depolanabilecek eleman sayısı; burada da tahminler çok farklı. Bu tutarsızlıkların nedenlerinden biri, CP ve DP'nin -eğer gerçekten iki farklı sistem iseler- birbirine çok fazla bağımlı olmasıdır. Aralarındaki bağlantı, yalnızca CP'de yer alan bilgilerin tekrarının DP'de izlerin oluşmasına yol açmasında yatmıyor: buna karşılık DP, CP'deki bilgilerin kodlanmasında da büyük rol alıyor. Örneğin, bir kişiye sunulan bir mektubun görsel olarak CP'ye girdiğini varsayalım. Görsel imajını ve adını aramak için DP'ye başvurmadan bunun gerçekten bir mektup olduğunu nasıl bilebilirdi? DP: örüntü tanımaya dahil olduğu için, aynı zamanda CP'deki bilgilerin kodlanmasına da katılır. Ek olarak DP, tanındıktan sonra CP'deki öğelerin temsilini etkileyebilir. Örneğin, anlamsız heceli VPS, CP'de "Wisconsin" kelimesinin kısaltması olarak saklanabilir. VIS hecesinin "Wisconsin" kelimesi şeklinde hafızada saklanmasıyla gerçekleşen aracılık süreci, DP'den gelen bilgilerin bu heceyi daha anlamlı bir birime çevirmek için kullanılmasından kaynaklanmaktadır.
Bu karmaşık işlemleri ve bellek kodlarını dualite teorisi çerçevesine sıkıştırmaya çalışan bazı psikologlar bazen CP ve DP ile her türlü manipülasyonu yaparak bu kavramları tanınmayacak şekilde çarpıttı. Diğer psikologların bir sonucu olarak şu soru ortaya çıktı: "İkilik teorisiyle hiç uğraşmaya değer mi?"
Hafıza ikiliği teorisine bir alternatif, sözde "işleme seviyeleri" teorisidir (Graik ve Lockhart, 1972; Posner, 1969). Bu, bilgi işleme teorisinin çeşitlerinden biridir, çünkü işleme sürecini birkaç aşamaya (düzeyler olarak adlandırılır) ayırır, ancak CP veya DP gibi yapısal bileşenler yoktur. Dualite teorisinde bir bellek sisteminin yapısal bileşenleri olan şeyler, seviyeler teorisinde, örneğin örüntü tanıma veya dikkat gibi süreçler olarak görülür.
Örneğin, KP mağazasını bir süreç olarak yorumladığımızı varsayalım. Daha sonra, kısa bir süre hafızada tutulan bir öğeyi özel bir depodaymış gibi düşünmek yerine, onun bir süreçten geçtiğini düşüneceğiz - bu durumda sunumdan kısa bir süre sonra işitsel bir temsil süreci. Bu yaklaşımın avantajlarından biri, kısa süreli bellek olarak kabul ettiğimiz alt sistemde bazı öğelerin görsel olarak temsil edilebileceği ortaya çıkarsa, bu olguda bazı önemli ilkelerin (yani CP'de bilgi işitsel biçimde kodlanmıştır). Buna basitçe başka bir olası süreç, bir öğeyi sunulduktan kısa bir süre sonra görsel olarak kodlama süreci olarak bakabiliriz.
Tüm bunları düşünürken, hangi teoriyi kabul ederseniz edin (ve KP ve DP hakkındaki tüm tartışmalara bakılmaksızın), bunun sadece bir teori olacağını hatırlamakta fayda var.
Burada ikilik teorisi lehine sunulan veriler -serbest hatırlama eğrisinin sonundaki değişiklikler, kısa ve uzun aralıklardan sonra yapılan hatalardaki farklılıklar ve fizyolojik gözlemlerden elde edilen sonuçlar- tümü, belleğin kısa süreli ve kısa süreli olarak bölünmesine işaret eder. uzun süreli bellek en azından yararlıdır. Bu bölünme bizi iki bilgi deposunu, CP ve DP'yi varsaymaya zorlayabilir, ancak aynı zamanda iki düzeyde bilgi işlemeye, iki bellek koduna veya diğer bazı ikili işlemlere veya mekanizmalara izin verir. Bu ayrımlardan hangisini benimsediğimiz belirleyici değil. Bir teorinin, gözlemlenen fenomenleri doğru ve kapsamlı bir şekilde açıklamadan açıklamak ve açıklamak için yararlı bir araç olarak hizmet edebileceğini hatırlamak önemlidir.
3. Bölüm
Dokunma kayıtları
Bölüm'de açıklanan bellek modeli. 2, dışarıdan gelen bilgilerin, tanınmadan ve iletilmeden önce orijinal biçiminde (yani, orijinal uyaranın doğru bir şekilde yeniden üretilmesi olarak) kısa bir süre için tutulabildiği duyusal kayıtları içerir . Her duygu için böyle bir kaydın var olduğu varsayılır. Psikologlar duyusal kayıtları çeşitli şekillerde adlandırdılar: duyusal bilgi depoları, ikonik bellek veya kategori öncesi bellek (ikinci ad - "ön kategorik" - giriş duyusal sinyalinin henüz tanınmadığını, herhangi bir kategoriye atanmadığını gösterir).
GÖRSEL KAYIT
Görme ve işitmeye karşılık gelen duyusal kayıtlar en çok çalışılanlardır. Bunlara ikonik ve ekotik kayıtlar adı verildi (Neisser, 1967). İkonik bellek, yani bilginin ikonik izler biçiminde depolanması hakkındaki mevcut verilerin çoğu George Sperling tarafından elde edilmiştir (Sperling, 1960; Averbach ve Sperling, 1961). Sperling'in araştırması, doğrudan hatırlama üzerine deneylerle başladı. Bu tür deneylerde deneklere çok kısa bir süre için bir dizi harf sunulur ve ardından bunları hatırlamaları istenir. Sperling tarafından elde edilen sonuçlar, yeniden üretim verimliliğinin sunulan harflerin sayısına bağlı olduğunu tam bir kesinlikle gösterdi. Konuya en fazla dört harf verilirse, onları oldukça doğru bir şekilde yeniden üretir. Harf sayısı beş veya daha fazlaya çıkarılırsa, üreme kötüleşir - denekler artık sunulan tüm harfleri hatırlayamaz, ancak ortalama 4-5 harf üretebilir. Bu üst sınıra (yani doğrudan geri çağırma için görevin doğruluğunun %100'ün altına düştüğü öğelerin sayısı) bellek boyutu denir. Az önce açıklanan deneylere dayanarak, örneğin, harfler için anlık hafıza miktarının yaklaşık beş olduğunu söyleyebiliriz. ("Harfler için" cümlesi önemlidir, çünkü hafıza miktarı, ezberlenecek materyalin doğasına bağlı olarak biraz değişir.)
Bu tür deneylerde sunulan harflerin yeri pek önemli değil. Örneğin, çoğaltma verimliliğini etkilemeden altı harf bir satırda veya her biri üç harften oluşan iki satırda düzenlenebilir. Sperling tarafından yürütülen belirli bir deneyi ele alalım. Konunun 3X3 tablo şeklinde (yani her biri üç harften oluşan üç sıra halinde) düzenlenmiş dokuz harfle sunulduğunu varsayalım. Sunum çok kısa sürüyor - sadece 50 ms. Bir milisaniye 0,001 s'ye eşittir, yani 50 ms 0,05 s'dir; bu süre zarfında öznenin uzağa bakacak zamanı yoktur. Böyle bir tableti sunduktan sonra hatırlayabildiği her şeyi yeniden üretir; sonuçlar artık önceden tahmin edilebilir: ortalama olarak, denek yalnızca dört veya beş harfi yeniden üretebilecektir.
Öznenin hepsini görmediği için dokuz harfin hepsini yeniden üretemeyeceği varsayılabilir; çünkü 0.05 s çok kısa bir süre. Ancak başarısızlığın nedeni mektupların sunum süresinin kısa olması değil; sunum süresi 0,5 s'ye çıkarılırsa (tüm harfleri görmek için oldukça yeterli olan süre) sonuçlar değişmeyecektir. Ancak bu bizi şaşırtmamalı: açıklanan deneyde, Ebbinghaus deneylerinde olduğu gibi hafıza miktarı belirlenir ve sonuçlar benzer görevler için daha önce not ettiğimiz sonuçlara benzer: çok çeşitli koşullar altında Sunumun hemen ardından denekler, kısa öğe listelerini çok başarılı bir şekilde yeniden üretir, ancak listenin uzunluğu arttıkça hatırlama yeteneği bozulur.
Deneğin bir mektup tablosuyla sunulduğu ve daha sonra hepsini veya mümkün olduğu kadar çoğunu hatırlamasının istendiği, az önce açıklanan yönteme bu nedenle tam rapor yöntemi denir. Sperling, hatırlama yeteneğini yalnızca bu yöntemle değil; kısmi rapor yöntemi adını verdiği başka bir yeni yöntem geliştirdi . Üç sıra halinde düzenlenmiş bir dizi harfle konu kısaca sunulur. Sunumun bitiminden hemen sonra denek, hangi harf dizisinin yeniden üretilmesi gerektiğini belirten bir sinyal görevi gören yüksek, orta veya alçak bir ton duyar. Yüksek bir tona yanıt olarak, üst sırayı, ortaya - ortaya ve alçak - alt sıraya yanıt olarak çalmanız gerekir. Bir ses sinyali verdikten sonra, denek hemen karşılık gelen harf dizisini yeniden üretmeye çalışır. Bu olaylar dizisine (harflerin sunumu - ses - yeniden üretim) deneme denir ve deney, bu tür bir dizi denemeden oluşur.

Rie. 3 J. Sperling'in deneylerinin tam ve kısmi raporlarla görselleştirilmesi (Sperliıg, 1960).
Kısmi rapor içeren görevin başka bir versiyonunda, özneden sunulan tablodan belirli bir harfi yeniden üretmesi istenir. Bu durumda (Averbach ve Coriell, 1961), karşılık gelen talimat bir sesle değil, görsel bir sinyalle verilir: harflerden sonra, harflerden birinin bulunduğu yerin üzerinde siyah bir şerit bulunan beyaz bir alan belirir; ve konu bu mektubu çoğaltmalıdır. Genel olarak, kısmi bir raporla yapılan deneylerin ana özelliği, harflerin sunumunu süjeye tüm harf setinin hangi kısmının hatırlanması gerektiğini söyleyen bir tür sinyalin takip etmesidir.
Tam bir raporla yapılan deneylerin sonuçlarını zaten biliyoruz: sunulan toplam harf sayısına bakılmaksızın, denek beşten fazlasını yeniden üretemez. Sperling'in verilerinden de görülebileceği gibi (Şekil 3.1), kısmi raporlama deneyleri oldukça farklı sonuçlar vermektedir. Dokuz harfin sunumuyla durumu düşünün. Kısmi raporlu deneylerde, hangi serinin yeniden üretilmesi gerektiğine bakılmaksızın deneklerin cevapları neredeyse %100 doğru çıkıyor. Ancak bu, ses sinyalinin duyulduğu anda, deneğin dokuz harfin tümünün hala hafızasında olduğu anlamına gelir, aksi takdirde, denemelerden birinde herhangi bir satırı yeniden üretirken şüphesiz hata yapacaktır.
Aslına uygunluk derecesi, ses sinyali anında öznenin hafızasında saklanan harflerin sayısını tahmin etmek için kullanılabilir. Bunu yapmak için, doğruluk derecesini (yani, doğru çoğaltma yüzdesini) sunulan harf sayısıyla çarpmak yeterlidir. Örneğin, 12 harfli tabloların (her biri dört harften oluşan üç sıra) çoğaltılma doğruluğu yaklaşık %76 idi; bu, raporlama sırasında bu 12 harften 9'unun hafızada olduğunu gösterir ve bu, dokuz harfle yapılan deneylerde elde edilen sonuçlarla neredeyse mükemmel bir şekilde örtüşür.
Sterling'in deneylerinin sonuçları Şek. 3.1, uyaranın sunumundan hemen sonra, hafızanın öznenin tam bir raporda yeniden üretebileceğinden çok daha fazla materyal içerdiğini göstermektedir. Şu soru ortaya çıkıyor: Kısmi ve tam bir rapor arasındaki bu tür bir tutarsızlığın nedeni nedir? Hafızasında 9 harf saklanabilirken, deneğin hafıza kapasitesinin sözde sadece 5 harf olması neden?
Bu soruyu cevaplamadan önce, kısmi raporlama deneyinin bir modifikasyonunu ele alalım. Deneyin yukarıda açıklanan varyantında, ses sinyali harflerin sunumundan hemen sonra verildi. Ancak sinyali geciktirebilirsiniz. Sinyalin çeşitli sürelerde bir gecikme ile uygulandığı deneylerin sonuçları, Şekiller 1 ve 2'de gösterilmektedir. 3.2 (12 harflik bir tablo için). Gecikmeden bir sinyal verildiğinde, çoğaltma verimliliğine bakılırsa, hafızada yaklaşık 9 harf vardı. Ancak gecikme arttıkça denekler giderek daha fazla hata yaptı ve 1 saniyelik bir gecikmeyle çoğaltma verimliliği yaklaşık olarak tam bir raporla ne olacağına karşılık geldi, yani 5 harfti.
on

o fla (W Q5 i
oyii.s
PtIc. 3.2. Çalma kayın ve kısmi şarkı söyleyen
çeşitli sinyal gecikmeleri ile deneyler; karşılaştırılabilir malzeme için sarhoş bir raporla jakspern* mentlerde yeniden üretim de gösterilmiştir
(Sperlinff, 1960).
Sorumuza dönelim. Sperling'in deneyleri, görsel sunumdan hemen sonra bellekte 1 saniye sonrasına göre daha fazla bilginin depolandığını gösteriyor. Öğretici sinyalin gecikmesi olmadan kısmi raporlama ile yapılan deneylerin sonuçları, uyaranın sunulmasından sonraki ilk anda bellekte yer alan bilgilerin ölçülmesini mümkün kılar. Buna karşılık, tam rapor deneyleri, bir süre geçtikten sonra geriye ne kaldığını belirlemeye izin verir; hafızanın artık başlangıçta olduğundan çok daha az bilgi içerdiği ortaya çıktı. Kısmi raporlama ve sinyal gecikmesi ile yapılan deneylerin sonuçları, bu iki an arasında ne olduğunu gösteriyor: Görünüşe göre, ilk ikonik iz yavaş yavaş kayboluyor, böylece zamanla, uyaranın içerdiği bilgilerin giderek daha azı kalıyor. Kısacası, Sperling'in sonuçları, izleri son derece doğru olan ancak çok hızlı bir şekilde kaybolan bir tür doğrudan görsel belleğin varlığına işaret ediyor.
Sperling'in deneylerde işlevini gösterdiği anlık bellek, modelimizde duyusal kayıt dediğimiz şeye karşılık gelir. Sperling'in deneyleri, ikonik görüntüler için görme kaydıyla ilgilidir. Bizim modelimizde (Bölüm 2) bu kaydedicinin görevi, görsel bilgiyi kısa bir süre için orijinal haliyle tutması ve bu da verilen bir uyaran hakkında daha fazla bilginin sisteme gönderilmesine izin vermesidir. İkonik hafıza, uyaranların pratik olarak orijinal halleriyle sunulduğu oldukça ilkel bir hafıza türü olduğu için, sunum koşullarından büyük ölçüde etkilenir. Bu açıdan ikonik bellek, daha derin bellek düzeylerinden farklıdır. İkonik hafızayı etkileyen önemli değişkenler şunları içerir: görsel bir uyarıcıdan önceki ve sonraki aydınlatma (Sperling'in deneylerinde, 0 - harflerin sunumu) ve onu takip eden aydınlatma, bu uyarıcıyı takip eden görsel uyarı ve sunum süresi.
Aydınlatmanın etkisi, birinde deneğin harflerin sunumundan önce ve sonra karanlık bir alan, diğerinde ise parlak bir alan gördüğü iki deneyin sonuçları karşılaştırılarak incelenebilir. Görünüşe göre karanlık bir alan söz konusu olduğunda ikonik görüntü daha uzun süre korunuyor. Bu, görüntü solma süresinin (deneysel olarak kısmi raporlu deneylerde en büyük sinyal gecikmesi olarak tanımlanır, bu sırada deneklerin harfleri tam rapordan daha iyi yeniden ürettikleri) karanlık bir alanda daha uzun olması gerçeğiyle gösterilir. Açıkçası, parlak bir alanla, sistemin ikonik görüntüde yer alan bilgileri "görmesi" daha zordur; Görünüşe göre parlak alanın yarattığı görsel uyarım, bir şekilde görüntünün algılanmasını bozuyor. Aslında, özünde, bir ışık alanı aynı zamanda görsel sistem tarafından algılanan belirli bir olgudur.
Bu varsayım, harflerin sunumunun ardından bir ses sinyali veya siyah bir şerit değil, başka bir şeyin geldiği deneylerin ışığında daha da makul hale geliyor (Averbach ve Coriell, 1961). Harf tablosundan sonra, yerinde kalırsa harflerden birinin yerleştirileceği bir daire göründüğünü varsayalım (Şekil 3.3). Konu, bu "çevreli" mektubu yeniden üretmelidir.
Bu deneyin sonuçları biraz beklenmedikti. Şek. Şekil 3.4'te, sinyal işaretinin önemli bir gecikmeyle (0,5 s kadar) veya herhangi bir gecikme olmaksızın sunulduğu durumlarda, yeniden üretim hem şerit hem de daire ile yaklaşık olarak eşit derecede başarılıdır. Bununla birlikte, gecikmesiz ve uzun gecikmeli arasındaki orta durumlarda, daire deneylerinde üreme verimliliği, şerit deneylerinden çok daha düşüktü.

Pirinç. 3.1 Ç spikіyі.vainei daireler ile Ske-a eksmriyeGPYA
ka n as sngііzla {Averbaclı a. C-orwil. 1YY).
Şek. 3.4 verileri şu şekilde yorumlanmıştır. Daire harfleri hemen takip ettiğinde, oh etkili bir şekilde harflerden biriyle örtüşür; özne aynı zamanda bir harfin bir daire içine yerleştirildiğini "görür" ve bu harfi çağırır. (Bu, bir şerit kullanırken olana benzer: kısa bir gecikmeyle, özne, üzerinde bir şerit bulunan bir harf görür.) Çok uzun gecikmelerde, harfin görüntüsü zaten olduğunda hem daire hem de şerit görünür. silindi Ancak, ara gecikmeler için işler farklıdır. Daire, vurgulaması gereken harfin görüntüsünü siler ve onun yerine geçer; özne harfi ve daireyi görmek yerine yalnızca daireyi görür. Daire zamanda geriye doğru hareket ederek kendisinden önceki harfi maskelediğinden veya sildiğinden bu olguya ters maskeleme denir. (Harfe göre daha fazla yer değiştiren bir şerit silinmeye neden olmaz.)

opchepіu için sshnpgom
Pite. 3.4. kіyulmvanav kruzhnya n durumunda kısmi raporların karşılaştırmalı etkinliği (julos ve sinyal kalitesi tAvccbactı a. CogіeІІ, L961}> Küçük veya çok büyük bir gecikmeyle, vakalar için uzatma ve duvar kağıdının etkisi aynıdır ; ancak ara durumlarda - Evaigki kupasından belirgin şekilde daha düşüktür.
Aydınlık ve karanlık alanların etkisindeki yukarıda belirtilen fark, silme olgusuyla da bağlantılıdır. Kendisi görsel bir uyaran olduğu için ışık alanının ikonik olarak müdahale ettiğini öne sürdük. Ve şimdi, harf setinin hemen ardından gelen ve bunlardan birinin yerine yerleştirilen uyaranın hemen hemen aynı şekilde hareket edebileceği ortaya çıktı. Görüntü silmenin etkisini bizim duyusal kayıt konseptimizle karşılaştırdığımızda, silmenin önemli bir işlevi yerine getirdiğini görüyoruz: ikonik görüntülerin duyusal kayıtta çok uzun süre kalmasına izin vermiyor, görsel bilgilerin yığılması ve karıştırılması. Silme işlevi tam olarak bunun olmasını önlemektir. Yeni bilgiler geldikçe, bu süreç önceki ikonik görüntülerin kalıntılarını kaldırarak ona yer açar.
SES KAYDI
İkonik görüntüler olmasaydı, görsel uyaranları ancak gözümüzün önünde kaldıkları sürece "görebilirdik". Tanıma belirli bir süre aldığından, bazen uyaranı görebildiğimiz süreden daha uzun sürdüğünden, hızla kaybolan uyaranları tanımakta genellikle başarısız oluruz. Şimdi, işitme için eko-hafıza-duyusal kayıt olmasaydı ne olacağını görelim. Benzer bir akıl yürütmeyle, sesleri yalnızca duyuldukları sürece "duyabileceğimiz" sonucuna varırız. Ancak böyle bir sınırlama çok ciddi sonuçlara yol açacaktır: konuşulan dili anlamakta büyük zorluklar yaşayacağız. Bunu açıklamak için Neisser (1967, s. 201) şu örneği verir: Bir yabancıya "Np, gayret değil, mühür" ("Hayır, gayret değil, ama mühür!") denilir. Neisser, bir yabancının şevk kelimesinden gelen "z" harfini mühür kelimesindeki "s" ile karşılaştıracak kadar uzun süre hafızasında tutamaması durumunda hiçbir şey anlayamayacağını belirtir . Ekolojik hafızanın faydalarına dair başka örnekler bulmak zor değil. My, 'Geldin mi?' cümlesindeki soru tonlamasını, ikinci kısmın çalındığı sırada ilk kısmı karşılaştırma için mevcut olmasaydı yakalayamazdı.Genel olarak, seslerin bilinen bir süresi olduğundan, bileşenlerinin bir süre tutulabileceği bir yer olabilir. Burası işitme için duyusal kayıttır.
Ekolojik görüntünün varlığı, Sperling'in deneylerinde ikonik görüntünün gösterilmesine benzer bir deneyle gösterildi. Bu deneydeki denekler (Mogau a.o., 1965) "dört kulaklı" insanlar gibi davrandılar, yani aynı anda farklı kanallardan gelen dört mesajı dinlediler. Bir miktar yana saptıktan sonra, kanalın bilgi kaynağı, bu durumda ses anlamına geldiğini açıklayacağız . Bir stereo çalarınız varsa bu konsept size tanıdık gelebilir. Genellikle çalınan müziği biraz farklı şekillerde yeniden üreten iki hoparlörü vardır. Benzer şekilde, yukarıda belirtilen deneyi gerçekleştirmek için dört kanallı bir sistem tasarlanabilir. Bunun bir yolu, dört hoparlör kurmak ve konuyu bunların ortasına yerleştirmektir. Başka bir yol da, iki ses kaynağının bağlanması için her bir kulaklığı ayırarak kulaklık kullanmaktır. Moray ve işbirlikçileri, her iki sistemin de - dört hoparlör veya "bölünmüş" kulaklık - yaklaşık olarak eşit derecede etkili olduğunu keşfetti. Bizim amaçlarımız açısından asıl mesele, deneklerin ayrı ayrı kanallar arasında ayrım yapabilmesidir: Onlardan belirli bir kanalı dinlemeleri istendiğinde, bunu yapabilirler. Sadece kaotik sesleri değil, mesajların çeşitli kaynaklardan ayırt edilebildiği bir şeyi de duyarlar.
Dört kulaklı insanlara geri dönelim. Moray ve işbirlikçilerinin deneylerinde, her denek bir dizi denemeye katıldı. Her denemede aynı anda iki, üç veya dört kanaldan (hoparlörlerden) gelen mesajları dinledi. Her mesaj alfabenin 1 - 4 harfinden oluşuyordu. Deneğin görevi, bu harfleri duyduktan sonra hatırlamaktı.
Deneyin bir versiyonunda tüm harfleri hatırlamaya çalıştı; tam bir rapor seçeneğiydi. Diğer seçenek, Sperling'in deneylerindeki gibi kısmi bir rapor gerektiriyordu. Oynatmanın başlangıcı için sinyal ses değil, ışıktı. Denek dinlerken elinde hoparlörlerin yerleşimine göre yerleştirilmiş iki, üç veya dört ampul bulunan bir tahta tuttu. Mesaj iletiminin bitiminden 1 sn sonra ampullerden biri yanıp söndü; bu bir sinyal görevi gördü, ardından konu ilgili kanaldan iletilen mektupları yeniden üretmeye başladı, yani kısmi bir rapor verdi. Moray ve ortak çalışanları, kullanılan kanal sayısına ve bir kanal üzerinden iletilen mektup sayısına bakılmaksızın, kısmi rapordaki geri çağırma oranının tam rapordakinden daha yüksek olduğunu buldular. Bundan ve Sperling'in deneylerinden, harflerin sunumundan hemen sonra (1 s sonra) hafızanın onlar hakkında sonraki döneme göre daha fazla bilgi içerdiği sonucuna varabiliriz. Görünüşe göre bu bilgi, ikonik bir görüntünün işitsel bir analoğu olan bir biçimde, yani ekolojik bir görüntü biçiminde sunuldu.
Ekolojik hafızanın varlığını bilmek veya en azından varsaymak, şu soruyu sorabiliriz: İçinde bir ses uyaranının izi ne kadar kalır? Bu sorunun cevabı net değil: Ekolojik formdaki bilgilerin saklanma süresine ilişkin tahminler büyük farklılıklar gösteriyor. Bu tahminlerden biri, Moray ve arkadaşları gibi kısmi raporlama yöntemini kullanan Darwin, Turvey ve Crowder'ın (Darwin a.o., 1972) çalışmalarının sonuçlarına dayanmaktadır. Darwin ve meslektaşları, deneklere üç öğeden (harfler veya sayılar) oluşan listeleri dinlemeleri için verdi; bu tür üç liste aynı anda üç kanalda iletildi. Denek ya hatırlayabildiği tüm unsurları (tam raporlu varyant) yeniden üretti ya da görsel bir sinyale uyarak belirli bir kanaldan gelen unsurları adlandırdı (kısmi raporlu varyant). Bu sinyal, mesaj iletiminin bitiminden 0, 1, 2 veya 4 s sonra verildi. Bu deneyin sonuçları Şek. 3.5; Yukarıdaki grafikten, kısa gecikmelerde (2 s'ye kadar), kısmi raporlu varyantta çoğaltma doğruluğunun tam rapordan çok daha yüksek olduğu, ancak 4 s'ye kadar bir sinyal gecikmesiyle görülebileceği görülebilir. kısmi rapor ile verimlilik azaldı. Bu, kısmi raporlamanın yüksek verimliliğini (tıpkı görsel uyaranlarla yapılan benzer bir deneyde olduğu gibi) belirlediğini varsaydığımız ekolojik bellekte, bilginin yaklaşık 2 saniye süreyle saklandığını gösterir.

Pirinç. 3.5. İşitsel uyaranların yakalanmasından sonra kısmi bir raporla deneyde gözlemlenen elementlerin sayısı, psi .ZNOST іі«.іі|іimzEI?Denchy EGRN MILLET OCHGTS.
Bir eko-imgenin akılda kalma süresini belirlemek için yapılan diğer deneylerde deneklere, arkalarından bir “anahtar” gösterilmeden tanımlanamayacak sesler sunuldu. Bu durumda, anahtarın öznenin sesi tanımlamasına ancak anahtarın sunulduğu anda bu sesin bir izi ekolojik hafızada hala saklanıyorsa yardımcı olabileceği varsayımından yola çıktık. Ses ile anahtar arasındaki aralığı kademeli olarak artırarak ve anahtarın sesin tanımlanmasını kolaylaştırdığı maksimum gecikmeyi belirleyerek, ekolojik bellekte bilgi saklama süresi tahmin edilebilir. Anahtar sesleri tanımlamaya yardımcı oluyorsa, bilgi hala depolanır ve yardımcı olmayı bırakırsa, çevresel bilgi kaybolmuş gibi görünür (veya en azından o kadar çoğu kaybolmuştur ki, anahtar bile işe yaramaz). Beklendiği gibi, orijinal ses ile tuş arasındaki aralık arttıkça, ikincisi genellikle daha az etkili hale gelir: görünüşe göre, sesin ekolojik bellekteki izi yavaş yavaş kayboluyor.
Örneğin, bir radyo yayınındaki atmosferik parazitle hemen hemen aynı şekilde hareket eden aşırı güçlü bir gürültünün varlığında belirli bir kelimeyi dinleyen bir özneye ne olduğunu düşünün (Pollack, 1959). Denek bu kelimeyi gürültüden hemen çıkaramaz. Kelimenin sunumundan bir süre sonra deneğe iki alternatifli zorunlu seçimli bir test sunulur. Test, ona görsel olarak iki kelimeyi - duyduğu kelime ve diğerini (dikkat dağıtıcı) - hangisini ikinci kez duyduğunu belirtme talebiyle sunmaktan oluşur. Bu kelimelerden biri yukarıda belirtilen anahtar görevi görür. Konunun daha önce sunulan kelimeyi anlamasına yardımcı olmalıdır - konu duyduğu sesi hala hatırladığı ölçüde.
Bu ve benzer formdaki diğer deneylerde (örneğin bkz. 1 saniyeden 15 dakikaya kadar aralık çok geniştir. Tahminlerdeki bu tür tutarsızlıklar göz önüne alındığında, seslerin işitsel kayıtta ne kadar süre tutulduğunu belirlemek zordur. 15 dakika gibi yüksek tahminlere gelince, bunların güvenilirliği konusunda bazı şüpheler var. Bu derecelendirmeler, deneğin anahtarla sunulduğunda sesin birincil, tanımlanamayan izini hala hafızasında tuttuğu ve sesi tanımlamak için bu anahtarı kullandığı varsayımına dayanmaktadır. Bununla birlikte, öznenin fiilen kısmi bir tanımlama yapmış olması da mümkündür. Örneğin, şöyle düşünüyor: "Kelime s sesiyle başladı ve iki heceden oluşuyor gibiydi." Artık sadece bir sesi değil, bu sesin sözlü tanımını da hatırlıyor ve bu tanımı 15 dakika boyunca kolaylıkla hafızasında tutabiliyor. Öyleyse, önemli bir aradan sonra, "Bu ya bir dağ sıçanı" ya da "anla" anahtarını alan öznenin duyduğu kelimeyi tanımlaması şaşırtıcı değildir. Büyük olasılıkla, ekolojik izlerin 15 dakikada korunması, böyle bir kısmi tanımlama ile açıklanabilir. Aynı zamanda, tahminlerdeki yukarıda belirtilen tutarsızlık kısmen, sunulan uyaranların doğasındaki ve deneysel koşullar altındaki farklılıklara bağlı olan gerçek ekolojik depolama süresindeki gerçek farklılıkları yansıtabilir.
Duyusal düzeyde, ses izleri genellikle görsel görüntülerden daha uzun sürer. Bu gerçek, sözde modalite etkilerini açıklamak için kullanılmıştır (Crowder ve Morton, 1969; Morton, 1970; Murdock ve Walker, 1969). Modalite etkisinin bir örneği, serideki serbest hatırlama sıklığına karşı yer eğrilerinde görülebilir. Sözcük listesinin görsel sunumuyla (kişi sözcükleri gördüğünde), sözcüklerin işitsel sunumundan (duyunca) biraz farklı sonuçlar elde edilir. Fark, eğrinin son bölümüyle ilgilidir. İşitsel sunumda, listenin sonundaki kelimelerin hatırlama yüzdesi görsel sunuma göre daha yüksekken, eğrinin ilk kısmında böyle bir fark yoktur. Başka bir deyişle, listedeki son birkaç öğe, denek onları gördüğünden çok duyduğunda daha iyi hatırlanır. Bu modalitenin etkisidir.
Modalitenin hatırlama üzerindeki etkisi, ekoik ve ikonik bellekteki izlerin farklı korunma süreleriyle açıklanır. Aynı zamanda, liste işitsel bir biçimde sunulduysa, listenin en son öğeleri hakkındaki bilgilerin ekolojik bellekten alınabileceğini belirtirler (bu, bu öğelerin sesiyle ilgili bilgilerin mümkün olduğu gerçeğinden kaynaklanmaktadır). birkaç saniye boyunca saklanır, yani sunumları ile geri çağırmaları arasındaki tüm süre boyunca devam eder) ve aynı öğeler hakkındaki ikonik bilgiler, görsel olarak sunulduğunda, yeniden üretimleri için herhangi bir temel oluşturmaya yetecek kadar uzun süre tutulmaz. Bu nedenle, işitsel sunumun belirgin bir avantajı vardır.
Modalitenin etkilerinin bu açıklaması, öğelerin farklı sunum hızlarında elde edilen verilerle desteklenir (Murdock ve Walker, 1969): yüksek hızlarda işitsel ve görsel sunumdan sonra çoğaltma arasındaki farklar, düşük hızlardan daha belirgindir. Modalite etkileri duyusal kayıtların özellikleriyle açıklanırsa beklenmesi gereken bu sonuçlardır. Ne de olsa, yüksek hızda, bir öğenin sunumu ile geri çağrılması arasındaki aralık, düşük hızda olduğundan daha kısadır; böylece izlerin kaybolması için daha az zaman kalır ve bu nedenle işitsel olarak sunulan liste geri çağrıldığı anda ekotik bellekte daha fazla öğe bulunur ve bu da hatırlamaları için bir avantaj oluşturur. Buna karşılık, ikonik görüntünün akılda tutulması sunum hızından önemli ölçüde etkilenmez (kısmen ikonik izlerin hızlı silinmesi nedeniyle ve kısmen de yüksek hızlarda sonraki görsel uyaranların kendilerinden öncekileri silebilmesi nedeniyle); bu nedenle yüksek hızlarda görsel sunumdan sonra viconic hafıza tarafından tutulan öğelerin sayısı artmaz ve bunların hatırlanması için herhangi bir avantaj yaratılmaz. Bu nedenle işitsel modalite, hızlı sunumdan görsel modaliteden daha fazla yararlanır.
Modalitenin etkileri hakkındaki tüm bu tartışmalardan, serbest hatırlama deneyinde sunulan listeden birkaç kelimenin eş zamanlı olarak eko-bellekte saklanabileceği sonucu çıkar. Ve bu, her yeni kelimenin kendisinden önceki kelimeleri silmediği anlamına gelir. Şu soru ortaya çıkıyor: Ekolojik görüntünün silinmesi hiç oluyor mu? Bu sorunun cevabı, silme ile neyi kastettiğimize bağlıdır. Silme ile görsel bir görüntünün silinmesine eşdeğer bir şeyi kastediyorsak, yani bir uyaranın onu takip eden bir diğeriyle fiilen yer değiştirmesini kastediyorsak, o zaman cevap muhtemelen olumsuz olacaktır. Başka bir sesin sunumunun hemen ardından gelen sesin onu etkili bir şekilde ortadan kaldırdığını düşünmek neredeyse imkansızdır. Sesler zaman içinde birbirini takip ettiğinden, onları tutacak bir mekanizma olması gerektiğini daha önce belirtmiştik. Ses dizilerini tanıma yeteneğimiz, yeni seslerin kendilerinden hemen önce gelenler tarafından yok edilmediği anlamına gelmelidir. Onları silseler, "gayret değil, mühür" ifadesini anlayamayız (s. 45). Bir hecenin bile söylenmesi biraz zaman aldığından ve ikinci kısmının birincisini silmesi mümkün olmadığından konuşmayı hiç algılayamıyorduk.
Bununla birlikte, ekolojik hafızada bile, görünüşe göre, silmeye benzer bir tür fenomen var. Yeni sesler, önceden sunulan seslerin saklanma süresini bir dereceye kadar maskeleyebilir veya azaltabilir (Massaro, 1972). Bu fenomene, ikonik bellekte daha net bir şekilde ifade edilen hızlı ve tam silmeden ayırt etmek için daha iyi girişim denir. Bu eko-parazit, Sperling'in deneylerinde harfleri yazdıktan sonra gösterdiği parlak alan efektine benzer - izleri kurtarmak için gereken süreyi azaltır, ancak izleri hemen yok etmez.
Eko-paraziti göstermenin bir yolu "ön ek etkisidir". Şekilde gösterilen iki eğriden 3.6, kulak tarafından sunulan küçük bir sıradaki konumlarına bağlı olarak çeşitli öğelerin çoğaltılmasındaki hataların sayısını yansıtır. Başka bir eğri, bu diziye "sıfır" sayısının önek olarak eklenmesiyle elde edilen sonuçları yansıtır. Deneklerin sıfıra tepki vermesi gerekmemesine ve sıfırın görüneceğini bilmelerine rağmen, bu durumda hatırlama, öğelerin ardından sıfır gelmediği kontrol deneyindekinden çok daha az etkiliydi.
Şekil 3 6. Küçük bir listedeki +.іѵхsitive'deki son hometel-ppstn ripa'nın hatırlanmasında sluloioL <pristaidn*'in etkisi. Izjaichal, özellikle vsshrokamde-ііii okullarında ioitrolech ile nіyr.i'tacі ancak sravіEn "isabet sıklığını ііrmst^ikn ettiğinde il hіgmeptov listesini yedi.
Ön ekin etkisi, bir önek eklenmesinin ekolojik izlerin korunmasına müdahale etmesiyle açıklandı (Morton, 1970): öznenin "sıfır" kelimesini telaffuz ederken duyduğu ses, zaten ekolojik bellekte bulunan bilgileri yok eder. ve serinin unsurlarını hatırlamaya yardımcı olabilir. Gerçekten de, bir ön ekin varlığında, doğru çoğaltma sıklığı, bir dizi görsel olarak sunulduğunda hatırlamaya karşılık gelen bir düzeye düşer: bu, ekolojik bellekte olan, yani kiplik etkisi yaratır, kaybolur.
Önek tarafından oluşturulan girişim derecesi, sonraki seslerin önceki seslere oranına bağlı olarak değişir (Morton a. o., 1971). Örneğin, bir öğe listesi bir erkek sesi ve bir önek bir kadın tarafından okunursa, önekin etkisi, hem listenin hem de önekin aynı sesle telaffuz edilmesine göre daha az belirgindir. Ön ek, listedeki öğelerden çok daha yüksek sesle telaffuz edilirse, etkisi yine azalır. Bu örnekler, önekin ses açısından listedeki öğelerden farklı olduğu durumlarda, oluşturduğu girişimin daha az belirgin olduğunu göstermektedir.
Modaliteye bağlı farklılıklar ve önek etkisi için verilen açıklamalar bir takım itirazları gündeme getirdi. Bağlanmanın yarattığı etkiler söz konusu olduğunda, bu tür etkilerin görsel alanda da ortaya çıkmasıyla ilgili bir zorluk vardır . Neisser ve Kahneman (bkz. Kahneman, 1973) deneklerden kendilerine görsel olarak sunulan kısa sayı dizilerini 0,5 saniye boyunca hatırlamalarını istedi. Bazen listenin sonuna deneklerin hatırlamaması gereken bir sıfır konurdu ( bu durumda bir dizi numara, ön ek olmadan "137526" sayısının aksine "1375260" gibi görünüyordu). Bu durumda, önek aynı etkiye sahipti - satırlar açıkça görülebilmesine ve denekler öneke dikkat etmemeleri gerektiğini bilmelerine rağmen üreme kötüleşti.
İşitme cihazlarının etkilerinin aksine, görsel bağlantıların etkilerini duyusal hafızanın özellikleriyle açıklamak zordur. Kahneman (1973, s. 133), tüm önek etkilerinin, kayıtlı girdileri gruplar halinde organize eden duyusal kaydı takip eden süreçlerden kaynaklandığını öne sürdü. Böyle bir gruplama ile “sıfır” yani önek diğer sayılardan ayrılamayacağından, özellikle aynı sesle telaffuz ediliyorsa, bir grup içinde yer alması gerekir ve bu dahil olma durumu zorlaştırır. serinin unsurlarını hatırlamak için. Bu nedenle Kahneman, işitsel bağlanmanın etkisini, ekolojik bellekteki bilgi silme mekanizmalarından bağımsız fenomenler olarak kabul eder.
Geri çağırma deneylerinde gözlemlenen modalitenin etkilerinin, ekotik ve ikonik izlerin korunma sürelerindeki farklılıklar temelinde yorumlanması da bir takım itirazları gündeme getirmektedir. Örneğin, Murdock ve Walker (Murdock ve Walker, 1969), işitsel sunum sırasında, listenin son öğelerinin hafızasının, bu öğelerin sunulduğu sürenin eko görüntülerin beklenen koruma süresini aştığı durumlarda bile geliştiğini belirtmektedir. . Ancak bu böyleyse, o zaman modalitenin etkisi tamamen ekolojik belleğe atfedilemez.
Bir başka sorun da (Watkins ve Watkins, 1973), kiplik etkisinin, bu sözcükler ister bir ister dört heceden oluşsun, listenin son birkaç sözcüğü için ortaya çıkmasıyla bağlantılı olarak ortaya çıkar. Bu nedenle, dizide işitsel sunumun avantajının bulunduğu yerler (her yere bir kelime karşılık gelir), bireysel öğelerin uzunluğuna bakılmaksızın her zaman aynıdır. Bu, elbette, bir satırdaki yerlerin sayısıyla ölçülen kiplik etkisinin süresinin, karşılık gelen öğelerin işitsel sunumunun ne kadar sürdüğünden etkilenmediği anlamına gelir (sonuçta, dört heceli kelimeler daha fazla zaman alır) sadece bir heceden oluşan kelimelerden daha fazla telaffuz edin) . Bu veriler, bu etkinin ekolojik belleğin özellikleriyle ilgili olmadığını, çünkü kelimelerin sunulma süresinin ekolojik görüntülerin korunmasını şüphesiz etkilemesi gerektiğini düşündürmektedir.
Az önce tartışılan eleştirilerin gösterdiği gibi, eko-hafıza teorileri eko-imgelerin doğasını tam olarak açıklamaz. Duyusal kayıtların incelenmesiyle bağlantılı olarak bir dizi daha genel problem de ortaya çıkar. Örnek olarak, ekolojik hafıza dediğimiz duyusal kayıt, kategori öncesi akustik depolama olarak da adlandırılır (Crowder ve Morton, 1969). "Kategori öncesi" terimi çok önemlidir - duyusal kayıtlarda bulunan bilgilerin içlerinde tanınan, kategorize edilmiş öğeler biçiminde değil, "ham" bir duyusal biçimde bulunduğunu gösterir. Görsel olarak sunulan uyaranlar içlerinde görsel görüntüler şeklinde bulunur, kulak tarafından sesler vb. algılandıktan sonra duyusal izler hızla kaybolur.
Duyusal kayıtların kategori öncesi doğasının burada vurgulanması gerekir, çünkü kayıt araştırmasındaki temel sorun, duyusal kayıtlardan kaynaklanan etkilerin tanınan bilgilerin olası etkilerinden ayrılmasıdır. Örneğin Sperling'in deneylerinde, bu ayırma, bir uyaranın sunulmasından hemen sonra alıkonabilen bilgi miktarı ile birkaç saniye boyunca alıkonan bilgi miktarının karşılaştırılmasıyla sağlandı. Eko-imge ile yapılan deneylerde, bazen deneklere tanıyamadıkları bilgiler, örneğin arka plan gürültüsüne karşı kelimeler sunularak böyle bir ayırma girişiminde bulunuldu ve bunun belki de birincil duyusal verilerin işlenmesini tamamen ortadan kaldırmadığına dikkat çektik. . Bunun olası sonuçları, eko-imgelerin korunma süresinin fazla tahmin edilmesini ve önek etkisinin yanlış yorumlanmasını içerebilir.
Daha genel olarak, hafızayı incelerken, bilginin depolandığı biçimi, kodlanma şeklini belirlemenin genellikle önemli olduğu söylenebilir. Aynı sözcük bellekte ses biçiminde, grafik biçiminde, etiket olarak ya da karmaşık bir anlam kümesi olarak saklanabilir. Çoğu zaman, psikolothlar sözlü etiketler biçimindeki bilgilerin depolanmasını diğer herhangi bir koddan ayırmak isterler. Örneğin, bazı araştırmacıların sözlü depolama ile ne duyusal ne de sözel olmayan görsel depolama arasında ayrım yapmaya çalıştıklarını göreceğiz. Bir kişi gördüklerini ve duyduklarını kelimelerle tarif edebilir. Bilgiyi depolamak için dili kullanmaktaki tek başına kişinin bu doğal yeteneği, hatırlanacak materyali birkaç farklı şekilde kodlamayı mümkün kılar: bu nedenle, farklı kodlar arasında ayrım yapmak önemli hale gelir. Hafızanın teorik çalışmasında problem.
Bölüm 4
Desen tanıma
Şu ya da bu görüntüyü tanıyarak, bazı duyusal verilerden anlam çıkarıyoruz. Örüntü tanıma süreci, gerçek dünya ile öznenin zihni arasındaki etkileşimin bir parçasını oluşturduğu için davranışımız için temeldir. Bu görüntüyü tanımak için, bir bellek deposundaki, duyusal kayıttaki bilgi, başka bir depodaki, uzun süreli bellekteki bilgilerle karşılaştırılmalıdır. Birinci türden bilgi, bir uyarıcı şeklinde henüz geldi; ikinci türden bilgi, bu uyarıcı hakkında daha önce edinilmiş bilgilerden oluşur. Örneğin, bize üç satırdan (/, \ ve -) oluşan bir uyaran sunulursa, içindeki A harfini tanırız. Bu durumda, bu uyarana bir veya daha fazla kelimeden bir ad verebiliriz ( örneğin, "bu A harfidir" ). Örüntü tanıma her zaman sözlü formülasyon anlamına gelmez; genellikle görüntüleri adlandırmadan tanırız (örneğin, belirli bir yüzü tanıdık olarak tanıyabiliriz; belirli bir koku bize onu kokladığımız bir yeri hatırlatabilir). Öyle ya da böyle, duyulardan gelen bilgiler (konturlar, yüzler, kokular vb. hakkında) çevremizdeki dünya hakkında bildiğimiz her şeyle karşılaştırılır ve ilişkilendirilir.
Örüntü tanıma çalışmasının hafıza çalışmasının önemli bir parçası olduğunu anlamak kolaydır.Birincisi, duyusal kayıtlar ve uzun süreli hafıza (D11) gibi bilgi depolarının incelenmesi ile ilişkilidir. İkinci olarak, örüntü tanıma sürecini tartışırken, hafızada depolanan malzemenin temsilinin doğasını - hafızanın bilgi kodunu - açıklığa kavuşturma ihtiyacıyla karşı karşıya kalacağız. (Genel olarak, belleğin "kodu", bilginin onda temsil edilme biçimini ifade eder.) Son olarak, bellek koduyla ilişkili bazı süreçleri ele alacağız. İlk önce herhangi bir model veya örüntü tanıma teorisinin hangi genel özelliklere sahip olması gerektiğini tartışırsak, tüm bunlar daha net hale gelecektir.

Basitleştirilmiş bir örüntü tanıma şeması, Şek. 4.1. Görüldüğü gibi bu süreç birkaç aşamadan oluşmaktadır. Her şeyden önce, algılanacak uyaran duyusal kayda girer. İz burada çok kısa bir süre kaldığından, kayıtta uyarıcıya ilişkin bilgi varken tanıma işleminin hızlı bir şekilde tamamlanması gerekir. Tanıma sürecinin kendisi, girdi uyarıcısının LTP'deki kodlanmış bilgiyle karşılaştırılmasından oluşur; bu, LTP'deki bilginin, uyarıcının onunla karşılaştırılabileceği bir biçimde sunulması gerektiği anlamına gelir. Başka bir deyişle, DP'de depolanan uyaranın kodlanmış temsili, bir anlamda bu uyarana benzer olmalı veya bir şekilde onun görünümünü veya biçimini tanımlamalıdır. Girdi uyaranını DP'de yer alan kodlarla karşılaştırdıktan sonra, bu iç kodların hangisinin verilen uyaranla en iyi eşleştiğine karar verilir. Tanıma sisteminin çıkış sinyali bu karara bağlıdır - alınan kararın sonucu hakkındaki mesaj, elbette, görüntü tanındıktan sonra, bununla ilgili ek bilgiler DP'den çıkarılabilir. Örneğin, sunulan uyarandaki A harfini tanıdıktan sonra, onun hakkında bildiğimiz her şeyi hatırlayabiliriz: bu, alfabenin ilk harfidir; "karpuz" kelimesi bu harfle başlar; birinci sınıf futbol takımları vb. için atamadır.
Böylece, örüntü tanıma sürecinin birkaç karmaşık alt süreçten oluştuğunu görüyoruz. Bu öncelikle bir önceki bölümde tartışılan duyusal kayıttır. Ardından karşılaştırma ve karar verme süreci gelir. Bu, bilgilerin sunumuyla ilgili sorunları gündeme getirir. Giriş uyarıcısının karşılaştırıldığı DP'de depolanan bilgi hangi biçimde kodlanır? Kodlanmış uyaran orijinaline ne kadar benziyor? Bu bölümün geri kalan kısımlarında, hafıza kodunu ve bir örüntü tanıma sistemi için öne sürülebilecek bazı karşılaştırma ve karar süreçlerini ele alacağız.
HAFIZA KODLARI VE TANIMA
STANDARTLAR
Bellek kodlarını incelememize, geçmiş deneyimleri yeni gelen uyaranlarla karşılaştırırken kullanılan DP kodlarıyla başlayacağız. Bu kodlar nelerdir? Kod ya verilen uyarana karşılık gelmeli ya da onu tanımlamalıdır, aksi takdirde karşılaştırma için bir model olamaz. Olası bir hipotez, LTP'de depolanan kodun, verilen uyaranın minyatür bir kopyası (veya "referansı") olmasıdır; LTP'de tanıdığımız her uyaran için, tanımada kullanılan dahili kopyası vardır. Bu hipoteze göre, bir görüntüyü tanımak için, belirli bir uyaranı LTP'de depolanan uzun bir dizi standartla karşılaştırmak gerekir. Tanıma, verilen bir uyaran için en uygun standardın seçildiği anda gerçekleşecek ve böylece bu uyaranın ne olduğu belirlenecektir.
Ancak kıyaslama hipotezi çok basittir; örüntü tanıma teorisine temel teşkil edemeyecek kadar saftır. Ana dezavantajı, çok sayıda gerekli standarttır. Örneğin, çok karmaşık olmayan bir uyaranın, A harfinin tanınmasını düşünün. Kıyaslama hipotezine göre, DP'de bu harfin bir kopyası vardır ve A'ya benzer herhangi bir uyaran göründüğünde onunla karşılaştırılır ve bu, onunla diğerlerinden daha iyi eşleşen referans. Bununla birlikte, A harfinin her varyasyonu için ayrı bir standarda ihtiyacımız olduğu sonucu çıkar. Uyarıcının büyüklüğü değişti mi? Başka bir standarda ihtiyacımız var. Harfi hafifçe döndürürseniz, başka bir standarda ihtiyacınız olacaktır. Bir tür stil için, örneğin A, yine kendi özel standardınıza ihtiyacınız olacak. A harfinin tüm bu çeşitleri için standartlarımız yoksa, tanıma sırasında kaçınılmaz olarak hatalar meydana gelecektir. Örneğin, eğik A'nın R standardına A'dan daha iyi karşılık geldiği ortaya çıkabilir ve sonra A ile karşılaştığımızda onu R olarak tanırız. Bu tür hataların olasılığını dışlamak için sayısız standart seti olacaktır. şüphesiz DP'nin kaldırabileceğinden çok daha fazlasına ihtiyaç var. .
Kıyaslama hipotezi, onu çok daha kabul edilebilir kılmak için değiştirilebilir. Bir değişiklik, modele eşleştirmeden önce gelen ve giriş uyarıcısını "temizlemeye" hizmet eden bir süreç eklemektir. Bu tür bir ön işleme, uyarana standart bir konum ve standart boyutlar verebilir. Uyaran şeklindeki çeşitli düzensizlikleri ortadan kaldırdığı ve onu daha normal bir forma getirdiği için bu işleme "normalizasyon" adı verilir. Örneğin, uyaran şu şekle sahip olsaydı, normalleştirme sonucunda azalır, eğri sağ taraf düzleşir ve tüm bunlar uyaran standartla karşılaştırılmadan önce gerçekleşirdi. Böyle bir süreç, A harfini tanımak için gereken standartların sayısını büyük ölçüde azaltacaktır.
Bununla birlikte, karşılaştırmadan önceki normalizasyon, referans hipoteziyle ilgili tüm zorlukları ortadan kaldırmaz. Mantıksal olarak şu itiraz ortaya çıkar: Uyarıcının doğru yönünü ve büyüklüğünü bilmek için, verilen uyarının hangi görüntüyü temsil ettiğini önceden bilmek gerekir. Örneğin, eğik bir Q gibi görünen bir uyaran hangi yönelime sahip olmalıdır? Bir durumda P, diğerinde Q gibi görünecektir. Bu iki dönüşten hangisinin doğru olacağını bilmek için önce hangi harf olduğuna karar vermelisiniz. Ancak bu görev, kendisinden önceki dönüştürücüye değil, tanıma sistemine atanır. Ancak bu mantıksal sorunun üstesinden gelmek zor değil. İlk olarak, uyaranın standart yönelimden keskin sapmaları ile, büyük olasılıkla şu şekilde ortaya çıkacaktır: tanınmaz. Başka bir deyişle, eğer tanıma sistemi gerçekten bu tür bir uyaranla başa çıkamıyorsa, bu ön sürecin oldukça eğimli bir Q'yu işleyebileceğini varsaymaya gerek yoktur. İkincisi, tanınacak uyaranlar genellikle daha geniş bir bağlamda yer alır ve bu bağlam, verilen uyaranın konumunun veya büyüklüğünün nasıl değiştirilmesi gerektiğini önererek normalleştirme sürecine yardımcı olabilir.
Daha genel olarak, bağlam, belirli bir uyaranın eşleşebileceği kalıp sayısını azaltarak tanıma sürecine büyük ölçüde yardımcı olur. Ayrıca bağlam, tamamen yeni uyaranları tanımak gibi sorunları çözmeyi kolaylaştırır. Böyle bir uyarıcıyı daha önce hiç görmemiş gibi nasıl tanırız? DP'de karşılık gelen standartların olamayacağı oldukça açıktır. Böyle bir uyaranın nasıl fark edildiği, onunla ne zaman ve nerede karşılaştığımıza bağlıdır. Alfabedeki harflerin tanınması tartışılırken ortaya çıkarsa, böyle bir karikatürde karşılaşırsak, muhtemelen A harfi olarak algılanacaktır:
bize A gibi görünmesi pek olası değil.
PROTOTİPLER
Bağlam, örüntü hipotezinin doğasında var olan bazı zorluklarla başa çıkmamıza yardımcı olabilir, ancak sorunu tamamen çözmez. Gerçek şu ki, tanıyabildiğimiz birçok uyaran bize özel bir bağlamın dışında görünür ve yine de boyut ve yön farklılıklarına rağmen onları tanırız.
Bu bakımdan, görünüşe göre, içinde yer alan görüntülerin bazı varyasyonlarına veya "belirsizliğine" izin veren böyle bir referans sistemine sahip olmak gereklidir. Başka bir deyişle, tanıyıcı, uyaranın "temizlenmesinden" sonra kalabilecek küçük varyasyonların varlığında da iyi çalışmalıdır. Varyasyonlara izin veren standartların tanıyıcıya girmesinden sonra, sistem sözde prototip sistemine veya şemalara dayalı bir sisteme daha benzer hale gelir.
Şema, bir prototip oluşturmak veya tanımlamak için basit bir kurallar dizisidir; burada bununla, bir dizi uyarıcının temel öğelerini temsil eden soyut bir figürü kastediyoruz. Örneğin, bir prototip uçak, iki kanadın bağlı olduğu uzun bir tüp olarak düşünülebilir; tüm uçaklar bu prototipin farklı versiyonları olacak. Başka bir deyişle, bir prototip, belirli bir öz, belirli bir ana veya orta eğilim, isterseniz Platonik bir "fikir" dir. Örüntü tanımanın prototip hipotezine göre, prototipler DP'de saklanır - bilinen bir uyaran setinin genelleştirilmiş, idealleştirilmiş örnekleri. Teorik olarak, herhangi bir uyaran, bir varyasyon listesiyle birlikte bir Trototip olarak kodlanabilir, ardından gelen tüm uyaranlar standartlarla değil prototiplerle karşılaştırılabilir. (Böylece, burada standart kavramı yerini prototip kavramına bırakmıştır). Uzun süreli belleğimizin, tanıdığımız tüm kategorilerin - köpekler, insan yüzleri, A harfleri vb. - prototiplerini içerdiği varsayılır ve bu, bu kategorilerin bireysel temsilcilerini tanımamıza olanak tanır.
Prototipler gerçekten var mı? Bazı deneysel verilere bakılırsa, bu soru olumlu olarak yanıtlanabilir: Uyaran grupları için prototip oluşumuna ilişkin bilinen durumlar vardır. Örneğin, Posner ve Keel (Posner ve Keel, 1968), deneklerin prototip geliştiriyormuş gibi davrandıkları bir deney yürüttüler. Her şeyden önce, Posner ve Keel, her biri 9 noktadan oluşan prototip görüntüler oluşturdu. Bazı durumlarda, bu noktalar üçgen gibi geometrik bir şekil şeklinde, diğerlerinde - bir harf şeklinde, diğerlerinde - rastgele yerleştirildi. Daha sonra, bazı noktaları hafifçe kaydırarak, deneyciler aynı prototiplerin yeni şekiller-çarpık formlarını yarattılar (Şekil 4.2, A). Bazen noktalar bir yönde, bazen başka bir yönde hareket ediyordu, böylece orijinal prototip, her noktayı tüm sapmalara göre orta konuma yerleştirdiğimizde ortaya çıkacak şekle karşılık geliyordu. Her birinin prototiplerini ve çeşitli çarpıtmalarını yaratan Posner ve Keel, birkaç konu grubu üzerinde deneylere başladı. Prototiplerin rastgele nokta gruplamaları olduğu bir örneği ele alalım; Bu durumda prototiplerden sapmalar da elbette rastgele kümelerdi. Deneklere ilk önce (birbiri ardına) üç rastgele prototipin her birinden dört sapma gösterildi. Her sapmayı sınıflandırmaları, yani üç kategoriden hangisine ait olduğunu belirtmeleri istendi. Bir prototipe karşılık gelen tüm sapmaların aynı kategoriye atanması gerekiyordu, ancak deneklere prototiplerin hiçbiri gösterilmedi. Sonunda, denekler şekilleri doğru bir şekilde sınıflandırmayı, yani bir prototipten tüm sapmaları bir kategoriye, diğerinden tüm sapmaları diğerine atfetmeyi vb. öğrendiler.Ardından deneklere yeni bir sınıflandırma görevi verildi. Onlara bir dizi şekil sunuldu ve her birini önceden belirlenmiş üç kategoriden birine atamaları istendi. Bu figürlerin bazılarını denekler daha önce görmüşlerdi (bilinen sapmalar), diğerleri aynı prototipin yeni çarpıtmalarıydı ve yine diğerleri de deneklerin daha önce görmediği prototiplerin kendileriydi. Beklendiği gibi, bilinen sapmalar oldukça iyi sınıflandırıldı - doğru cevapların sıklığı% 87 idi. Şaşırtıcı bir şekilde, denekler onları daha önce hiç görmemiş olsalar da, prototipler de yaklaşık olarak sınıflandırıldı. Bununla birlikte, deneklerin ilk kez gördüğü yeni sapmalar daha az doğru bir şekilde sınıflandırıldı - buradaki doğru cevapların sıklığı zaten yalnızca% 75'ti. Prototiplerin sınıflandırılmasının yüksek doğruluğu göz önüne alındığında, yazarlar, birinci sapma grubunu sınıflandırmayı öğrenen deneklerin aslında prototipleri öğrendiği görüşünü ifade ettiler. Başka bir deyişle, denekler, o prototipin varyasyonları olan bir dizi uyarandan ortalama bir eğilimi - bir prototip fikri - soyutladılar.

Benzer türden diğer deneylerde, prototip teorisi lehine daha da güçlü argümanlar elde edildi. Franks ve Bransford (Franks ve Bransford, 1971), birkaç geometrik şekilden (üçgen, daire, kare vb.; Şekil 4.2, B) yapısal gruplar oluşturarak prototipler yarattı. Ardından, prototipin bir veya daha fazla dönüşümü ile ondan sapmalar elde edildi. Dönüşüm, örneğin, belirli bir gruptan bir figürün çıkarılmasını, onun yerine başka bir figürün konulmasını vb. içerebilir. Deneklere önce birkaç sapkın görüntü gösterildi ve ardından bir tanıma testi yapıldı. Bunu yaparken, onlara bir dizi görüntü sunuldu - daha önce gördükleri birkaç çarpıtma, daha önce görmedikleri birkaç çarpıtma ve prototipler - ve her birini tanıyıp tanımadıkları soruldu. Her denemede denekler, verilen görüntüyü orijinal sette görüp görmedikleri konusunda ne kadar emin olduklarını da belirtmek zorundaydı. Görünür geçerliliğe ilişkin bu tahminlerin gösterdiği gibi, denekler, deneyin ilk bölümünde prototipler kendilerine gösterilmemiş olsa da, prototipleri daha önce gördüklerine en "emin" idiler. Ayrıca, bir veya başka bir seçeneğin prototipe yakınlık derecesine bağlı olarak, deneklerin güven derecesini tahmin etmek mümkün oldu. Prototiplerin "tanınmasında" en iyisiydi; onları yalnızca bir, ardından iki ve benzeri dönüşüme uğrayan yapısal gruplar izledi. Daha önce görülen varyantlar, prototipten aynı sayıda dönüşümle ayrılan yeni varyantlardan daha iyi tanınmadı.
Bu deneylerin sonuçlarına bakılırsa, bir grup yakın figürle tanışmak, bu grubun prototipik bir fikrinin geliştirilmesine yol açar. Bu gibi durumlarda deneklerin belirli bir prototip görseli gördükleri figürlerden soyutladıkları söylenmektedir. Franks ve Bransford'un deneyi, deneklerin yeni görüntüleri tanımlarken bu tür prototipleri kullanabileceklerini de öne sürüyor. Belirli bir görüntüyü tanımadaki başarı veya başarısızlık, prototipin bozulma veya dönüşüm derecesine göre belirlendi ve bu rakamın daha önce sunulup sunulmadığı önemli değildi.
Bu nedenle, örüntü tanımanın prototip teorisine göre, insan DI, her tür bilgi için örneğin harflerin, yüzlerin veya noktalardan oluşan şekillerin prototipleri için görüntülerin prototiplerini depolar. Yeni bir görüntüyle karşılaşıldığında, tanıma sistemi onu bu prototiplerle karşılaştırır ve kesin (referans) değil, uyaranın bazı değişkenliklerine izin veren yaklaşık bir karşılık geldiğini kontrol eder. Belirli bir uyarana en iyi hangi prototip uyacaktır, böyle bir görüntü bu uyaranda tanınacaktır. Uyaran ön işleme mekanizmasını da içeren böyle bir model, naif referans hipotezine göre önemli bir ilerlemeyi temsil eder.
GÖRÜNTÜ ÖĞELERİ
Şimdiye kadar, "örüntü" kelimesini tanımlamadan örüntü tanımaya baktık; bu elbette ciddi bir eksikliktir. Bir tanıma göre (Lusne, 1970), görüntü, bir bütünü oluşturan birkaç öğenin konfigürasyonudur. Böyle bir tanım, herhangi bir görüntünün daha basit öğelere ayrılabileceğini ve bu öğeler yeniden birleştirildiğinde görüntünün yeniden ortaya çıkacağını ima eder. Örneğin, alfabedeki harflerin dikey çizgiler, yatay çizgiler, 45 derecelik çizgiler ve eğriler gibi unsurlardan oluştuğunu düşünebilirsiniz. Bu açıdan bakıldığında, A harfi / artı \ artı - olarak temsil edilebilir. Bu öğeler, uygun kombinasyon halinde, A harfinin görüntüsünü verir. Genel olarak, öğeler kavramı veya temel işaretler, çeşitli kombinasyonlarda alınan nispeten küçük bir basit parça kümesinden oluşturabileceğiniz gerçeğine iner. tüm resimler daha güçlü bir kümeye dahil edilmiştir (örneğin , alfabenin basılı harfleri kümesi).
Daha basit öğelerden ("özellikler") oluşturulabilen çok sayıda görüntünün bir başka örneği de sözlü konuşmadır. Konuşma, görsel olarak sunulan kelimeleri oluşturan, fonem adı verilen ve harflere benzeyen temel ses birimlerinden oluşur. Bir fonem, ayrı bir öğe olarak değişerek bir kelimenin anlamını değiştirebilen bir ses olarak tanımlanabilir. Örneğin, orman, ağırlık ve iblis kelimelerindeki l, c veya b harflerine karşılık gelen sesler farklı fonemleri temsil eder, çünkü bu seslerin her biri konuşulan kelimenin anlamını değiştirir. Bir fonem birçok akustik değişkenle temsil edilebilir, çünkü her kişi onu diğerlerinden biraz farklı telaffuz eder, ancak yine de aynı fonemi farklı kişiler tarafından telaffuz edildiğini anlarız. Bütün bunlar, ses birimini bir konuşma birimi, birçok benzer sesi birleştiren bir tür soyutlama olarak düşünebileceğimiz anlamına gelir. Bu anlamda, her insanın biraz farklı gösterdiği, ancak yine de her zaman tanınmayı başaran el yazısı bir mektupla karşılaştırılabilir.
Fonem üretmek için çeşitli kombinasyonlarda kullanılabilecek bir dizi özellik bulmak (tıpkı harfleri yazdırmak için temel olarak düz ve eğri çizgileri ve açıları kullanabileceğiniz gibi) çok zor bir sorundur, ancak bunu çözmek için birkaç girişimde bulunulmuştur. Yöntemlerden biri, seslerin artikülasyon mekanizmasını keşfetmeye ve her konuşma sesini, bir kişinin telaffuz ederken konuşma aparatını nasıl kullandığına göre tanımlamaya çalışmaktır. Konuşma aparatı dil, burun, dişler ve dudaklar, ses telleri ve diyafram kaslarını içerir.
Örneğin, siz seslerini düşünün. Her birini telaffuz etmeyi dene ve fark edeceksin ki z telaffuz edilirken ses gırtlaktan geliyormuş gibi görünürken s telaffuzunda sadece ağız devreye giriyor . Bu temelde, sesler sağır ve sesli olarak ayrılır: c - sağır bir ses, telaffuz edildiğinde ses telleri hareketsizdir; h - sesli bir ses, telaffuz edildiğinde ses telleri titreşir. Bu nedenle, bu iki sesin bir özellikte farklı olduğunu söylüyorlar - sonority. Elbette konuşma seslerinin başka birçok özelliği daha vardır. Bunlar, dilin ağız boşluğundaki konumunu (ön, orta veya arka), havanın burundan veya sadece ağızdan geçişini ve diğerlerini içerir. Her ses biriminin, bu tür özelliklerin benzersiz bir kombinasyonuna - bunun için konuşma aparatının bazı özel konfigürasyonlarına - karşılık geldiği varsayılmaktadır. Konuşma artikülasyonunu keşfederek, her bir ses birimini karakterize eden bir dizi öğeyi belirlemeye çalışırlar.
Konuşma seslerinin veya basılı harflerin ayırt edici özelliklerini belirlemeye yönelik tüm çabalara rağmen, bazı sonuçlar tatmin edici sayılabilecek olsa da, tam bir başarı elde edilememiştir. Bununla birlikte, görüntüleri bir dizi temel özellik kullanarak tanımlama olasılığı fikri çok çekici görünüyor. Ayırt edici özelliklerine dayalı olarak İngilizce fonemlerin oldukça ayrıntılı bir tanımlaması üzerinde çalışılmıştır (Jakobson a.o., 1961); belirli bir tipteki yazı tipleri için farklı basılı harflerin temel işaretlerini oluşturmak da mümkündür (Rumelhart, 1971). Örneğin, alfabenin harfleri yalnızca dikey ve dikey kullanılarak tanımlanabilir.
ben vs...
' ... gibi stilleri kabul edersek yatay çizgiler
Bu nedenle, önce naif referans hipotezini düşündük ve onun tamamen uygunsuz olduğunu belirledik. Bununla birlikte, ön işleme sürecini (girdi uyarıcısında küçük bir değişiklik, ona standart bir boyut ve konum vererek) ve bir prototip kavramını eklersek, o zaman referans sisteminden çok daha iyi bir model oluşturabileceğimizi bulduk. . Şimdi döneceğimiz referans hipotezine bir başka alternatif, özellik hipotezidir. Bu hipoteze göre, tanınacak uyaranın önce bireysel özellikleri analiz edilir. Sonuç olarak, kombinasyonları belirli bir uyaranla sonuçlanacak olan özelliklerin bir listesi derlenir. Bu liste daha sonra DP tarafından tutulan listelerle karşılaştırılır. Bu nedenle, belirli bir uyaran için DP kodu, bir standart veya prototip değil, bir özellikler listesidir.En uygun liste seçilir, bu da örüntü tanımaya yol açar.
Özellik analizine dayalı teorik modellerden biri de Pandemonium sistemidir (Selfridge, 1959). Bu sistem şek. 4.3. Genel modelimizde olduğu gibi (Şekil 4.1), burada örüntü tanıma sürecinin birkaç aşamadan veya seviyeden oluştuğu varsayılmaktadır.
YAYSLSNSY DvMONA
cehalet belirtileri

Pirinç. 4.3. Selfridge tarafından özellik tanıma modeli
olarak önerilen Pandemonium sistemi . Duyu organlarından gelen uyarılar
görüntünün isimleri ile kaydedilir. Özellik çıkarma a ita*
iblisleri onu parçalıyor. öğrenmek için Hangi işaretlere sahip olduğu, tanımlama dechoyas
seçilen işaretleri görüntüleri ile karşılaştırır. DD
Kararı kabul ettiğim nihayet belirlendi. SRotetstuet'nin hangi görüntüsü
yok oldu?
Her seviyede, sunulan görüntünün tanınmasıyla ilgili şu veya bu işi yapan "şeytanlar" müfrezesi vardır. Birinci seviyede, duyusal kayıt dediğimiz şeyle meşgul olan, yani uyaranı duyusal seviyede bir olay olarak kaydeden görüntü iblisleri çalışır. Bu olay daha sonra, birincil görüntüyü bileşen öğelerine ayıran özellik çıkarma arka plan programları tarafından ayrıştırılır. Bu türden her iblis, görüntüde yalnızca bir özellik arar - belirli bir açıda bulunan belirli bir düz çizgi veya bir eğri - ve bulursa kaydeder. Özellik çıkarma cinleri, özellik listelerine karşılık gelen tanıma cinleri tarafından izlenir. Bu iblislerin her birinin sahip olduğu liste, belirli bir görüntüye atıfta bulunur ve bu iblisin işi, "bağırmak" veya sinyal vermektir, ne kadar yüksek sesle, sonuç olarak vurgulananlar arasında o kadar "onun" işaretlerini bulur. analiz. Son olarak, en üst düzeyde karar verme iblisi (karar verme süreci) oturur; tanımlama iblislerinden hangisinin en yüksek sesle çığlık attığını belirlemeli ve sonuç olarak görüntüyü tanımalıdır.
Özellik hipotezi örüntü hipotezine çok benzediğinden, tüm bu akıl yürütmenin tanıdık gelmesi şaşırtıcı değildir. Nitekim özünde her işaret belli bir ölçüdür; sadece bu durumda standart, uyaranın tamamına değil, yalnızca bir kısmına karşılık gelir. Özellik hipotezinin avantajı, çok daha geniş bir görüntü yelpazesini tanımlamanıza izin veren bir dizi özellik seçebiliyorsanız (örneğin, birkaç temel özelliği kullanarak konuşmayı tanımlayın), o zaman uğraşmanız gereken standartların sayısıdır. keskin bir şekilde azalır. Bununla birlikte, özellik hipotezinin örüntü hipotezine benzerliği, her ikisinde de ortak olan birçok sorunu beraberinde getirir.
Örneğin, özellik tabanlı bir sistem, belirli bir görsel öğenin büyüklüğündeki değişimlerle nasıl başa çıkabilir? Daha önce hiç görülmemiş yeni işaretleri nasıl tanıyacak? İki uyaran yalnızca bazı öğelerin varlığında veya yokluğunda farklılık gösterirse ne olur? Bir örnek, E harfinin sahip olduğu ancak F'nin olmadığı alt yatay çizgi olacaktır. Bu durumda, F harfinin tüm öğeleri özelliklere karşılık geldiğinden, F uyaranının tanınması için uygun iki özellik listesi DP'de bulunabilir. E ve F için olduğu gibi listelerde yer alır. Konuşma öğelerinin tanınması durumunda daha da büyük zorluklar ortaya çıkar. Her şeyden önce, belirli bir konuşma biriminin tam olarak nerede başladığı veya bittiği her zaman net olmaktan uzaktır, bu da görüntüyü ayrı özelliklere bölmeyi çok zorlaştırır. Bilmediğiniz bir dilde bir konuşmayı dinleyin: Size o kişinin inanılmaz derecede hızlı konuştuğu gibi görünecek ve bir kelimenin nerede bitip diğerinin nerede başladığına karar vermek neredeyse imkansız olacaktır. İngilizce konuşan insanları dikkatle dinlersek, genellikle bir kelimenin ortasında iki kelime arasında olduğundan daha uzun duraklamalar yaptıklarını görürüz.
Şimdiye kadar, örüntü tanıma ile ilgili tüm bu sorunları nihai olarak çözme fırsatımız olmadı. Ancak bu, özellik analizine dayanan hipotezin atılması gerektiği anlamına gelmez. Sonuçta, diğer tüm hipotezlerin de dezavantajları vardır. Ayrıca özellik eşleştirme yönteminin gerçekten de tanımada kullanıldığını gösteren çok sayıda deneysel sonuç bulunmaktadır.
Örüntü tanımada özellik analizinin rolüne ilişkin bazı veriler fizyolojik niteliktedir. Örneğin, görsel sistemin, işlevleri belirli özellikleri tanımak olan özelleşmiş hücreler içerdiği gösterilmiştir. Son 10-15 yılda, fizyologlar (Hubel ve Wiesel, 1962; Lettvin, a.o., 1959) kedilerin, kurbağaların ve diğer hayvanların görsel sistemlerinde yalnızca belirli türden görsel uyaranlara yanıt veren sinir hücreleri keşfettiler. Bunlar örneğin yatay, dikey veya hareketli çizgiler olabilir. Bir kurbağanın beynindeki bazı hücrelerin, görme alanında hareket eden siyah noktaların görünümüne tepki gösterdiği; bu hücrelerin "sinek dedektörleri" olduğu ileri sürülmüştür: tepkileri kurbağanın yiyecek almasına yardımcı olur! Özel nöronları ateşleyen uyaranlar ile bizim burada işaret dediğimiz şeyler arasında açık bir benzetme vardır. Bir kişinin ayrıca, duyusal materyalin belirli unsurları ortaya çıktığında boşaltılan ve görsel sistemde özellik analizcileri rolü oynayan hücrelere sahip olduğu varsayılabilir. Görünüşe göre , bazı hücreler, uyaranın uzunluk gibi belirli özelliklerinden bağımsız olarak yanıt verir. Daha soyut özellikler için dedektör görevi görebilirler (örneğin, belirli bir açıda bulunan herhangi bir uzunluktaki bir çizginin varlığını algılamak için); belki de bu, boyutlarına vb. bakmaksızın neden görüntüleri tanımayı başardığımızı anlamamıza yardımcı olur.
Görsel örüntü tanımada özelliklerin önemli rolüne tanıklık eden başka veriler de vardır. Örneğin küçük çocuklar genellikle b ve d harflerini karıştırırlar. Bunun, yönelimleri dışında her yönden benzer olan iki öğeyi (örneğin, s ve e) ayırt edememelerinin bir sonucu olması mümkündür. Yetişkinlerde de benzer bir etki, görsel uyaranların algının eksik olabileceği bir hızda sunulmasıyla elde edilebilir. Bunun gibi deneylerde denekler, hafıza ölçüm deneylerinde yaptıklarıyla aynı türden hatalar yaparlar. Örneğin, çok kısa bir süre için bir harf sunulduğunda ve ardından özneden bu mektubu adlandırması istendiğinde, genellikle sunulan harf yerine başka bir harfin adını verir. Görünüşe göre işitsel özellikler açısından benzerlikten kaynaklanan hafıza miktarını belirlemede yapılan hataların aksine, bu tür deneylerdeki hatalar görsel benzerlikten kaynaklanmaktadır (Kippey a. o., 1966). Onlarda D, B yerine Q yerine çok daha sık çağrılır. Q ve D harflerinin görsel özellikleri ortaktır, D ve B ise işitme açısından benzerdir, ancak görünüş olarak çok farklıdır. Bu tür hataların doğası, harflerin görsel algısının işaretlerin analizine dayandığını düşündürür.
Söylenenlerden, hem prototipleme hem de özellik analizi lehine kanıtlar olduğu görülebilir. Ayrıca, örüntü tanımada pek çok şeyin her iki hipotezin yardımıyla açıklanabileceğini, ancak aynı zamanda pek çok sorunun (ve aynı problemlerin) her iki hipotezle de çözülemeyeceğini gördük. İki hipotezden hangisi daha iyi? Bu aşamada bu sorunun cevabı belirsizliğini koruyor. Bazı durumlarda her iki hipotezin de doğru olması mümkündür, çünkü tanıdığımız çok çeşitli uyaranlar nedeniyle, onları tanıma mekanizmaları farklı olabilir. Üstelik prototip dediğimiz özellikler ile özellikler arasındaki farkların göründüğü kadar büyük olmaması da mümkündür. İlk olarak, bu iki kavram birleştirilebilir: bir prototipin, belirli bir görüntünün tüm gerçekleştirmelerinde ortak olan özelliklerden oluştuğu düşünülebilir; böylece prototip fikri, standartlarla olduğu kadar özelliklerle de uyumlu hale gelir. İkincisi, bir düzeyde, özellik tabanlı hipotezin örüntü hipotezine çok benzediğini anlamak önemlidir. Bir özellik hipotezini formüle ederken ortaya çıkan sorunlardan biri, belirli bir açı oluşturan çizgiler gibi bireysel özelliklerin nasıl tanındığı ile ilgilidir. Burada, bir özelliği dahili bir standartla karşılaştıran bir karşılaştırma sürecini varsaymak gerekli olabilir. Sonuç, bir özellik tanıma referans teorisidir! Bu düşünceler, örüntü tanımada kullanılan D11'deki kodlama türünü doğru bir şekilde belirlemeye çalışırken ortaya çıkan bir dizi zorluğu göstermektedir. Bu kodu tam olarak tanımlayamasak da, bununla ilgili akıl yürütmemizde, naif örüntüler hipotezine kıyasla önemli ilerlemeler kaydettik, bunu yaparken dekognisyon sürecine ilişkin bir takım önemli noktaları açıklığa kavuşturduk.
TANIMA İLE İLGİLİ SÜREÇLER
Örüntü tanımada henüz ayrıntılı olarak tartışmadığımız bir adım vardır ve bu, karşılaştırma ve karar verme sürecidir. Bununla bağlantılı olarak standartlar hipotezini düşünün. Her görüntü çok sayıda standartla karşılaştırılmalı ve ardından verilen uyarana en uygun standart seçilmelidir. Bellekte saklanan çok sayıda standart göz önüne alındığında, böyle bir karşılaştırmanın çok külfetli ve zaman alıcı bir prosedür olacağı açıktır. Bir karar verilmeden önce binlerce standardın ayıklanması gerekirdi. Bütün bunlar nasıl yapılabilir? Tanıma mekanizması, giriş uyaranını sırayla her referansla karşılaştıracak olsaydı, o zaman bazı uyaranların tanınması çok uzun zaman alırdı; "referanslar"ın yerine geçiyorlarsa, "prototipler" veya "özellik listeleri" için de aynı hususlar geçerlidir. Bu arada, görüntülerin çok hızlı tanındığını biliyoruz.
SIRALI YA DA PARALEL İŞLEME?
Bu sorunun cevaplarından biri, tanıma mekanizmasının yeni uyaranları LTP'de depolanan tüm kodlarla tek tek veya dedikleri gibi sırayla karşılaştırmaması olabilir. Diğer bir olasılık, aynı anda birçok ayrı karşılaştırmanın yan yana yapıldığı paralel bir karşılaştırmadır. Bu durumda, tanınacak uyaran, birçok dahili kodla aynı anda karşılaştırılabilir ve tüm süreç, böyle bir karşılaştırmadan daha fazla zaman almaz. Bu, karşılaştırmaların çok hızlı bir şekilde yapılabileceği anlamına gelir.
Görünüşe göre, paralel bir prosedür prensip olarak karşılaştırma aşamasında zamandan tasarruf etme sorununu çözebilir. Bu tür paralel süreçlerin örneklerini fizik alanından biliyoruz. Bir örnek (Neisser, 1967) diyapazonların kullanımını içerir. Bilinmeyen bir doğal frekansa sahip bir diyapazon alıp ona vurursanız (böylece çalmaya başlar), onu bilinen frekanslara sahip bir diyapazon grubuna yakın tutarsanız, o zaman bunlardan biri de çalmaya başlayacaktır. Bu ikinci diyapazon, frekans olarak birincisine karşılık gelir; diğer diyapazonların hiçbiri çalmayacaktır. Bu şekilde, incelenen diyapazonun frekansını belirleyebilirsiniz. Bilinmeyen bir frekansa sahip bir diyapazon, bilinen frekanslara ayarlanmış tüm diyapazonlarla aynı anda karşılaştırıldığından, bu paralel bir karşılaştırma işlemidir.
Zihinsel işlemlerin paralel uygulanmasına ilişkin veriler de vardır. Böyle bir örnek Neisser (1964) tarafından görsel arama deneylerinde keşfedildi. Bu deneylerde, deneklere 50 satıra bölünmüş harf sıraları sunuldu. Her satır birkaç harf içeriyordu, örneğin U, F, C, J. Denek, deneyi yapan kişi tarafından verilen belirli bir harfi olabildiğince çabuk bulmak için satırları yukarıdan aşağıya doğru incelemek zorundaydı. Belirli bir harf rastgele seçilen bir yere yerleştirildi ve denek onu bulduğunda bir düğmeye basmak zorunda kaldı. Aramanın toplam süresi kaydedildi, yani özneye listenin sunulduğu andan verilen mektubu bulduğu ana kadar geçen süre. İyi eğitilmiş bir özneye on harf verildiğinde ve bunlardan birini listede bulduktan sonra bir düğmeye basması istendiğinde, bunu sanki kendisine yalnızca bir harf soruluyormuş gibi hızlı bir şekilde yaptığı ortaya çıktı (Neisser, Novik). bir Lazar, 1963). Bu sonuç sıralı arama sürecine aykırıdır: eğer denek verilen on harfi sırayla ararsa, tüm listeye bakarsa, önce bir harfi sonra diğerini ararsa, bu (ortalama olarak) çok daha fazla zaman alırdı. sadece bir harf arıyorum. Elde edilen sonuçlara bakılırsa, denekler on harfin hepsini aynı anda arayabilir, yani paralel bir arama yapabilir.
Görsel arama görevlerini yerine getirmenin sonuçları ayrıca, deneklerin belirli bir harfi bulma hızının, bir dereceye kadar bu mektubun listedeki diğer harflerden görünüş olarak nasıl farklı olduğuna bağlı olduğunu gösterdi. Örneğin, denekler O, D, U, G, Q ve R harfleri arasında Z harfini 1, V, M, X, E ve W harfleri arasında olduğundan çok daha hızlı buldular. İlk listede yuvarlatılmış harfler yer alıyordu. Z harfine, ikinci listedeki köşeli bir taslağa sahip harflerden çok daha az benzer. Neisser, bu sonuçlara dayanarak, deneklerin, verilen bir harfin standardını listedeki harflerle karşılaştırmak yerine, onun en karakteristik özelliklerini bu listede aradıklarını savunur. Z harfini oluşturan köşeli ana hatların yuvarlak harfler arasında algılanması, köşeli harflere göre çok daha kolaydır, bu nedenle onu bulmak için geçen süre, listede bulunan harflerin genel görünümüne bağlı olacaktır.
Neisser, bu sonuçlara dayalı teorik kurgularında, yukarıda tartışılan Selfridge'in "Pandemonium" modelini kullandı. Bu modelde, örüntü tanıma sürecinin bir aşamadan biri diğerini takip ettiğinden (önce özellik çıkarma iblisleri devreye girer, ardından tanımlama iblisleri vb.) Bununla birlikte, modelin her aşamasında paralel süreçler de meydana gelir: örneğin, tüm tanıma arka plan programları, özellik çıkarma arka plan programlarını takip eder ve aynı anda "bağırır".
BAĞLAMIN ROLÜ
Paralel süreçler, oldukça etkili olmakla birlikte, ortaya koyduğumuz sorunu çözmenin yollarından yalnızca biridir. Sorun, çok sayıda olası seçenekle hızlı örüntü tanıma için gerekli olan karşılaştırma ve karar verme süreçlerinde böylesine bir hıza nasıl ulaşıldığını bulmaktır. Paralel süreçlerde, birçok işlem aynı anda devam ettiği için tanıma hızlı olabilir ve bu, sıralı bir işleme kıyasla zaman kazandırır. Zaman kazanmanın başka bir yolu, karşılaştırma sürecinin ölçeğini azaltmak, belirli bir uyaranın karşılık gelebileceği görüntü sayısını ve dolayısıyla bu uyaranın karşılaştırılması gereken standartların veya özellik listelerinin sayısını azaltmaktır. Sorunu çözmeye yönelik bu yaklaşım, mantıksal olarak imkansız bile görünebilir. Uyarıcının ne olduğunu önceden bilmeden ihtiyaç duyulan karşılaştırma sayısını nasıl azaltabiliriz? Bu uyaranın ortaya çıktığı bağlamın rolünü düşünürsek, bu sorunun yanıtı bulunabilir.
Genel olarak, bir uyaranın dahil edildiği bağlam, nihai olarak nasıl sınıflandırılması gerektiğini belirlemede son derece önemlidir. Belirli bir durumda hangi uyaranlarla karşılaşılabileceği biliniyorsa, bu, çok sayıda görüntüyü değerlendirme dışı bırakmamıza izin verir. Örneğin, "Olmak ya da olmamak, işte bu ..." ifadesinin sonundaki belirsiz telaffuz edilen kelimeyi tanımaya çalışıyorsak ve "sorgulama" gibi bir şey duyuyorsak, muhtemelen bizim için kolay olacaktır. Burada "soru" kelimesini tanımamız gerekiyor." Bu, uyaranın kendisi bir "soru"dan çok bir "sorgulama" gibi görünse bile gerçekleşebilir. Böylece bağlam - bu durumda iyi bilinen bir alıntı - belirsiz seslerin yerine konduğunda anlamlı olacak görüntülerin sayısını sınırlar ve giriş mesajının belirsizliğine rağmen tanıma mümkün olur. Bağlam, bir uyaranın eşleştirebileceği görüntü sayısını azaltır ve sisteme yüklenen talepleri azaltır.
Psikolojik araştırmalarda bağlamın etkisiyle sıklıkla karşılaşırız. Bir örnek, bir harfin kendi başına değil, bir kelimenin parçası olarak sunulduğunda görsel algıda tanımlanmasının daha kolay olduğunu gösteren deneylerdir (Reicher, 1969; Wheeler, 1970). Sözcüğün harf için bir bağlam oluşturduğu ve bağlamın özelliklerinden birinin de özellik analizi sürecine rehberlik etmesi olduğu ileri sürülmüştür (Wheeler, 1970). Belirli bir kelimedeki bir harfin, kelimenin bir parçası olması nedeniyle tanımlanması, kalan harflerin olası anlamlarını sınırlar. Bu nedenle, kendinizi yalnızca bazı işaretleri kontrol etmekle sınırlayabilir, diğerleri ise kontrol edilmeden atılabilir.
Kelimelerin işitsel algısında da benzer etkiler gözlenir. Bu, deneklerin gürültü arka planına karşı kendilerine sunulan kelimeleri tanımlamaları gereken deneylerde gösterildi (Miller AO, 1951). Sözcükler anlamlı tümceler oluşturduğunda, bunların anlaşılması, rastgele bir sırayla düzenlenmelerine göre çok daha kolaydı: Tümce tarafından oluşturulan bağlam, tek tek sözcüklerin tanınmasını kolaylaştırıyordu. Ayrıca (Miller, 1962) konuşmayı algıladığımızda, genellikle tüm fonem gruplarını - tüm sözcükleri ve hatta tümceleri - anında tanıdığımız öne sürülmüştür (Miller, 1962). Bu, alınan kararların birbirine bağlı olabileceği ve bir fonem hakkında verilen kararın, diğer sesleri tanımayı kolaylaştıran bir bağlam oluşturabileceği anlamına gelir. Okurken basılı bir kelimenin harflerini tanımlarken de benzer etkiler mümkündür. Tanıma harf harf değil, birkaç harf düzeyinde yapılabilir.
kelimeler (Smith ve Spoehr, 1974), böylece bir harfin kısmen tanınmasından kaynaklanan bağlam bile diğer harflerin tanınmasını kolaylaştırır.
Örüntü tanıma mekanizması hakkındaki hipotezi, bağlamın rolüne ilişkin düşüncelerle tamamlamak, konumunu önemli ölçüde güçlendirir. Kalıpları bu kadar kolaylıkla tanıma yeteneğimizi bize neyin verdiğini anlamaya başlıyoruz. Şimdiye kadar söylenenlerin hepsi, yeterli bir örüntü tanıma teorisinin bazı özelliklerini ortaya çıkarmamıza izin verdi. Artık hafıza kodlama ve karşılaştırma süreçlerine baktığımıza göre, tanımanın başka bir yönüne, bu süreç ile dikkat arasındaki ilişkiye bakacağız.
DİKKAT
Önceki bölümlerden birinde, "dikkat" teriminin birkaç anlamı olduğu belirtilmişti. Genel olarak "seçicilik" olarak adlandırılan dikkatin bir yönü, burada tartışılan konuyla özellikle yakından ilgilidir. Dikkatin seçiciliği, gürültülü bir parti örneğiyle zaten gösterilmiştir (s. 25-26): bir kişi, belirli bilgi kaynaklarının algısına uyum sağlayabilir, işlemek için belirli kanalları seçebilir ve "yeniden inşa edebilir" veya diğerleriyle bağlantısını kesin.
"İZLEME" İLE DENEYLER
Dikkatin seçiciliği, dikotik dinleme ve izleme ile yapılan deneylerde kapsamlı bir şekilde incelenmiştir. Dikotik dinleme, özneye sesin iki kanal aracılığıyla aynı anda sunulduğu deneyler olarak adlandırılır. Bölümde daha önce bahsedildiği gibi. 3, bir kanal tek bir ses kaynağını ifade eder. Tipik bir dikotik dinleme-izleme deneyinde, denek aynı anda iki kanaldan (her kulakta bir tane) kulaklık aracılığıyla iki mesaj duyar.Deneklerden mesajlardan birini dinlemesi ve "takip etmesi" istenir (örn. , kelimesi kelimesine tekrarlayın.) Şaşırtıcı bir şekilde, denekler iki mesajı dinlerken çok zorlanmadan bir mesajı takip ediyor.
Dikotik dinleme ve izlemenin etkileri, Cherry (Cherry, 1953) tarafından kapsamlı bir şekilde incelenmiştir. Konunun dikkat etmediği ikinci mesaja ne olduğuyla özellikle ilgilendi. Konu ikinci kanaldan kopmuş olsa da yine de bazı şeyler ona ulaştı. Örneğin, denek ikinci kanalın aktif olduğunu biliyordu (bazı sesler duydu) ve bunun insan konuşması mı yoksa vızıltı gibi konuşma dışı bir ses mi olduğunu anlayabiliyordu. Denekler, ikinci mesajı bir erkek sesi yerine bir kadın sesinin okumaya başladığını da fark ettiler. Bununla birlikte, okunmakta olan metnin belirli içeriği, gerçek konuşma mı yoksa anlamsız konuşma sesleri dizisi mi, mesajın hangi dilde olduğu ve deney sırasında dilin değişip değişmediği hakkında hiçbir şey söyleyemediler. Aynı kelime defalarca tekrarlansa bile duyduğu kelimelerin hiçbirini tanıyamıyordu (Mogau, 1959).
Dichotic dinleme ve izleme, "parti fenomeninin" deneysel bir versiyonudur. Bu prosedür, dikkati incelemek için yararlı bir yöntem olarak hizmet eder, çünkü bu durumda özne, görevi tamamlamak için dikkatini seçici olarak bir kanala, takip ettiği kanala yönlendirmeli ve diğerinden ayrılmalıdır. Bu tür deneylerin sonuçları, dikkat fenomeninin birkaç modelinin oluşturulmasına yol açtı, çünkü bu çalışmalarda açıklama gerektiren bir dizi önemli veri elde edildi.
Özellikle, dikkat teorisi, bir kişinin diğerlerini ihmal ederek tüm dikkatini bir kanala nasıl yoğunlaştırdığını açıklamalıdır. Ayrıca bu diğer kanallardan gelen bilgilere ne olduğunu da açıklamalıdır.
DİKKAT MODELLERİ
Dikkatin en iyi bilinen teorik modellerinden biri, seçici dikkatin bir filtre gibi davranarak bilgiyi yalnızca bir kanaldan geçirip diğerlerini bloke ettiği filtre modelidir (Broadbent, 1958). Engelleme işlemi, tüm kanallardan gelen mesajların fiziksel özellikleri analiz edilerek mümkün kılınmakta; Bu analize dayalı olarak, alım için belirli bir kanal tahsis edilebilir. Bu nedenle, örneğin, dikotik dinleme sırasında (Şekil 4.4), kaynaklarının uzaydaki farklı konumları nedeniyle (biri solda, diğeri sağda) iki mesaj arasındaki ayrım mümkündür. Bu fark, soldan gelen gibi bu mesajlardan yalnızca birini seçip ileten bir filtre eyleminin temelini oluşturur. Perde farkına göre erkek veya kadın sesi seçilebilir. Tüm bunlar, öznelerin takip etmedikleri mesajın bazı fiziksel özelliklerini neden bildiklerini anlamayı mümkün kılar: fiziksel analiz filtrelemeden önce geldiği için bunları bilirler.

4.1. Zzddie, irelu_snn_nns'i takibe almaktan ; Broadbent modeline göre gerçekleşen süreçler. Filtre, beşincisinde bulunan sayıya göre daha ileri işlemler için bir mesaj seçer ve başka bir mesajı geciktirir.
Broadbent modelinin yetersizliği, dikkatin mesajın anlamına bağlı olarak bir kanaldan diğerine geçebileceğini ve geri dönebileceğini gösteren deneylerde ortaya çıktı. Bu, giriş mesajını kesip bir kısmını bir kulağa, diğerini diğerine beslersek gözlemlenebilir. Örneğin, "fareler peynir yer" mesajını kırabilir ve birinci ve üçüncü kelimeleri sağ kulağa, "ye" kelimesini sola verebilirsiniz. Aynı zamanda başka bir bozuk mesajın parçaları her iki kulağa da verilebilir. Örneğin, sağ kulağa "fare" kelimesi verilirken, sola "üç" kelimesi verilir, ardından sola "ye", sağa "beş" kelimesi verilir; sağa - "peynir", sola - "dokuz" Bu koşullar altında (Gray ve Wedderburn, 1960) ve denekler, her ikisinde de servis edilmesine rağmen, genellikle anlamlı "fareler peynir yer" ifadesini takip eder. duyduklarını tek kulakla tekrarlamak yerine sağ veya sol kulakta "fare: beş peynir" gibi. Bu, dikkatin girdi sinapsının fiziksel işaretlerini değil, diğerlerinin neden anlamlı kelime dizilerini takip ettiğini gösterir.
Trisman ( 1960) ayrıca dikotik dinlemede deneklerin, hangi kanaldan aktarılıyor olursa olsun mesajın anlamını takip etmek için bazen sözcükleri tekrarladıklarını gösterdi (Şekil 4.5). Örneğin özne sağ kulağa gelen mesajı takip ederse ve birdenbire bu mesaj sol kulağa verilirse, takip etmediği sağ kulağa geçerse, o zaman öznenin tepkisi sol kulağa da geçebilir. . Denek, sağ kulağa gelen bilgileri sürekli olarak takip etmesi talimatı verildiği halde, bir kulaktan diğerine atlayarak mesajı takip etmeye devam edebilir. Böylece
, izleme sırasında özne, seslerin nereden geldiğine göre değil, anlama göre yönlendirilir.

Pirinç. 4.5. Deneysel sonuçlar Trinity: Bir dizi eşzamanlı mesaj aniden bir kulaktan diğerine geçerse, denekler 4DP0 zihninden geçen az mesajını takip edemediler.
Bu verilerin de gösterdiği gibi, dikkat olgusunu yalnızca uyaranın fiziksel özelliklerinden yola çıkarak açıklamak yanlış olur. Bulunan tutarsızlık göz önüne alındığında, Trisman (Trisman, 1969) Broadbent'in modelini değiştirdi; ona göre dikkat, seçilmemiş kanallardan geçen bilgi miktarını azaltarak daha çok bir zayıflatıcı gibi hareket eder, ancak onları tamamen kapatmaz. Triesman: Dışarıdan gelen tüm sinyallerin bir dizi ön teste tabi tutulduğuna inanıyor. Önce giriş sinyallerinin genel fiziksel özelliklerini analiz ederler ve ardından bu sinyaller içerikleri açısından daha incelikli bir analize tabi tutulur. Bu tür testlerden sonra dikkat kanallardan birine yönlendirilebilir. Bu testler neye odaklanılacağını belirler, yani kanal seçimi ön analiz sonuçlarına göre belirlenir. Böylece, bir kanaldan farelerin geldiğine dair bir mesaj dinliyorsam ve bu mesaj aniden değişip başka bir kanaldan gelmeye başlarsa, ön testler bunu ortaya çıkaracak ve bu da bana dikkatimi başka bir kanala çevirme fırsatı verecektir. Aynı mesajı izlemeye devam etmek için ikinci kanal.
Bununla birlikte, Triesman'ın ön test hipotezi şu zorluğa yol açar: Yeterince incelikli bir ön analiz gerekliyse, kendimizi henüz vurgulanmamış bir mesajın anlamının açıklığa kavuşturulmasını varsayarken bulabiliriz. Şu soru ortaya çıkıyor: Onlara dikkat etmeden önce görüntüleri tanıyabilir miyiz (ve mesajın anlamını belirlemek için yapmamız gereken şey budur)?
Örüntü tanıma ve dikkat arasındaki ilişki, Norman (Norman, 1969) tarafından, Deutsch ve Deutsch (Deutsch ve Deutsch, 1963) tarafından ifade edilen bir fikir kullanılarak açıkça ifade edilmiştir. Norman'ın modeline göre, işleme sisteminin tüm giriş kanalları, uzun süreli bellekte belirli izleri etkinleştirmeye yetecek kadar bir dereceye kadar analiz edilir. (Pandemonium sistemi açısından, tüm uyaranların özellik algılama şeytanları tarafından analiz edildiğini ve bu da karşılık gelen bazı tanıma şeytanlarının aktif olmasına neden olduğunu söyleyebiliriz.) Bu anda, yönlendirildiği görüntülerin tam olarak tanınmasına karşılık gelen seçici dikkat işlemeye başlar. (Pandemonium sisteminde bu, girdi görüntüleriyle eşleşmesi muhtemel olan tüm tanıma iblislerinin uyandığı, ancak bu görüntülerin yalnızca bazılarının tanındığı anlamına gelir.) Norman'a göre, bir görüntüyü tanımak, ona dikkat etmektir. Bağlam, tüm bunlarda önemli bir rol oynar, çünkü hangi görüntülerin tanınacağı, belirli bir durumda hangi görüntülerle karşılaşma olasılığının en yüksek olduğuna bağlıdır.
Neisser (1967) ayrıca örüntü tanımayı dikkat ile ilişkilendirir. Teorisine göre, tüm girdi bilgileri, dikkatten önce gelen bir düzeyde ön analize tabi tutulur. Şu veya bu uyaranın nihai olarak tanınması, ancak dikkat bu uyarana verildiğinde gerçekleşebilir. Böylece dikkat, tam tanımadır.
Neisser'in teorisi özellikle ilgi çekicidir: DP'de henüz ele almadığımız bir tür bilgi kodlaması varsayar. Bir DP kodu fikri, Halle ve Stevens tarafından öne sürülen bir konuşma algısı modeli olan "sentez yoluyla analiz" kavramından kaynaklanmaktadır (Halle ve Stevens, 1959, 1964). Bu model oldukça sıra dışı bir fikre dayanmaktadır: Bir konuşma görüntüsünün tanınmasının esas olarak onun yapısına eşdeğer olduğu varsayılmaktadır. Yazarların konsepti şu şekilde özetlenebilir: 1) DP, bu uyaranın bir kopyasını ve sahip olduğu özellikleri değil, girdi uyaranıyla karşılaştırmak için depolar ve kullanır, ancak yapımı için bir dizi kural; 2) bu kurallar, uyaranla karşılaştırılacak bir iç görüntünün sentezi veya inşası için kullanılır; 3) sentez için küçük bir görüntü grubunun seçiminde kullanıldığından, bu sentez sürecinde önemli bir rol bağlam tarafından oynanır. Bu bağlamda karşılaşma olasılığı en yüksek olan görüntüler bunlardır. Kısacası, örüntü tanıma, uyaranları aktif olarak yeniden üretme sürecini içerir. Bu çoğaltma kesinlikle tesadüfi değildir; uyaranın ortaya çıktığı durum tarafından yönlendirilir. Bu yönlendirilmiş yapıyla, DN'de saklanan bir dizi kural kullanılır. (Dolayısıyla bu teoriye göre tanımada kullanılan DP kodu, uyaranın içsel bir kopyasını oluşturmaya yönelik bir kurallar dizisidir.) Bu şekilde yeniden üretilen veya sentezlenen içsel uyaran, dışarıdan gelen uyaranla karşılaştırılır ve bu eşleştirmenin sonuçları tanımayı belirler. Dolayısıyla, Neisser'in teorisine göre, içsel bir görüntünün sentezlenme süreci dikkat ile aynıdır.
ÖRNEK TANIMA GENEL MODELİ
Örüntü tanıma sürecine bakarak, ana bileşenlerinden bazılarını tanımlayabildik. Şimdi bu ana bileşenleri özetlemeye ve bunları genel bir örüntü tanıma modelinde birleştirmeye çalışalım. Böyle bir model için neye ihtiyacımız var? Her şeyden önce, Şekil l'de gösterilen tüm bileşenlere ihtiyacımız var. 4.1: bir uyaranın birincil temsili veya kaydı; karşılaştırılabileceği birkaç dahili (ID) kod; karşılaştırma ve karar verme süreçleri. Örüntü tanıma sürecinde bağlamı hesaba katan mekanizmalara da ihtiyaç vardır; Bu özellikle önemlidir, çünkü bağlam, uyarıcıyı karşılaştırmanız gereken görüntülerin sayısını önemli ölçüde azaltmanıza izin verir. Daha sonra bu karşılaştırmada kullanılan D11 kodunun doğası sorusuyla karşı karşıyayız. Bu kodun doğasını açıkça gösterecek hiçbir verimiz yok; bu nedenle, ele aldığımız kodlardan (prototipler, özellik listeleri veya kural listeleri) birini veya diğerini seçemeyiz.
Ardından, modelimize uyaranların ön analizi için bir mekanizma dahil edeceğiz. Bu analiz bağlam tarafından yönlendirilmelidir. Naif referans hipotezini geliştirmek için kullanılan uyaran ön standardizasyonuna veya Pandemonium sistemi gibi modellerde özellik analizine karşılık gelebilir. Son olarak, bağlamın kendisine bir göz atalım. Modele bağlam etkisini dahil etmek için, belirli bir uyaranın tanınmasında kullanılabilecek önceki tanımaların sonuçları hakkında bilgi sağlayan bir "geri bildirim" mekanizmasına ihtiyacımız var. Ek olarak, tanıma sistemine aynı anda birkaç uyaranla başa çıkma yeteneği kazandıracağız; bu, konuşma tanımanın tek bir fonem düzeyinde gerçekleşmemesi ve okumanın harfle yapılmaması gerektiği anlamına gelir.
Sonuç olarak elde edebileceğimiz tanıma sürecinin modeli Şekil 1'de gösterilmektedir. 4.6. İşte duyusal kayda gelen uyaranla ilgili girdi bilgisi (bunun bir dizi fonem, harf veya her neyse olabileceğini unutmayın). Bilgiler bu kayıtta yer alırken ön incelemeye tabi tutulur. Uyaranın sahip olduğu işaretler not edilir ve temsili bazı standart biçimlere indirgenebilir (normalleştirilebilir). Bu ön analiz, henüz tamamlanan tanımalardan gelen geri bildirimlerin sağladığı tanımanın genel bağlamı hakkındaki bilgilerden etkilenir. Ardından, uyarıcının temsilinin karşılaştırıldığı bir dizi DP görüntü kodu vardır. Bu görüntülerin özellik listeleri, standartlar, bir dizi kural kullanılarak oluşturulan prototipler veya başka bir şey olup olmadığını kesin olarak söyleyemeyiz, ancak bu kümelerin DP'de depolanan tüm kodları içermediği açıktır. Karşılaştırma için kullanılan kodların sayısı mevcut bağlamsal bilgilere bağlıdır (örneğin, İngilizce kelimelerin bir listesini okurken İbrani alfabesindeki bir harfi tanımaya çalışmamız olası değildir). Daha sonra bu kodlar, analiz edilen uyaranla karşılaştırılır (büyük olasılıkla, aynı anda birkaç kodla paralel bir karşılaştırma gerçekleşir). Ve son olarak, hangi DP kodunun en iyi olduğuna, en çok verilen uyarana karşılık gelen, yani örüntü tanıma anlamına gelen bir karar verilir. Verilen karar, içeriği uygulayan mekanizmaya geri beslenir, böylece içerdiği bağlam bilgisi, daha sonraki tanıma eylemleri için daha iyi kullanılabilir.

Teşekkür ederim. 4.6. ryaspiiiiiaiiya obraіy'nin genel modeli.
Şek. Şekil 4.6, örüntü tanıma süreci tartışmamızdan öğrendiğimiz hemen hemen her şeyi içeriyor gibi görünüyor. Ayrıca bu tür tanıma sistemlerinin bazı eksikliklerinin ortaya çıkarılmasına da olanak sağlamaktadır. Bu sistem hata yaptığında, özellik benzerliğine dayalı olarak ne rastgele ne de tamamen tahmin edilebilir olan hatalardır. Modelimiz, görüntüleri yalnızca sahip oldukları özelliklere göre değil, aynı zamanda mevcut bağlama tam olarak uyan özelliklere göre de tanır. Gerçekten de, bir kişi bazen gerçekten orada olmayan bir şeyi sırf beklediği için "görebilir" veya "duyabilir". Bu, bir toplantıda seçimlerde başarısız olan bir kişinin, başka birinin adı çağrılmasına rağmen, belirli bir görevi almayı kabul etmek için koltuğundan fırladığında sözde "katılıyorum" olgusuna yol açabilir - kim resmen seçildi!
Bu sistem ayrıca, verilen bağlamda beklenmiyorsa, aslında orada olanı tanımakta başarısız olabilir. Ve elbette, harfler çok kısa bir süre sunulduğunda ortaya çıkan görsel ipuçları gibi benzer şeyleri özellikle karıştırabilir. Psikolojik deneylerde sıklıkla olduğu gibi, bağlamsal bilginin minimum olduğu durumlarda bu tür hataların özellikle sık olması beklenir. Oluşturduğumuz örüntü tanıma modeli, insanların her zaman yaptığı hata türlerini açıkça tahmin ediyor. Bir kişi tarafından örüntü tanıma sürecini simüle eden bir sistem için bu oldukça doğal kabul edilebilir.
Özetle, örüntü tanıma sürecinin değerlendirilmesinin, yalnızca dış uyaranların tanınmasıyla ilgili değil, aynı zamanda insan hafızasının genel doğasıyla ilgili bir dizi ilginç şeyi fark etmemize izin verdiğini söyleyebiliriz.
Bölüm 5
Kısa süreli bellek: bilgilerin depolanması ve işlenmesi
Önceki bölümlerde, kategori öncesi bellek kodlarının (örüntü tanımadan önceki kodlar) saklanmasının yanı sıra, uzun süreli bellekte depolanan kodların dahil olduğu bir süreç olan karşılık gelen uyaranları tanıma mekanizmaları ele alındı. "Gerçek dünya"dan gelen uyaranın nasıl makaslama kaydına tabi tutulduğunu, ilgi nesnesi haline geldiğini ve tanındığını izledik. 2, en azından bir kısmı kısa süreli belleğe (LTM) aktarılır ve bu bölümde bu belleğin bilgi işleme sistemindeki rolünü ele alacağız.
SP ile ilgili araştırmaların çoğunun sözlü materyal üzerinde yürütüldüğü unutulmamalıdır. Bu nedenle, bir kelime deposu olarak CP hakkında, diğer yönlerinden çok daha fazla şey bilinmektedir. Tüm bu çalışmalar sonucunda kelimelerin CP'de akustik yani ses şeklinde depolandığı görülmektedir. Bu bölümde ve Bölüm. 6, ana dikkat SP'nin sözel-akustik yönlerine odaklanmıştır. Ch'de. Şekil 7'de, CP'de görsel ve anlamsal (anlamsal) bilgilerin saklanma olasılığını hesaba katmak için sorun biraz daha geniş bir şekilde ele alınacaktır.
CP'yi ele alırken, Bölüm 1'de açıklanandan ilerleyeceğimizi de not etmek önemlidir. Teorik modelin 2'si, buna göre CP ve DP ayrı bellek depolarıdır. Ch'de. 2'de, PC'nin bağımsızlığından yana konuşan en az üç veri grubuna dikkat çektik, ancak aynı zamanda tüm psikologların hafızanın dualite teorisiyle aynı fikirde olmadığına da dikkat çektik. Aşağıda genel kabul görmüş bir terim olan "kısa süreli hafıza" kavramını kullanacağız, çünkü kısa süreli depolama kavramı insanlarda bazı önemli hafıza olaylarını açıklamada çok faydalıdır.
pfcc, 5.G
KP'yi, bir marangozun dolap yaptığı bir atölyede bir tezgah olarak düşünelim (Şekil 5.1). Gerekli tüm malzemeler, atölyenin duvarları boyunca uzanan raflara düzgün bir şekilde yerleştirilmiştir. Bu aşamada ihtiyaç duyulacak şey, KP: bilgilerin, aletlerin, rendelenmiş tahtaların ve benzerlerinin depolanması ve işlenmesi, marangoz raftan alır ve üzerinde çalışmak için yeterli boş alan bırakarak çalışma tezgahına koyar. Tezgah dağınık hale geldiğinde, marangoz tüm öğeleri ayrı demetler veya istifler halinde düzenleyebilir, bu da onun tezgah üzerine daha farklı malzemeler yerleştirmesine olanak tanır. Bu tür yığınların sayısı çok artarsa, tezgahtan eşyalar düşmeye başlayabilir veya marangoz bazı eşyaları tekrar rafa koyabilir.
İkili sistem kavramımızla benzerlik nedir? Bir marangozhanedeki rafları, iş için ihtiyaç duyulan çok sayıda farklı malzeme için bir depolama alanı olarak düşünebiliriz. Bir marangoz tezgahına bölünmüş bir tezgah ve sınırlı depolama bir CP'dir. Bir marangoz, çalışma tezgahında daha fazla boş alan yaratmak için nesneleri istifler halinde topladığında, CP'de de meydana gelebilecek bir işlemi, yani yapılanmayı gerçekleştiriyor. (Göreceğimiz gibi, kısa bir öğe listesini ezberlerken, yapılandırma genellikle birkaç öğeyi CP'deki bir öğenin yerini alacak şekilde birleştirmek için kullanılır.) raflardan çalışma tezgahına ve çalışma tezgahından rafa öğeler DP'den CP'ye bilgi aktarımına benzer ve bunun tersi de geçerlidir. Uzun süreli belleğin izlerinin sabitliği fikrini yansıtmak ve materyal CP'ye aktarıldığında aslında DP'den çıkarılmadığı fikrini yansıtmak için biraz esnetmek gerekecek ve Raflarda her bir malzeme için sınırsız stok olduğunu varsayalım, böylece herhangi bir malzeme seti bir çalışma tezgahına aktarıldığında, rafta birbirinin aynısı başka bir set kalır.
Tezgah benzetmesi çok ileri götürülmezse yararlıdır. Kısa süreli hafızayı, çeşitli şeyleri saklayabileceğiniz ve bunlarla çalışabileceğiniz, kolayca yeniden organize edilebilen bir hafıza alanı olarak düşünmemizi sağlar. Ayrıca gördüğümüz gibi iş yeri ile depo yeri arasında bir "değişim" var, öyle ki biri genişledikçe diğeri küçülüyor. Bununla birlikte, KP'nin karmaşıklığı, içeriği yığınlar halinde veya raflara yerleştirmekle sınırlı değildir.
TEKRARLAMA
CP ile ilişkili süreçlerden biri tekrardır, yani bilgiyi bellek depolama yoluyla birçok kez iletmektir. Daha önce de söylediğimiz gibi, tekrarın temel olarak iki işlevi olduğu varsayılır: unutulmasını önlemek için CP'de depolanan bilgileri tazeler ve tekrarlanan öğeler hakkındaki bilgileri DP'ye çevirerek uzun- terim izleri. (DP izlerinin gücünün tam olarak ne olduğu sorusu sonraki bölümlerde tartışılacaktır.) Bu nedenle, tekrarlama, CP'nin "çalışan" işlevlerinden biri olarak düşünülebilir: hem bilgileri yenilemek hem de bilgi tazelemek için gerekli olan çalışmaktır. DP'ye aktarıyor. Ancak tekrarın bu işlevleri nasıl yerine getirdiği, nasıl çalıştığı ve tam olarak neyin tekrarlandığı henüz net değil.
İÇ KONUŞMA OLARAK TEKRAR
Tekrarlama süreci, içsel veya sessiz bir tür konuşma olarak düşünülebilir. Bu görüş, doğrudan hatırlama görevlerinde mektup yazan öznenin bunları genellikle kendi kendine telaffuz ettiğini kaydeden Sperling'in (1967) gözlemleriyle desteklenmektedir. Spurling'e göre bu, SP'de yer alan daha genel bir sürecin, tekrarlama sürecinin doğası olabilir. Bir unsur tekrarlandığında, öznenin onu kendi kendine telaffuz ettiğine , söylediklerini duyduğuna ve ardından duyduklarını CP'de sakladığına ve böylece izin orijinal gücünü geri kazandığına inanıyor. İlk aşama, yani "kendi kendine" telaffuz etme, sözde "içsel" veya "sessiz" konuşmadır. Bu durumda gerçek sesler olmayabilir, ancak tekrarlandıklarında bunun yerine seslerin telaffuz edilmeyen zihinsel görüntüleri kullanılır .
İç konuşma olarak tekrar kavramı bir takım farklı verilerle desteklenmektedir. Bir veri grubu, tekrarın meydana geldiği hıza ilişkin tahminlerle ilişkilendirilir. Denekten örneğin bir dizi mektubu kendi kendine 10 kez tekrarlaması ve bunun için harcanan zamanı not etmesi istenir; buradan tekrar oranı belirlenebilir ve saniyedeki harf sayısı ile ifade edilebilir. Bu şekilde elde edilen hızı dış, ses, konuşma hızı ile karşılaştırırsak, bunların yaklaşık olarak aynı olduğu, genellikle saniyede 3 ila 6 harf arasında değiştiği ortaya çıkar (Landauer, 1962). Bu nedenle, tekrarlama ve konuşma, yaklaşık olarak aynı süreyi almaları bakımından benzerdir.
Tekrarın iç konuşma olduğunu gösteren başka verilerden daha önce bahsetmiştik; bu, doğrudan hatırlama deneylerinde gözlemlenen akustik hatalara ilişkin verilerdir (Conrad, 1963; Sperling, 1960; Wickelgren, 1966).Çoğu zaman, görsel veya anlamsal benzerliklerinden bağımsız olarak, SP'de sese benzer öğelerin bir karışımı meydana gelebilir. Sperling ve Speelman'a göre (Sperling ve Speelman, 1970), bu tür hatalar, CP'de depolanan öğelerin akustik biçimde sunulmasından kaynaklanmaktadır ve unutulduklarında bir fonem (tek ses) birbiri ardına düşebilir. . Hatırlama sırasında denek, kısmen unutulmuş unsurları hala korunan seslerden geri getirmeye çalışır. Böylece, bir hata yaptığında, cevabı sunulan öğede bulunan sesleri içerecektir; hataların akustik doğası bununla ilgilidir. Bu modele göre tekrarlama, seslerin orijinal olarak burada kodlandıkları biçimde CP'ye yeniden girmesiyle sonuçlanan içsel konuşmadır. Bu model, bazı doğrudan hatırlama görevlerinde sonuçları tahmin etmek için bir miktar başarı ile kullanılmıştır.
İç konuşma olarak tekrarlama kavramı, SP'de işitsel kodlama kavramına çok iyi uysa da, bu yine de yeterli değildir. Tekrarlama, bir kişinin kendisine bir öğeyi zihinsel olarak sunmasıysa (örneğin, bir mektubun zihinsel telaffuzu), o zaman tekrar görsel de olabilir. Örneğin, alfabedeki harfleri görselleştirmek çok kolaydır. Bunu doğrulamak için, tüm alfabeyi zihinsel olarak gözden geçirin ve harflerinin her birinin dikey bir çizgiye sahip olup olmadığını düşünün (A'da yoktur, B'de vardır, vb.). Daha sonra ayrıntılı olarak ele alacağımız görsel imgelerin bu yeniden üretimi (yukarıdaki tanıma uygun olarak) bir tür tekrardır. Hızına ilişkin tahminler (örneğin, gözlerinizi tüm alfabede zihinsel olarak gezdirmeniz ne kadar sürer?), iç konuşma dediğimiz işitsel tekrardan daha uzun sürdüğünü gösterir (Weber ve Castleman, 1970). Görsel imgeleri yeniden üretme yeteneğimiz, tekrarın bazen "içsel görüş" biçimini alabileceği anlamına gelmiyor mu?
TEKRARLA VE DP'YE AKTAR
Görünüşe göre iç konuşmanın yardımıyla gerçekleştirilen tekrar, sadece CP'deki izleri korumakla ve canlandırmakla kalmaz: aynı zamanda DP'ye bilgi aktarımına neden olduğu ve böylece uzun vadeli izlerin gücünü artırdığı varsayılır.
Bu gerçekten böyle mi? Bu soruyu cevaplamak için bir girişimde bulunan Rundus (Rundus, 1971; Rundus ve Atkinson, 1970) deneklerinden yüksek sesle tekrar etmelerini istedi. Serbest hatırlama ile ilgili tipik deneylerinden birinde, deneğe 5 saniyede bir kelime hızında bir kelime listesi sunuldu. Denek, kelimeler arasındaki 5 saniyelik aralıklarla bazı kelimeleri yüksek sesle tekrar ederek bu listeyi ezberlemek zorunda kaldı. Belirli bir kelime söylemesi istenmedi: sevdiği kelimeleri seçebilirdi. Belirli bir 5 saniyelik aralıkta deneğin tekrarladığı sözcük grubuna bu aralık için "tekrarlanan dizi" adı verildi (Şekil 5.2, A). Randus, listenin sunumundan sonra test edilen, tekrarlanan kümelerin bileşimi ile ezberlemenin etkinliği arasındaki ilişkiyi bulmak istedi. Beklendiği gibi, çok güçlü bir ilişki buldu (Şekil 5.2, B): belirli bir kelime yüksek sesle ne kadar sık \u200b\u200btekrarlanırsa ve içinde göründüğü tekrar kümelerinin sayısı ne kadar fazlaysa, onu hatırlama olasılığı o kadar yüksek olur.
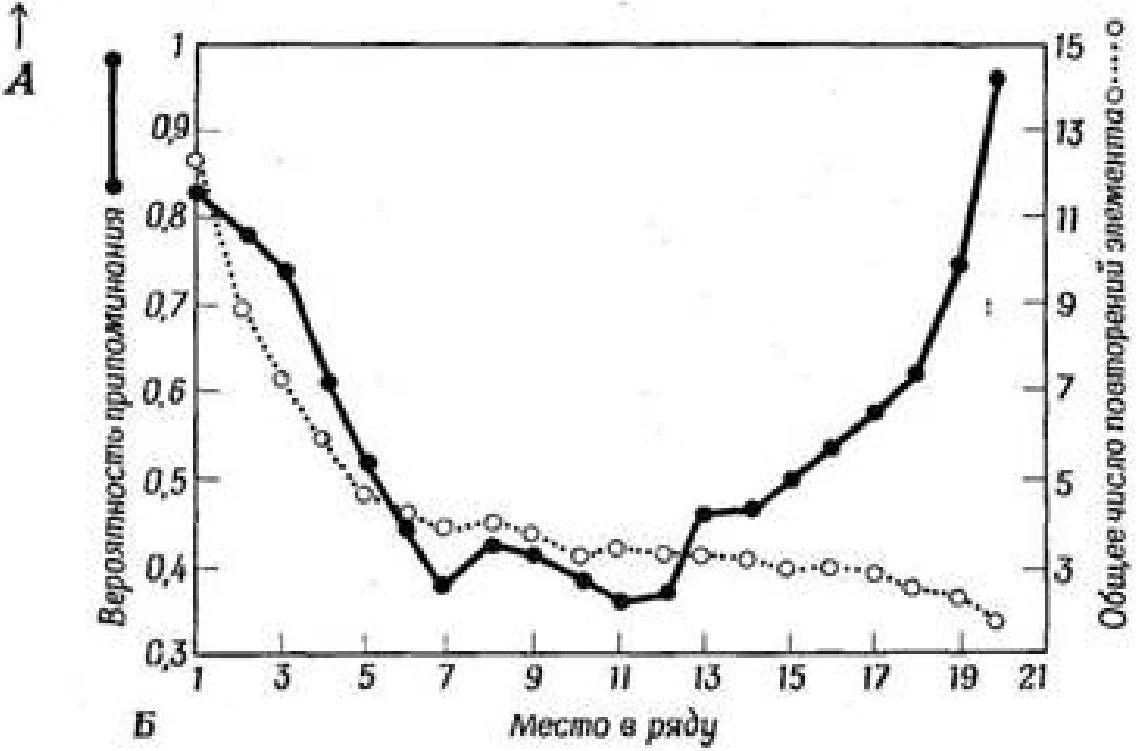
Randus ayrıca, deneklerin tekrarladığı kelimelerin seçiminin, bu kelimelere önceden aşina olmalarından etkilendiğini de buldu. Özellikle, yeni sunulan kelimenin tekrarlanan kümeye dahil edilme olasılığı, anlam bakımından kümedeki diğer sözcüklere uyan sözcükler için daha yüksekti. "Serçe" gibi bir kelimenin zaten "pamukçuk, kanarya, çalıkuşu" kelimelerini içeren bir kümeye dahil edilmesi muhtemeldir, ancak bu küme "ekmek, yumurta, peynir" kelimelerini içeriyorsa tekrarlanması pek olası değildir. Bu nedenle, Randus tarafından elde edilen sonuçlar, tekrarın D11'deki belirli izlerin gücünü artırdığına (bu, tekrar sayısı ile ezberleme verimliliği arasındaki doğrudan bir ilişki ile kanıtlanır) ve düzenleme süreçlerinin belirlemek için DP'den gelen bilgileri kullandığına inanmamızı sağlar. CP'deki öğelerden hangisi tekrarlanmalıdır. . Genel olarak, geçmişte öğrenilen bilgileri şu anda işlenmekte olan bilgilerle ilişkilendirmek için DP kullanımına arabuluculuk denir. Böylece, Randus'un sonuçları, tekrarın dolayımla ilişkili olduğunu göstermektedir.
Randus'un deneyleri, esasen korelasyonel olduğu için eleştirildi - tekrarların sayısı deneyi yapan kişi tarafından değil denek tarafından kontrol ediliyordu. Tekrar sayısı ile hatırlama arasında bir ilişki ortaya koysalar da, nedensel ilişki belirsizliğini koruyor: hatırlamanın tekrarlar tarafından belirlendiğinin kanıtlandığı düşünülemez. Deneklerin tam olarak hatırlaması daha kolay olan ve daha sonra zaten hatırlayacakları unsurları tekrar etmeleri mümkündür, böylece tekrar daha iyi ezberlemeye neden olmaz.
Randus verilerinin böyle bir yorumunun olasılığı, kendi başına, tekrarın ezberlemenin etkinliğini artırdığı gerçeğine karşı konuşmaz. Bununla birlikte, tekrarın zorunlu olarak DP'ye bilgi aktarımına yol açtığı fikriyle çelişen başka veriler de vardır. Örneğin, belirli bir öğenin tekrar sayısının sonraki hatırlamayı her zaman etkilemediği gösterilmiştir (Craik ve Watkins, 1973; Woodward, 1973). Craik ve Watkins, deneklerin çeşitli zaman dilimlerinde CP'de tek tek kelimeleri tutmasını sağladı. Bir deneyde, bu amaçla, denekten 21 kelimelik bir dizide belirli bir harfle başlayan son kelimeyi söylemesi istendi. Örneğin C harfi verildiğini ve satırın KIZ, YAĞ, SİLAH, BAHÇE, FİL, DOLAP, FUTBOL, ÇAPA, MASA kelimeleriyle başladığını varsayalım... Bu satırı dinlerken öznenin sözünü tutması gerekir. "fil" görünene kadar "bahçe" kelimesine dikkat edin ve ardından - "fil" kelimesi "masa" görünene kadar vb. listeyi okuduktan sonra telaffuz edin. Sonuç olarak, bireysel kelimeler konunun CP'sinde farklı süreler boyunca tutulur: "bahçe", örneğin "fil" den çok daha kısadır. Bu tür 27 listeyle deneyler yaptıktan sonra, Craik ve Watkins beklenmedik bir şekilde denekten tüm listelerden hatırlayabildiği tüm kelimeleri hatırlamasını istedi. Belirli bir harfle başlayan bir kelimenin hafızada tutulduğu sürenin (bu süre, diğer harflerle başlayan sonraki kelimelerin sayısı ile belirlendi) beklenmedik bir test sırasında hatırlamayı etkilemediği ortaya çıktı. Bu nedenle, belirli bir kelimenin CP'de tutulma süresi, görünüşe göre, uzun süreli bellekteki izinin gücünü etkilemedi.
Başka bir deneyde, Craik ve Watkins, CP'deki belirli bir öğenin yüksek sesle tekrar sayısıyla ölçülen tutma süresinin de hatırlamayı etkilemediğini buldular. Deneklere ücretsiz hatırlama için birkaç kelime listesi sundular. Bazı listelerin sunumdan hemen sonra, diğerlerinin son kelimenin sunumundan 20 saniye sonra geri çağrılması gerekiyordu (gecikmeli oynatmaya sahip bir değişken). Deneklere, her listenin son dört kelimesini hatırlamaya odaklanmaları söylendi ve bunu yapma ihtiyacı hissederlerse yüksek sesle tekrar etmeleri istendi. Deneyciler, her kelime için tekrar sayısını kaydetti. Şaşırtıcı olmayan bir şekilde, son dört kelime gecikmeli olarak doğrudan çoğaltmadan çok daha fazla tekrarlandı. Birkaç listeyle yapılan deneylerden sonra, denekler aniden kendilerine sunulan tüm listelere karşı test edildi. Ve şimdi, anında ve gecikmeli oynatma listelerinde daha önce bulunan (son dört kelimeden) kelimeler arasında hiçbir fark yoktu. Böylece gecikmeli hatırlama listelerinde son dört kelime için çok daha yüksek olan sesli tekrar sayısı ezberleme gücünü etkilememiştir.
Bu tür deneyler, tekrarın uzun süreli bellekteki rolüne ilişkin herhangi bir basit açıklamayı şüpheyle karşılar. Görünüşe göre bazen tekrar bu anlamda etkili oluyor. Ancak yazarlar (Craik ve Watkins, 1973; Woodward a.o., 1973), CP'de tutmak için elemanın basit bir mekanik tekrarının uzun vadeli bir izin sabitlenmesine yol açmadığına inanmaktadır. Güçlü bir ezberlemeye gerçekten katkıda bulunan tekrar, muhtemelen tekrarlanan unsurların da aracılık edildiği, birbirleriyle ilişkilendirildiği ve DP'nin içerdiği bilgilerle temas sonucu zenginleştiği çok karmaşık bir süreçtir. Randus'un deneylerinin gösterdiği gibi, denekler aslında tekrar setleri oluştururken DP'de saklanan bilgileri kullanırlar; bu nedenle tamamen "mekanik" bir tekrarın nispeten nadiren meydana gelmesi oldukça olasıdır. Deneklerin tekrarlanan materyali fark etmeden işlemesi ve karmaşıklaştırması daha olasıdır ve sonuç olarak, genellikle tekrarın ezberlemenin etkinliğini arttırdığı ortaya çıkar.
KISA SÜRELİ BELLEĞİN YAPISI VE KAPASİTESİ
Önceki tartışmadan da görülebileceği gibi, SP için "çalışan bellek" adı çok uygundur. Görünüşe göre, daha önce nispeten pasif bir süreç olarak kabul edilen içinde tutulan malzemenin tekrarı bile, özellikle sunulan bilgilerin arabuluculuğu ve işlenmesi ile oldukça karmaşık bir "iş" ile ilişkilendirilebilir. Benzer aktivite, "yapılandırma" sırasında, yani CP'de mümkün olduğu kadar az yer kaplayacağı böyle bir malzeme gruplaması - sınırlı kapasiteye sahip bir depolama sırasında gerçekleşir. Özünde, malzemenin yapılandırılması ve işleme ile tekrarı, görünüşe göre, aynı madalyonun iki yüzüdür: bilginin arabuluculuğu ve işlenmesi, CP'de minimum yer kaplamasına ve aynı zamanda , bu aynı işlemler uzun süreli bellekte izlerin gücünde bir artışa yol açar. Yapılanma sürecine ve bunun CP'nin kapasitesiyle ilişkisine daha yakından bakmak her şeyi daha net hale getirecektir.
YAPILANDIRMA VE KAPASİTE
CP ile ilgili temel gerçeklerden birini daha önce belirtmiştik: kapasitesi sınırlıdır; aynı anda içinde depolanabilecek bilgi miktarı bilinen bir sınırı geçmemelidir. Bununla ilgili veriler, esas olarak, özneye ilk önce kısa bir öğe listesi sunulduğunda (örneğin, ÇALIŞMA, MT TTT , GÜZ, TUZ, DİSK, ELBİSE, KİTAP) ve ardından istendiğinde, anlık hafıza miktarını belirlerken elde edildi. onları hatırla. Az sayıda öğeyle bu görev zor değildir ve denek listeyi doğru bir şekilde yeniden üretir. Ancak sayıları 7'yi geçerse deneklerin çoğu hata yapmaya başlar. Deneğin hata yapmadan hatırlayabildiği öğe sayısına bellek miktarı denir, ben bunu CP'nin içerebileceği maksimum bilgi miktarı olarak yorumladım. CP'nin aynı anda yaklaşık yedi öğeyi tutabileceği varsayılır, böylece özne tam olarak bu sayıyı hatasız olarak yeniden üretebilir. Daha fazla sayıda öğe sunulduğunda, bazıları CP'de tutulamaz ve denek bunları hatırlayamaz, bu da hatalara yol açar.
Anlık bellek miktarı yaklaşık yedi kelimeye eşit olarak tanımlanabilir; ama aynı zamanda yedi harfe (bu harfler kelime oluşturmuyorsa) veya yedi anlamsız heceye eşittir. Başka bir deyişle, hafıza miktarı bazı belirli birimlerle - kelimeler, harfler veya heceler - ifade edilmez, ancak sunulan öğelerin yaklaşık yedisine eşittir. Böylece denek herhangi bir özel yapıya (X, P, A.F, M, K, I) karşılık gelmezse 7 harfi, 7 kelime oluşturursa daha birçok harfi hatırlayabilir. Bunun nedeni, birçok harften oluşan bir diziyi, eğer bu dizi anlamlı sözcükler oluşturuyorsa, daha büyük birimler dizisi halinde yeniden kodlayabilmesidir . Bu tür yeniden kodlama - bireysel uyaranların (harflerin) daha büyük birimler (sözcükler) halinde birleştirilmesi - yapılandırma (parçalama) olarak adlandırılır. Buna göre ortaya çıkan birimlere yapısal birimler (yığınlar) adı verilir. Bu terim, yapısal birimlerle ölçülen bellek miktarının "Sihirli Yedi Numara artı veya eksi iki"ye eşit olduğu şeklindeki, artık ünlü olan ifadenin de sahibi olan Miller (Miller, 1956) tarafından tanıtıldı.
Miller, 5'ten 9'a kadar olan bu "sihirli" sayı aralığına karşılık gelen diğer bazı boyutları tartıştı, ancak konumuzla bağlantılı olarak, CP hakkındaki fikirleri özellikle önemlidir: kısa süreli belleğin boyutu, değişebilen birimlerle ölçülür. iç yapılarında çok yaygın. CP'nin kapasite birimi bir yapısal birime karşılık gelir ve yapısal birim oldukça değişken bir şeydir, koşullara bağlı olarak farklı miktarda bilgi içerir.
Yapısal birim kavramıyla ilgili zorluklardan biri, tanımının bizi bir kısır döngüye sokmasıdır: bir yandan, yapısal birimleri bir CP'de yaklaşık yedi olabilen öğeler olarak tanımlarız ve diğer yandan CP hacminin yedi yapısal birime karşılık geldiğini iddia ediyoruz. Başka bir deyişle, CP'nin hacmi, yedi parçanın içine yerleştirildiği bu tür yedi birime eşittir. Bunda pek bir anlam yok ve yapısal birimi başka bir şekilde tanımlamanın bir yolunun kesinlikle bulunması gerekiyor. Tabii ki, çoğu zaman yapısal birimin doğasını farklı bir şekilde tanımlamak mümkündür. Özneye birkaç üç harfli kelime oluşturan (örneğin, K, O, T, B, O, R, C, A, L) sıralı bir harf dizisi şeklinde sunduğumuzu varsayalım. Bu durumda, deneğin yaklaşık 21 harfi (7 kelimeden oluşan) hatırlayabildiği ve doğrudan hatırlama için testte bunları yeniden üretebildiği ortaya çıkabilir. Bu durumda, bir birimin öznenin yediyi hatırlayabileceği bir öğe olduğunu varsayarsak, bir yapısal birim bir kelimeye karşılık gelir. Ancak kelimeleri bildiğimiz için bir yapı birimi de bir kelimeye karşılık gelir. Başka bir deyişle, öznenin 21 harfi (7 değil) hatırlayabileceğini önceden tahmin edebiliriz, çünkü bu durumda yapısal birim kelimedir. Bu nedenle, bir yapısal birimi tanımlamanın iki yolu - bellek miktarına dayalı olarak ve bir birime neyin karşılık geldiği hakkındaki fikirlerimize dayalı olarak - birbiriyle tutarlıdır.
Yapısal birim kavramının başka bir teyidi daha vardır: Yapısal birim olarak sezgisel olarak değerlendirebileceğimiz şeyi değiştirirsek, bellek miktarı bu türden yaklaşık yedi birime karşılık gelen sabit kalacaktır. Bu kavramın bir testi Simon (Simon, 1974) tarafından, kendisini denek olarak kullanarak gerçekleştirildi. Hata yapmadan doğrudan hatırlayabildiği malzeme miktarının yaklaşık 7 tek heceli kelime, yaklaşık 7 iki heceli ve 6 üç heceli olduğunu buldu. Şimdiye kadar, tüm bunlar yapılanma kavramıyla iyi bir uyum içindedir. Değişikliklere rağmen bellek miktarı yedi birim seviyesinde kalıyor. Bununla birlikte, Simon yalnızca dört anlamlı iki kelimelik kombinasyonu (SAMAN YOLU, DİFERANSİYEL HESAP veya CEZA KODU gibi) ve yalnızca üç uzun cümleyi (IN A SOME KINGDOM, IN A SOME STATE veya HİÇBİR ŞEY SONSUZA KADAR AYIN ALTINDA YOKTUR gibi) hatırlayabildi ). Yaklaşık yedi birime eşit olan CP hacminin sabitliği hakkındaki ifadenin genel olarak doğru olduğu sonucuna vardı, ancak bu ifade doğru olmaktan uzak, çünkü aldığımız şeyin boyutunda bir artışla birlikte. Yapısal bir birim olan CP'nin bu birimlerle ölçülen kapasitesi azalır. Ve yapısal birimin tanımına göre bu kapasite sabit kalmalıdır.
Simon'ın da belirttiği gibi, yapısal birimin tanımıyla ilgili temel sorun, bu birimin anlık bellek miktarını ölçmek için kullanılması, ancak aynı zamanda doğrudan hatırlama için görevlerin sonuçlarından türetilen bir kavram olmasıdır. Yapısal birimlerin bir rol oynayacağı başka bir durum bulmak mümkün olsaydı, o zaman bu diğer durum yapısal birimi bağımsız olarak tanımlamak için kullanılabilirdi. Daha sonra, doğrudan hatırlama görevlerinde yapısal birimin rolünü değerlendirmek için bu tanım kullanılabilirse, o zaman yapısal birim kavramı daha anlamlı olacaktır.
Simon'ın gerekçesini daha ayrıntılı olarak ele alın. Her şeyden önce, CP hacminin yedi yapısal birime eşit kabul edildiğini not ediyoruz; bu, doğrudan hatırlama görevlerinde çoğaltılabilecek hece sayısının yaklaşık olarak bir yapısal birimdeki hece sayısına eşit olduğu anlamına gelir. yedi tarafından (Örneğin, yapısal birim iki heceli bir kelimeyse, o zaman 7x2'yi, yani 14 heceyi hatırlayabiliriz.) Dolayısıyla, yapısal birim başına hece sayısının (biz S olarak belirtiyoruz) ortalama olarak 1 olduğunu söyleyebiliriz. Hatırlanan hece sayısının /7'si (R olarak gösterelim) veya S=l/7 R. Bu, herhangi bir uyarıcı malzeme için yapısal birimin (S) değerini, bu malzemenin (R) yeniden üretilmesiyle tahmin etmemizi sağlar. . Bununla birlikte, bu denklem tek başına CP'nin 7 yapısal birim içerdiği hipotezini doğrulamak veya çürütmek için yeterli değildir, çünkü CP altındaki yapısal birimin boyutuna ilişkin herhangi bir tahminde bulunabiliriz: ideal olarak karşılık gelecek olan bilginin depolanması ve işlenmesi bu denkleme
Bu nedenle, yapısal birimlerin belirli bir rol oynayacağı CP hacmindeki problemden farklı bir şey bulmak gerekiyor ve Simon bunun için ezberci öğrenmeyi önerdi. Bir hece listesini ezberlemek için gereken sürenin, bu hecelerin yapısal birimler halinde ne ölçüde birleştirildiğine bağlı olabileceğini öne sürdü. Örneğin, belirli bir süre içinde ezberlenebilecek hece sayısı, bu hecelerin kelimelerde ne ölçüde birleştirildiğine bağlıdır. Verilen heceleri yapısal birimler halinde birleştirmek ne kadar kolaysa, o kadar hızlı ezberlenebilecekleri beklenebilir. Bu, genel olarak herhangi bir mekanik öğrenme için geçerlidir, örneğin, öğe dizilerini veya eşleştirilmiş ilişkileri ezberlemek.
Bu "öğrenme-yapılandırma hipotezini" şu şekilde formüle edelim: F=kS, burada S yapısal birimin değeri (daha önce olduğu gibi hecelerde) ve F belirli bir sürede ezberlenebilen hece sayısıdır, örneğin, bir dakikada. Bu denklemden görülebileceği gibi, herhangi bir malzeme için, bir dakikada ezberlenebilen hece sayısı, bir yapısal birimdeki hece sayısıyla orantılıdır ve orantı katsayısı, sayıya benzer, bilinmeyen bir k sabitidir. Yedi yapısal birimde 7. "İki oranımız dışında - S = 1 / 7 R ve S = l / k F - yapısal birim S'nin değeri, 1 / 7 R = 11 / k F elde ederiz. herhangi bir materyal için geçerlidir (örneğin, iki heceli kelimeler). bu, ezberlenen hecelerin toplam sayısını ezberlemek için harcanan zamana bölmek için yeterlidir.Bunu iki heceli kelimeler (tip 1) ve anlamsız heceler (tip 2) gibi iki farklı malzeme türü için yapabilirsiniz, sonra 1/ 7 Rı =1/7 Fı ve 1/7 R2 =1/7 F2, burada alt simgeler montaj ilişkisi tipini gösterir riyal. Bu ifadeleri birbirine bölerek Rı/R2= F1/F2 elde ederiz. Bu durumda bilinmeyen k değeri elenir ve nihai oran, CP hacminin yedi yapısal birime eşit olduğu varsayımına bile bağlı değildir.
Böylece, Rı/R.2= F1/F2 eşitliği yapısal birim kavramının tutarlılığını kontrol etmeyi mümkün kılar. Yapılandırmanın iki farklı görevin (dönmeli öğrenme ve doğrudan hatırlama) performansında rol oynadığı varsayılır ve bu iki görevle ve herhangi iki malzeme seti kullanılarak yapılan deneylerde elde edilen sonuçların oranının (R1) olması beklenebilir. /R2 ve F1/ F2) eşit olacaktır. Simon bu varsayımı test etti ve belirli sınırlar içinde iki oranın gerçekten eşit olduğunu buldu. Böylece, yapılanma kavramı bir miktar onay aldı ve CP hacminin gerçekten de yaklaşık yedi yapısal birime eşit olduğunu varsaymak makul görünüyor.
Artık deneklerin CP'de aynı anda tutabildikleri bilgi miktarını, bu bilgiyi yapısal birimler halinde yeniden kodlayarak artırabileceklerine inanmak için yeterli nedenimiz var. Tabii ki, hafıza miktarındaki bu tür bir artış, ancak özne yapısal birimin kodunu çözebilir ve bileşenlerini geri yükleyebilirse faydalı olacaktır. Örneğin, doğrudan hatırlama görevinde dört harfli bir dizi "S, M, L, T" ile sunulan bir denek, bunu tek kelimelik yapısal birim "Uçak" olarak yeniden kodlayabilir. Daha sonra hatırlama sırasında bir hata yapabilir ve yeniden üretebilir, örneğin "S, A, L, T." Bu durumda yapılandırma, tüm harfleri hatırlamasına yardımcı olmadı. Ancak, kural olarak yapılandırma, CP'nin sınırlı kapasitesini artırmamıza yardımcı olur.
YAPILANDIRMA SÜRECİ
Gördüğümüz gibi CP, farklı şeylerin yerleştirildiği ve gelişigüzel bir şekilde depolandığı bir depo değil, bilginin çeşitli etkilere tabi tutulabildiği ve çeşitli şekillerde depolanabildiği bir sistemdir. Açıkçası, CP'deki materyali yapılandırırken, DP'de depolanan bilgiler kullanılır - örneğin, kelimelerin doğru yazılışı hakkında bilgiler. DP'den gelen bilgiler, harici olarak ilgisiz bir dizi öğeye bir yapı vermenizi sağlar; bu olmadan yapısal birimlerin oluşumu imkansız olurdu. Böylece yapılandırma, tıpkı tekrarlama gibi, arabuluculukla ilişkilendirilir.
Yapılanma sürecinin bu özelliğine dayanarak, bunun için hangi koşulların gerekli olduğu tahmin edilebilir. İlk olarak, yapılandırma genellikle bilginin CP'ye girdiği anda gerçekleşir, bu da birleştirilecek malzemenin aşağı yukarı aynı anda CP'ye girmesi gerektiği anlamına gelir (bu harfler rastgele dağılmışsa, üç harfi bir kelimede birleştirmek zor olacaktır. 21 harf). İkinci olarak, eğer birleştirilen elemanların belirli bir birim oluşturmalarına izin veren bir tür içsel yakınlığı varsa, yapılanma kolaylaştırılmalıdır. Özellikle, bir uyaran grubu DP'deki bazı kodlara karşılık gelen bir yapıya sahipse, bu uyaranların bu koda karşılık gelen yapısal bir birim oluşturmasını bekleyebiliriz.
Bower (Bower, 1970, 1972a; Bower ve Springston, 1970), sunulan öğelerin birleştirilme şeklini ve bunların DP'de depolanan bilgilerle ne kadar iyi eşleştiğini değiştirerek yapılandırmanın bu yönlerinden bazılarını araştırdı. Bazı eserlerinde, harf dizilerindeki harflerin gruplamasını değiştirmiştir. Bu tür gruplandırmanın yöntemlerinden biri de geçici bölmeydi. Denekler, harflerin işitsel algısındaki hafıza miktarını belirleme görevini yerine getirdiler. Harfleri isimlendiren deneyci, onları kısa duraklamalarla ayırdı, bunların konumu ve süresi değişti. Örneğin, o
UFO... ONFR... GF... NRYU. Bu diziyi dinleyen denekler, aynı harfler farklı bir şekilde sunulanlara göre daha az harf ezberlediler: UF ... UN ... FRG ... FNRY, harflerin sayısı kadar, İkili, üçlü ve dörtlü grupların sayısı Her iki durumda da harfler aynıydı. Bower, harfleri renk gruplaması ile görsel olarak sunarken yaklaşık olarak aynı sonuçları elde etti (sonraki satırlarda büyük ve küçük harfler farklı renklerdeydi):
UFOonfrGFnryu veya UFOonfrGFnryu
Bower'ın deneylerinin gösterdiği gibi, kısaltmalar (harf kısaltmaları) gibi bilinen harf kombinasyonları, özellikle giriş sinyallerinin bu kombinasyonlara karşılık geldiğini görmenin kolay olduğu durumlarda yapılandırma için temel oluşturabilir. Yapısal birimler, harf listelerinden daha karmaşık malzemelerle sunulduğunda da ortaya çıkabilir, ancak yapılandırma ilkeleri aynı kalır. Bu, anlamlı bir İngilizce metne "yaklaşım sırası" bakımından farklılık gösteren kelime listelerinin aynen yeniden üretilmesiyle ilgili deneylerle gösterilmektedir. Miller ve Selfridge (Miller ve Selfridge, 1950) tarafından geliştirilen "yaklaşım sırası" kavramı, İngilizce metinle benzerlik derecesini karakterize eden bir dizi kelimenin belirli bir özelliği ile ilgilidir. En az benzerlik, basitçe rastgele alınan İngilizce kelimelerin bir listesi olan sıfır sıra yaklaşımı durumunda ortaya çıkar. Birinci mertebe yaklaşımı, sıfır mertebesine benzer; sadece kelimelerin bir metinden alınması bakımından farklılık gösterir. Bu nedenle, birinci sıradaki listelerde farklı kelimelerin geçme sıklığı, dildeki kullanım sıklığını yansıtır. İkinci dereceden listeler deneklerin katılımıyla oluşturulur. İlk olarak, bir deneğe THE gibi yaygın bir kelime denir ve bu kelimeyi bir cümlede kullanması istenir. Konu, "Gökyüzü düşüyor" cümlesini söyleyebilir. Daha sonra bu cümledeki (GÖK) kelimesinden sonra gelen kelime, bu ikinci kelimeyi bir cümlede kullanan başka bir özneye sunulur, örneğin "Gökte kuşlar vardır". Bu ifadede ikinci konuya sunulan kelimeyi takip eden kelime, yani e. ARE, üçüncüye önerin ve yeterince uzun bir kelime listesi ("sky ahe...") elde edilene kadar devam edin. Üçüncü ve daha yüksek dereceli tahminler için, aynı prosedür kullanılır, ancak her bir öznenin cümleleri oluşturmak için kullandıkları iki veya daha fazla ardışık kelime olarak adlandırılması farkı vardır. Yaklaştırma sırası arttıkça, listeye yeni bir sözcük eklendiğinde mevcut olan bağlam miktarı artar ve liste giderek daha çok İngilizce nesir gibi olur. En yüksek benzerlik, yedinci dereceden bir yaklaşımla elde edilir ve ardından gerçek metin gelir. İşte bazı flamalar. 1. derece yakınlaştırma: "yetenekleri yanında ben sana vals yapmak için 4. sıra: "futbol maçının Ocak gece yarısı biteceğini gördüm"; 7. sıra: "daha önce onu azarladıktan sonra müzikteki yeteneklerini fark et" (Miller a. Selfridge, 1950).
İngilizce cümlelere benzerliği ölçülebilen kelime sıraları, yapılandırma sürecini incelemek için yararlıdır. Miller ve Selfridge (Miller ve Selfridge, 1950), bir kelime listesinin anında çoğaltılmasının İngilizce metne yaklaştıkça geliştiğini keşfettiler. Bu bağımlılık kendini en açık şekilde sıfırdan yaklaşık üçüncü mertebeye kadar olan aralıkta gösterdi. Denekler, İngilizce bilgilerini anında hatırlamayı kolaylaştırmak için kullanmış gibi görünüyor, bu da bir tür arabuluculuk sürecine, belki de yapılandırmaya başvurdukları anlamına geliyor.
Tulving ve Patkau tarafından yapılan deneyde (Tulving ve Patkau, 1962) bunun yapılandırmayı kullandığı gerçeği lehine, İngilizce metne yakınlık dereceleri değişen 24 kelimelik listeler oluşturdular. Daha sonra bu listeleri deneklere doğrudan hatırlamaları için sundular. Deneklerin yanıtlarını inceleyen Tulving ve Patko, "ödünç alınan yapısal birim" adını verdikleri bir birim belirlediler. Bu, çıktıda (konu tarafından çoğaltılan kelimelerde) girişte (sunulan listede) bazı dizilere karşılık gelen böyle bir öğe gruplamasıdır. Yani, örneğin, listede "futbol maçı gördüm Ocak gece yarısı bitecek" dizisi yer alıyorsa ve deneğin cevabı "gece yarısı görülen futbol maçı gece yarısı bitecek" ise, ödünç alınan aşağıdaki ifadeyi kullandığı kabul edilecektir. yapısal birimler: 1) "futbol maçı", 2) "gördüm", 3) "gece yarısı" n 4) "bitecek". Bu tür birimlere "yapısal" adı verildi çünkü her birinde, hatırlama sırasında öğeler sunulan listedekiyle aynı sırada gruplandırıldı ve bu, ödünç alınan her yapısal birimin parçası olan kelimelerin gruplandırıldığını düşünmeyi mümkün kıldı. (yapılandırılmış) sunum zamanında konuya göre.
Tulving ve Patkau (1962) tarafından elde edilen sonuçlar, kelime listelerinin ezberlenmesinde yapılanma sürecinin kullanımına ilişkin ilginç göstergeler sunmaktadır. Birincisi, tıpkı Miller ve Selfridge'in deneylerinde olduğu gibi, hatırlanan sözcüklerin sayısı doğrudan İngilizce metne yaklaşma sırasına bağlıydı. İkinci olarak, deneklerin, yaklaşım sırasına bakılmaksızın, ödünç alınan 5-6 yapısal birimi her zaman hatırladıkları ortaya çıktı. Metne yaklaştıkça sonuçlardaki gelişme (hatırlanan sözcüklerin sayısındaki artış), öznenin daha fazla yapısal birimi hatırlamasından değil, yapısal birimin ortalama olarak daha fazla sözcük içermesinden kaynaklanmaktadır. Başka bir deyişle, listenin yapısı İngilizce sözdizimine ne kadar yakınsa, yapısal birimlerin o kadar büyük oluşturulabileceği ve daha sonra özne tarafından çağrılabileceği izlenimi yaratılmıştır. Ve her zaman aynı sayıda yapı taşı hatırladığından (hafıza miktarına karşılık gelen bir sayı), daha büyük yapı taşları yaratma yeteneği, daha fazla kelime hatırlamasını sağladı. Kısacası, İngiliz dilinin yapısının bazı özellikleri, görünüşe göre, büyük yapısal birimlerin oluşumuna katkıda bulunur.
İngilizce cümlelerde bulunan hangi faktörün yapısal birimin boyutunda bir artışa yol açtığı açık değildir. Yapılanma, kelimelerin cümlelerde nasıl birleştirilmesi gerektiğini belirleyen sözdizimi kurallarına dayalı olabilir. Örneğin, sözdizimi kurallarından biri, bir cümlenin bir isim tümcesi (özne) ve ardından bir fiil tümcesi (yüklem) içermesi gerektiğini belirtir.
Örneğin, "The boy run" cümlesi İngilizce dilbilgisi açısından doğrudur, ancak "Ran the boy" yanlıştır. İngilizce konuşan herkes sözdizimi kurallarını öğrenir ve muhtemelen İngilizce metnin yapılandırılmasına yol açan bu kuralların bilgisidir. Sözcük listeleri İngilizce metne ne kadar yakınsa, İngiliz dilinin sözdizimine o kadar iyi uyar; bu yapılandırmayı kolaylaştırabilir.
Sözdizimi kurallarının yapılanmaya yol açtığına dair kanıtlar, özellikle Johnson'ın (Johnson, 1968) deneylerinde deneklerin sayısal uyaranlara yanıt olarak tüm cümleleri telaffuz etmeleri için eğitilmesinden gelir. Bu durumda, çift ilişkilendirme yöntemi kullanıldı. Örneğin denek, "Yedi" uyaranına yanıt olarak "Tali çocuk ölmekte olan kadını kurtardı" cümlesini söylemek zorunda kaldı.
Öznenin cümlenin sadece bir kısmını hatırladığında yaptığı hatalar özellikle ilgi çekicidir. Johnson, cümleleri ezberlerken, deneklerin kelimeleri daha yüksek mertebeden birimler halinde yeniden kodlaması veya yapılandırması gerçeğinden yola çıktı. Örneğin, "the" + sıfat + isim sözcük dizisini yapılandırmanın bir sonucu olarak, bir ad tamlaması elde edebilirsiniz . Her bir birimin içindeki sözcükler, başka herhangi bir birimin sözcüklerinden çok açıkça birbirlerine bağlıdır. Ve bu, belirli bir birimin parçası olan bir kelimenin hatırlanmasının, başka bir üniteden kelimelerin hatırlanmasından çok, o kelimede yer alan diğer kelimelerin hatırlanmasıyla daha yakından ilişkili olacağını tahmin etmeyi mümkün kılar. Özellikle bitişik iki kelimeyi hatırlama olasılığı, bunların bir veya iki farklı birimde olmasına bağlı olarak farklı olacaktır.
Johnson, bu hipotezi test etmek için geçiş hatası olasılığını (TOP) hesapladı. RRP, belirli bir cümledeki bir kelimenin yanlış hatırlanırken önceki kelimenin doğru hatırlanmasının yüzdesi olarak tanımlanır. Örneğin, "Tali oğlan ölmekte olan kadını kurtardı" cümlesinde, "UZUN" ve "ERKEK" arasındaki GP, "ERKEK" yerine deneklerin vakaların yüzde kaçında "UZUN" kelimesini doğru bir şekilde hatırlayarak başka bir kelime dediğini belirler. ". Birbiriyle yakından ilişkili kelimeler için GP'nin düşük olması beklenmelidir, çünkü bir kelimeyi doğru hatırlayan denek, büyük olasılıkla kendisiyle yakından ilişkili bir sonraki kelimeyi de doğru bir şekilde adlandıracaktır. Deneklerin cümleleri ayrı yapı birimlerinde ezberledikleri hipotezine göre, bitişik iki kelime için GEP'in bu kelimeler farklı yapısal birimlere aitse daha yüksek, aynı birime aitse daha düşük olacağı öngörülebilir. Bu, kelimeler arasındaki yüksek bir VOP'nin, aralarında yakın bir ilişki olmadığı anlamına geldiği önerisinden kaynaklanmaktadır.
GP, iki bitişik kelime arasındaki ilişkinin bir ölçüsü olarak hizmet ettiğinden (düşük bir GP'ye karşılık gelen yakın bir ilişki ile), yapılandırmada sözdizimi kurallarının kullanıldığı hipotezini test edebiliyoruz. Eğer bu doğru olsaydı, GP'nin sözdizimsel birimler arasında yüksek (örneğin özne ve yüklem arasında) ve tek bir birim içinde düşük olması gerektiğini tahmin edebilirdik. Bu tam olarak Johnson'ın bulduğu şeydir (Şekil 5.3). "Tali oğlan ölmekte olan kadını kurtardı" cümlesinde GP 3. 4. kelimeler arasında yüksek çıkmış ve cümlenin bölümleri arasındaki ana bölüm bu kelimeler arasında kurallara göre geçmektedir. sözdizimi. Ve "Caddenin karşısındaki ev yandı" gibi cümlelerde ana bölümler - ve aynı zamanda GP'nin en yüksek değerleri - "ev" ve "karşı" kelimeleri arasındaki ve "sokak" arasındaki sınırlara karşılık gelir. " ve "yandı". Tek bir tümce içinde bile (örneğin "ölmekte olan kadını kurtardı" ifadesinde), VOP değerleri sözdizimi kuralları tarafından belirlenen iç yapıyı yansıtır.
Sıra, 5.3. Dönem Hatası Olasılığı (BOGP iki farklı türdeki cümleler için ÇJbhnâon, infl).
GP'lerin belirlenmesinde elde edilen sonuçlar, c. yapılandırma "sözdizimi kurallarına" dayanmaktadır, ancak dikkate alınması gereken başka bir olasılık daha vardır.Yapılandırma kelime sırasına değil anlama dayalı olabilir: İngilizce sözdizimi kurallarına göre birleştirilen kelimeler de daha anlamlı ifadeler oluşturur. Sözdizimi kuralları, yani belirli bir sözcük sırası, yapılandırmayı kolaylaştıran şey değil, anlamsal faktör olabilir. Johnson, sözcük sırasının sonuçlar üzerinde bir miktar etkisi olduğunu savunur ORP değerlerinin dağılımını karşılaştırır üç farklı türdeki cümleler için: 1) normal, yani anlamlı ve sözdizimsel olarak doğru (örn.
beyaz şarkı söyledi") ve 3) anlamdan ve doğru sözdizimsel yapıdan yoksun rastgele bir kelime dizisi ("Beyaz sahte uyku düz çağırıyor") Şaşırtıcı olmayan bir şekilde, bu üç cümlenin ezberlenme hızı farklıydı - ilk ezberlenenden daha hızlı ezberlendi diğer ikisi ve üçüncüsü Sözdizimsel olarak doğru olan iki cümle (anlamlı ve anlamsız) için MON değerlerinin dağılımının benzer olması, deneklerin anlamın varlığına bakılmaksızın söz dizimi kurallarına göre yapısal birimler oluşturduklarını düşündürmektedir. sözdizimi kurallarına uyulmadan oluşturulmuş bu gruplar.
Yani sözdizimi kesinlikle yapılandırmada bir rol oynar. Ancak anlamlı cümlelerin sözdizimsel olarak doğru fakat anlamsız cümlelere göre çok daha hızlı ezberlenmesi anlamın da önemli olduğunu düşündürmektedir. Diğerleri (çalışmalar (Salzinger a.o., 1962; Tejirian, 1968), anlamsal faktörlerin, üçüncüden daha yüksek yaklaşıklık sıralarında İngilizceye yakınlaştırma deneylerinde özellikle önemli bir rol oynadığını göstermiştir. Tejirian (Tejirian, 1968) yeni kelime satırları aldı İngilizce diline yaklaşan dizilerde değiştirilerek, ayrı kelimeler aynı dilbilgisi kategorisindeki diğer kelimelerdir (sırasıyla isimler, fiiller, sıfatlar vb.) Sözcüklerin bu şekilde değiştirilmesiyle dizinin anlamsal yapısı değişti, ancak sözdizimi kaldı yaklaşık 3 ve altındaki sıralarda, bu tür ikameler hatırlanan kelime sayısını etkilemedi, bu, 1. - 3. seviyede çok daha büyük anlam ve kelime ikamelerinin materyalin yeniden üretimini kötüleştirdiği anlamına gelir.
Yazım, sözdizimi ve anlamın etkisi, yapılandırma sürecinde iyi öğrenilmiş kuralların nasıl kullanılabileceğini gösterir. Bu etkileri tartışırken, kısa süreli bellekten ziyade uzun süreli bellekle ilgili gibi görünen birkaç deneye baktığımızı fark etmişsinizdir. Örneğin, Tulving ve Patco'nun deneylerinde, CP'nin hacmini aşan 24 elementin listeleri kullanıldı, yani DP'nin bunlara katılması gerektiği açıktır. Bununla birlikte, bu tür deneylerin yapılandırma süreçlerini incelemek için yararlı olabileceğini görmek kolaydır, çünkü bu süreçler muhtemelen uzun vadeli korumayı sağlayan bilgilerin işlenmesine benzer olmalıdır. CP'de depolama için materyalin yapılandırılmasında yer alan işlem, karşılık gelen uzun vadeli izlerin gücünü artırdığından, DP çalışması ayrıca CP'de bilgilerin depolanmasına ilişkin değerli bilgiler sağlayabilir.
Denekler bu amaç için özel olarak oluşturulmuş kuralları ezberlerse yapılandırma da kolaylaştırılır. Örneğin, Miller'in deneylerinde (Miller, 1956), deneklere, önce üç basamaklı yapıları tek sayılara çevirmeyi öğrenerek, uzun sıfır ve bir dizilerini daha kısa basamak dizilerine dönüştürmeleri öğretildi): 000=0; 001=1; 010=2; 011=3; 100=4; 101=5; 110=6; 111=7. Daha sonra 001000110001110 gibi bir dizi sunulduğunda bunu üç basamaklı yapılara (001, 000, 110, 001, 110) ayırdılar ve verilen kodu kullanarak bunları ayrı sayılara dönüştürdüler ve sonuç 10616 oldu. , denekler böylece sıfır ve birlerin sayısının 21'e ulaştığı satırları ezberleyebildiler!
Yukarıda açıklanan yapılandırma yöntemi, sözde anımsatıcı cihazlar kategorisine aittir, yani girdi materyalini düzenlemek için özellikle onu daha iyi hatırlamak için tasarlanmış bu tür kurallar. Bu tekniklerin çoğu uzun zamandır biliniyordu, diğerleri ise - Miller tarafından açıklanan sistem gibi - nispeten yakın zamanda oluşturuldu. Bazı anımsatıcı kurallar, belirli bilgileri (örneğin, ay cinsinden gün sayısı) hatırlamak için kullanılır, diğerleri ise herhangi bir sayıda öğe için kullanılabilir. Bu tür evrensel yöntemler, örneğin, yerel bağlama yöntemi veya yerler yöntemi olarak adlandırılan eski bir anımsatıcı tekniği içerir. Bir kişinin önce birkaç yeri ezberlemesinden oluşur - diyebilirsiniz; odada on farklı yer bulun ("TV'de", "duvar saatinin yanında" vb.). Bu yerler daha sonra öğe listelerini ezberlemek için kullanılır. Size on öğelik bir liste sunulduğunu varsayalım. Böyle bir sistemi kullanarak her birini zihinsel olarak birbirine bağlarsınız; ezberlediğiniz yerler ile bu konuların. Örneğin size KÖPEK, ATEŞ, TENCERE, ... derlerse, TV ekranında bir köpek, yanan bir duvar saati vb. Ve hatırlama sürecinde, zihinsel olarak odanın bir kısmından diğerine bakmanız yeterli olacaktır: bir TV hayal ettiğinizde, hemen bir köpeği hatırlarsınız, bir saat hayal ettiğinizde, ateşi hatırlarsınız vb. hafızanızdaki gerekli nesneler.
BİLİNÇ VE KISA SÜRELİ HAFIZA
SP ile ilgili ön tartışmamızda değindiğimiz son şey, bilginin kısa süreli depolanması ile "bilinç" arasındaki ilişkidir. CP'yi çalışan bir bellek olarak gördük, çünkü görünüşe göre burası, girdi öğeleri üzerinde çeşitli işlemlerin - yapılandırma, aracılık veya tekrarlama - gerçekleştirildiği yer. Doğal olarak, bu tür işlemlerin bilinç veya farkındalığın tezahürlerine eşdeğer olup olmadığı sorusu ortaya çıkıyor: "unsurlar üzerinde eylemler gerçekleştirmek", "onlar hakkında düşünmek" ile aynı anlama gelmiyor mu?
Şu anda, bu soru tatmin edici bir şekilde cevaplanmış gibi görünmüyor. Bilinç ne olursa olsun, kısa süreli belleğin "çalışması" ile hemen hemen aynı değildir. Bunu görmek için, bir sohbete katılan bir kişinin, orada bulunan başka bir grup insanda adının geçtiğini duyduğu bir parti örneğini ele alalım. .Adamın adını telaffuz etme gerçeğinden haberdar olduğu söylenebilir. Bu anlamda "farkına varmak", "dikkat et" kelimelerinin ifade ettiği şeye eşdeğer görünmektedir. Ancak Bölüm 1'de tartışılan seçici dikkatin tanımını hatırlarsak. 4, o zaman dikkat ve farkındalık bize eşanlamlı görünmeyecek. Örneğin, bir araba kullandığınızda, onunla ilişkili uyaranların çoğu açıkça tanınır, aksi takdirde bir hendeğe doğru sürersiniz. Bununla birlikte, araba kullanan bir kişinin aynı anda yolcularının yaptığı konuşmayı dinlemesi alışılmadık bir durum değildir. Konuşmanın farkındadır ve araba ile yaptığı her şeyin farkında değildir ama bu arada dikkatinin en azından bir kısmını yola vermektedir (Kahneman, 1973). Bununla birlikte, araba sürmenin dikkat eyleminden ve tam örüntü tanımadan önceki süreçlerin kontrolü altında olduğunu ve farkındalığın tam tanıma ve tam dikkat ile örtüştüğünü varsayabiliriz. Ve bu, özünde, farkındalığın CP'deki bilgilerin kodlanmasına karşılık geldiği ifadesine eşdeğerdir. Bununla birlikte, farkındalığın SP'ye bilgi koymaya karşılık geldiğini söylersek, bir kısır döngü içindeyiz. CP'ye bir şey yerleştirildiğini nasıl anlarız? Evet, çünkü bunun farkındayız; ve aynı zamanda, farkındalığı SP'ye bilgi getirmek olarak tanımlarız. Farkındalık sorunuyla ilgili "mistik" bir şey olduğu izlenimi ediniliyor.
Bunun ışığında, burada Freud'un kısa vadeli ve uzun vadeli bilinç ve hafızanın doğası hakkındaki bazı sözlerini (Freud, 1925) dikkate almak uygun görünüyor. Sözde "sihirli defter" ile bir benzetme yapıyor. Bu, altında başka bir yarı saydam ince mumlu kağıt tabakası bulunan, şeffaf selüloitle kaplı koyu mumsu bir maddeden yapılmış bir levhadır. Kayıtlar sivri bir çubukla selüloit üzerine bastırılarak yapılır. Buna karşılık, selüloit, balmumu pedine yapışan alttaki ince tabakaya baskı yaparak yazılı kelimelerin yüzeyde görünmesine neden olur. Yazdıklarınızı silmek için selüloit ve yağlı kağıdı kaldırmanız yeterlidir ve ardından yeni girişler yapabilirsiniz. Bazen, üstteki iki katmanı dikkatlice kaldırırsanız, sözcükler artık dışarıdan görünmese de, balmumu yüzeyinin hala yazılanları koruduğunu görebilirsiniz.
Freud, insan hafızasını böyle bir cihazla karşılaştırır. Ona göre hafıza iki kısımdan oluşuyor: balmumu levhaya benzeyen kalıcı hafıza ve bilgiyi algılayan ve ortalama bir sayfa ile karşılaştırılabilecek kısa bir süre için saklayan hafıza. Bilinç, bu yenilenebilir, kalıcı olmayan hafıza ile bağlantılıdır: burada bazı bilgiler göründüğünde ortaya çıkar ve bu bilgiler silindiğinde kaybolur. Bütün bunlar, K.P. ve DP olarak tanımladığımız hafıza bölünmesini çok anımsatıyor. Eğer öyleyse, o zaman Freud'un kısa süreli hafıza fenomenini bilincin bir parçası olarak gördüğü anlaşılıyor. Ve "sihirli defterin" üst sayfalarının soyulması, yapılan kaydın kaybolmasına neden olduğu gibi, CP'den bilgi çıkarmak, onun bilincimizden çıkarılmasına yol açabilir. Freud'un haklı olması mümkündür - her halükarda, onun yanıldığını kanıtlayacak durumda değiliz.
Bölüm 6
Kısa süreli hafıza: unutmak
Yardım masasının telefon operatöründen bir arkadaşınızın telefon numarasını istediğinizi düşünün. Size istediğiniz numarayı verir ve siz de diskte çevirmek üzereyken kendi kendinize tekrarlarsınız. Bu sırada arkadaşınız odaya girer ve onu selamlarsınız. Numarayı tekrar aramak istediğinizde, artık hatırlamadığınız ortaya çıkıyor. Kısa süreli hafızanızda yer alan bu sayı ile ilgili bilgiler unutulur.
CP'de bulunan bilgileri unutmaktan, yani basitçe kaybetmekten zaten bahsetmiştik; önceki bölümlerden birinde öne sürdüğümüz gibi, hafıza miktarını belirlemek için yapılan deneylerde yapılan "akustik" hataların altında yatan bu kayıptır. Bu hataları, bazı öğelerin ses izinin bir kısmının unutulmuş olması ve geri çağırmanın CP'de korunan seslere dayanması nedeniyle, yanlışlıkla yeniden üretilen öğenin akustik olarak orijinaline benzemesiyle açıkladık. Görünüşe göre kısmi unutma, CP işlevinin normal bir özelliğidir: içinde depolanan öğeler yavaş yavaş kaybolabilir.
Unutma sürecini detaylı bir şekilde incelediğimiz bu bölümün iki amacı vardır. Amaçlardan biri, HP'de depolanan bilgilerin unutulmasının nedenleri sorusunu gündeme getirmektir; bu sorun uzun süredir var ve bu konuda tartışmalar var. Diğer bir amaç ise unutmayı etkileyen bazı deneysel faktörlere dikkat çekmek ve kısa süreli bilgi depolama konusunda daha fazla veri elde etmeye çalışmaktır.
UNUTMA KURAMLARI
Unutmanın nedenleri sorusuna genellikle iki alternatif bakış açısıyla yaklaşılır - unutma, ya izlerin "pasif olarak yok edilmesi" ya da "müdahalenin" bir sonucu olarak kabul edilir. Bu kavramların anlamını daha net hale getirmek için sorunu basitleştirilmiş bir biçimde sunmaya çalışacağız. CS'de bulunan izin dikkate alınmasıyla başlayalım. Yeni bir izin en yüksek netliğe sahip olduğunu söyleyebiliriz (bu biraz belirsiz bir kavramdır, ancak burada "mevcut bilgi miktarı" veya "tamlığı" anlamına gelir). Belirli bir iz artık en üst düzeyde netliğe sahip olmadığında, örneğin belirli bir öğenin sesiyle ilgili bilgilerin bir kısmı kaybolduğunda, unutmadan söz edilebilir. Bu genellikle yalnızca tekrarın yokluğunda olur, çünkü tekrarın izin orijinal seviyesindeki netliğini koruduğunu varsayarız. Unutma, izin netliğinde, verilen öğenin hafızaya geri yüklenemeyeceği kadar bir azalma ile gerçekleşir. Bizi ilgilendiren asıl soru izin netliğindeki azalmanın sebebidir. Yaygın olarak öne sürülen iki nedeni ele alacağız: 1) pasif yok olma ve 2) müdahale.
Solma genellikle bellek izlerinin netliğinin (veya gücünün) zaman içinde azalması olarak anlaşılır. İzlerin bu şekilde zayıflaması için yalnızca zamana ihtiyaç duyulduğu varsayılır - burada başka hiçbir nedensel faktör söz konusu değildir. Bu yüzden yok oluşa pasif diyoruz. Yok olma hipotezinin aksine, girişim hipotezi, unutmanın nedeninin daha aktif olduğu gerçeğinden hareket eder; bu hipoteze göre, bir veya başka bir unsurun izinin netliği, yeni unsurların gelmesi sonucunda azalır. CP; bu nedenle izlerin zayıflaması sadece zamanın geçmesinden değil, bellekte yeni bilgilerin ortaya çıkmasından kaynaklanmaktadır.
Aşağıdaki deney yapılabilseydi, bu iki hipotezden hangisinin doğru olduğunu tespit etmek zor olmazdı. Öncelikle konuya bir öğe göstermeniz gerekir. Daha sonra denek bir süre, yaklaşık 30 saniye hiçbir şey yapmamalıdır (bu, "tutma aralığı" olarak adlandırılır). "Hiçbir şey" mutlak anlamda anlaşılmalıdır - tekrar yapılmamalıdır (çünkü bu, izin netliğini korumaya yardımcı olacaktır) ve başka şeyler üzerine düşünme yapılmamalıdır (çünkü bu, CP'ye yeni bilgiler getirebilir ve girişim meydana gelebilir). 30'ların sonunda, deneğin sunulan unsuru hatırlaması istenecekti. Hafızasından geri alamazsa, bu, pasif yok olma lehine bir tartışma olurdu, çünkü oyundaki tek faktör geçen zaman olabilir. Bu süre zarfında hiçbir şey parazite neden olamaz. Unsur bu süre zarfında unutulmadıysa , bu gerçeği yok olma hipotezine karşı, yani girişim kavramı lehine bir argüman olarak değerlendirebiliriz.
Ne yazık ki, deneğin kesinlikle hiçbir şey yapmadığı bir durumu hayal etmek imkansız olduğundan, böyle ideal bir deney mümkün değildir. Ancak daha sonra göreceğimiz gibi, bu tür koşullara olabildiğince yaklaşmak için girişimlerde bulunuldu ve sonuçlar oldukça tutarsız oldu.
Bu deneyleri ele almadan önce, iki alternatif hipotezi daha ayrıntılı olarak tartışalım. Önce girişim hipotezini ele alalım. Bu hipotezin bir çeşidi, "basit hücre modeli" veya "yer değiştirme modeli" olarak adlandırılabilir. Bu modele göre, CP'nin belirli sayıda hücresi vardır - 7+2(-2). Her hücre, girdi malzemesinin bir yapısal birimini içerir. Öğeler CP'ye girdiğinde, her öğe (yapısal birim) bir hücreyi kaplar. Tüm hücreler dolduğunda ve yeni öğelere yer kalmadığında, eski öğeler yenilerine yer açmak için bir yere taşınmak zorunda kalacak. Böyle bir modelde, doldurulmuş CP'ye giren her yeni öğe, içindeki öğelerden birini değiştirir ve bu da sonrakinin unutulmasına neden olur. CP'de yer alan öğelerin her birinin bir miktar bastırılma şansı vardır.
Bastırma modeli, CP'de depolanan bilgilerin unutulmasının müdahaleden kaynaklandığı şeklindeki daha genel hipotezi açıklamaya yardımcı olması bakımından ilgi çekicidir. Bu modelin bir sonucu, CS'ye giren ilk birkaç öğenin birbiriyle karışmamasıdır. Açıkçası, CP'deki tüm hücreler dolana kadar unutma gerçekleşmemelidir: yalnızca öğe sayısı CP'nin kapasitesini aştığında başlayacaktır. Modelin bir başka sonucu da şudur: Her bir eleman (veya yapısal birim), bu elemanı içeren veya içermeyen bir hücreyi işgal ettiğinden, her bir elemanın ya tamamen çıkarılması (hücrede olmayacak) veya tamamen yerinde kalması gerekir. Bu arada, bunun böyle olmadığını biliyoruz. CP'de yer alan hecelerin (örneğin, harflerin adlarının) akustik olarak karıştırılması olgusu, bu hecelerin kısmen unutulmasıyla - bireysel fonemlerin izlerinin silinmesiyle - açıklanabilir. Bir hece bir yapısal birime karşılık geliyorsa, bu tür bir kısmi unutma basit hücre modeliyle bağdaşmaz.
Kısmi unutma ile uyumlu hale getirmek için bu basit modeli değiştirmek zor değil. Bunu yapmak için, CP'de bulunan öğenin bütünlüğünün farklı olabileceğini, yani birkaç anlam alabileceğini varsaymak yeterlidir: "tamamen burada", "çoğunlukla burada", "biraz sol", "tamamen kaldırıldı". Modeli bu şekilde değiştirerek, özünde, netlik bilginin eksiksizliğine bağlıysa, belirli bir öğenin izinin eşit derecede net olmayabileceğini kabul ediyoruz. Bu değiştirilmiş formda, bastırma hipotezi, CP'ye giren yeni öğelerin kısmen diğer öğelerin yerini alabileceğini, yani izlerinin netliğinde bir azalmaya neden olabileceğini varsayar.
Basit hücre modelinden çıkan bir ifadenin daha değiştirilmesi gerekiyor, yani CP'de depolanan öğelerin yalnızca öğe sayısı CP'nin hacmini aştığında unutulduğu. Sonuçta unutmak ancak CP'yi doldurduktan sonra mümkünse, yok olma hipotezi ve girişim hipotezi uyumlu hale gelir. Bunu açıklığa kavuşturmak için, iz yok olma hipotezini bellek ikiliği teorisi açısından ele alalım: yok olma hipotezi yalnızca boş bir CP için geçerlidir, çünkü CP'nin sınırlı bir kapasitesi fikri şu kavramı gerektirir: unutmak, CP'ye kaldırabileceğinden daha fazla bilgi girdiğinde başlar. Bu tür bir unutma, edilgen yok oluşa atfedilemez; bu nedenle, sadece CP'deki bilgi miktarı hafıza kapasitesini 1 aşmadığında meydana gelen unutmadan bahsedebiliriz . Bununla birlikte, CP aşırı yüklenmesinin yokluğunda unutmayı açıklamak için en uygun sönümleme hipoteziyse, girişim hipotezi için de benzer bir kısıtlama getirilmelidir. Başka bir deyişle, girişim hipotezimiz, CP'de depolanan bilgilerin yalnızca miktarı CP'nin kapasitesini aştığında unutulabileceğini varsaymamalıdır. Sonuçta, aksi halde iki hipotez arasında bir çelişki olmazdı: yok olma hipotezi, bilgi miktarının CP'nin kapasitesinden daha az olduğu durumları ifade eder ve hipotezler ve müdahale, daha büyük olduğu durumları ifade eder. Kısacası, bastırma hipotezinde bir değişiklik daha yapılmalıdır - müdahalenin, bu bilginin miktarı CP'nin hacmini aşmasa bile, CP'de yer alan bilgilerin unutulmasına yol açabileceği varsayılmalıdır. Başka bir deyişle, CP'de tüm bu öğeler için yeterli alan olsa bile, CP'ye yeni öğelerin eklenmesi, verilen öğeye müdahale edebilir .
Bu formda, girişim hipotezi, CS'de bunun için yeterli alan olsa ve başka hiçbir öğe girmese bile, CS'deki belirli bir öğenin izinin netliğinin kademeli olarak azaldığı solma hipoteziyle çelişir.
1 Sınırlı kısa süreli depolama kapasitesi kavramı tarafından dikte edilen, sönümleme hipotezinin uygulanabilirliğine ilişkin bu sınırlama, sönümleme hakkındaki geleneksel fikirlerden biraz farklıdır. Dualite teorisinin dışında, unutulan bilgi miktarının anlık hafızanın boyutundan daha büyük veya daha az olup olmadığına dair sönümleme hipotezi geçerlidir. Özünde, bellek kapasitesi solmanın bir sonucu olarak görülebilir. Sunulan öğelerin sayısı az olduğunda, bunların tüm izleri, karşılık gelen iz tamamen silinmeden önce meydana gelmesi gereken tekrarla korunabilir; sonuç olarak, geri çağırma sırasında herhangi bir hata oluşmaz. Sunulan öğelerin sayısı çok olduğunda, iz kaybolana kadar her birini tekrarlamak imkansız hale gelir; bu nedenle, oynatma sırasında bazı izler kaybolur ve hatalar oluşur. Böylece, bellek miktarı, henüz hiçbir iz tamamen yok olmadan, zaman içinde tekrar edilebilecek en fazla öğe sayısına göre belirlenebilir.
Girişim hipotezinin başka modifikasyonları da mümkündür. Bazı teorisyenler, müdahalenin CP'ye yeni gönderilen öğeler ile halihazırda içinde bulunanlar arasındaki benzerlik derecesine bağlı olduğuna inanır. Bu varyant, derecesi öğeler arasındaki benzerlik tarafından belirlenmeyen basit "preemption enterferansı" yerine "benzerlik enterferansı" olarak adlandırılabilir.
Yeni, revize edilmiş girişim hipotezimiz aşağıdaki gibidir. CP'de saklanan her iz belirli bir netliğe sahiptir. Belirli bir öğe CP'ye yeni girdiğinde veya tekrarlandığında, izi en üst düzeyde netliğe sahiptir. Unutma, güç o kadar düştükten sonra, öğe artık geri yüklenemez ve yeniden üretilemez hale gelir. Unutmanın nedeni CP'ye yeni unsurların gelmesidir. Unutma derecesinin, bu yeni unsurların orijinal unsurlarla benzerliğine bağlı olduğunu da varsayabiliriz. Yavaş yavaş, CP'ye yeni öğeler girdikçe, daha önce içinde olan öğelerin izleri kaybolur (Şekil 6.1, A). Buna karşılık, pasif yok olma hipotezi, unutmanın diğer unsurlarla müdahale ile değil, yalnızca zamanla belirlendiğini belirtir (Şekil 6.1, B).


Pirinç. Gt I. K (Ts No. OD SHPOTSZOL ntPerfsren-
iiii l gnііbteMJ neslinin tükenmesi (8).
Şekil l'de gösterilen iki 6.1 grafikleri bariz bir şekilde birbirinden farklıdır. Birinde, enterferans derecesi apsis boyunca, diğerinde ise zaman boyunca çizilir. İki hipotezden hangisinin doğru olduğunu bulmak için, teorik (içsel, doğrudan gözlemlenemeyen) değişken "iz koruma"yı açık ve ölçülebilir bir şeye çevirmek gerekir. O zaman bu miktarı neyin etkilediğini belirleyebiliriz: eğer zamanın kendisi hareket ediyorsa, o zaman yok olma hipotezi lehine bir argüman elde ederiz ve eğer karışan unsurlarsa, o zaman girişim hipotezi lehine. İzin korunmasını yansıttığı varsayılan bir ölçü, örneğin, hatırlama görevlerindeki doğru cevapların yüzdesi olabilir. Özneye küçük bir öğeler kümesi sunduğumuzu ve ardından girişim yaratmak için özel olarak tasarlanmış birkaç öğe eklediğimizi ve ardından özneden orijinal kümeyi hatırlamasını istediğimizi varsayalım. Doğru cevapların yüzdesi, müdahale eden öğelerin sayısına bağlı olarak düşüyorsa, bu, girişim hipotezi lehine bir argüman olarak kabul edilebilir.
Ne yazık ki, bu tür deneyler bir takım zorluklarla ilişkilidir. Müdahale eden unsurların tanıtılması biraz zaman alır, bu nedenle özneye bu tür unsurlar ne kadar çok sunulursa o kadar çok zaman geçer. Sonuç olarak, iki değişken - öğelerin sayısı ve zaman miktarı - karıştırılır: birinin artmasıyla diğeri de artar ve hatırlamanın verimliliğini tam olarak neyin kötüleştirdiğini söylemek imkansızdır - zaman veya sayı müdahale eden unsurlardan Faktörlerdeki bu kayma nedeniyle, bu iki hipotezi test etmek için başka bir yöntem aranmalıdır. Zamanın basitçe geçtiği ve müdahalenin olmadığı, yukarıda açıklanan ideal deney, böyle bir yöntem olarak hizmet edebilir. Unutma bu koşullar altında gerçekleşirse, nedeninin zamanın kendisi olduğu açıktır ve bu durumda yok olma teorisi doğrulanmış olacaktır. Unutmak yoksa yok olma teorisini unutmak zorunda kalacağız.
ÇIKARICI İLE DENEYLER
Mükemmel bir deney yapamayız, ancak bu ona yaklaşılamayacağı anlamına gelmez. Bunun için, ilk olarak Brown (Brown, 1958) ve Peterson ve Peterson (Peterson ve Peterson, 1959) tarafından ortaya konulan sözde çeldirici deneyler sıklıkla kullanılır. Peterson'lar, kişinin PC'de sönümleme hipotezi ile girişim hipotezi arasında seçim yapmasına izin veren deneyler geliştirmekle tanınırlar; genel olarak çalışmaları, kısa süreli bellek alanındaki araştırmaların gelişmesine büyük katkı sağlamıştır.
Peterson'lar çok basit bir yöntem kullandılar. Deneklerle aşağıdakilerden oluşan bir dizi test yaptılar. Önce (kulakla) üç ünsüzden (bir trigram), örneğin PSQ harflerinden oluşan bir I satırı ve ardından üç basamaklı bir sayı, örneğin 167 sundular. Bundan sonra, denek atlamalarda geriye doğru saydı. 3 adet (167, 164, 161, 158...) metronomun vuruşuna tutma aralığı adı verilen bir süre için. Ardından, konunun sunulan üç harfi hatırlaması gerektiğine göre bir sinyal verildi.
Bu tür deneylere çeldirici problemler denir; ters sayımın öznenin dikkatini dağıttığına ve ona trigramı oluşturan harfleri tekrar etme fırsatı vermediğine inanılıyor. Bununla birlikte, sayıların daha sonra geri çağrılmak üzere CP'de saklanmaması gerektiğinden, saymanın görünüşte CP'de saklanan trigramın harflerine müdahale etmediği varsayılmaktadır. Böylece, zamanın (tutma aralığı şeklinde) çalıştığı duruma yakın koşullar yaratılır ve özne, müdahale edici bir etkisi olduğuna inanılmayan geri sayım dışında hiçbir şey yapmaz. Konu harfleri unutursa, bu yok olma teorisi lehine bir argümandır.
Petersons deneyinin sonuçları, Şekiller 1 ve 2'de gösterilmektedir. 6.2. Kullandıkları tutma aralıklarında - 3 saniyeden 18 saniyeye kadar - deneğin trigramı hatırlama yeteneği önemli ölçüde azaldı. Bu şaşırtıcıydı - o zamana kadar hafıza araştırmalarında bu kadar hızlı bir unutma gözlemlenmemişti. İlk olarak, o dönemde gerçekleştirilen deneylerin çoğu, uzun madde listeleri, olağan ardışık hatırlama yöntemleri, çift çağrışımları vb. günler. Ve en şaşırtıcı olanı, bu deneyin sonuçlarının CP'deki izlerin pasif olarak yok edilmesiyle kolayca açıklanabilmesi.

Pirinç. 6.2. Artan tutma aralığı ile azalan yeniden üretim yüzdesi (Pcttrsan ve Peterscn, 1950).
Peterson'ların pasif yok olma hipotezi lehine elde ettikleri veriler, hafıza çalışmalarında önemli bir gelişmeydi. Bu, hafızanın dualite teorisinin zaten bilindiği (Hebb, 1949) ancak henüz geniş çapta kabul görmediği bir zamanda gerçekleşti. Ek olarak, o dönemde mevcut olan önemli miktarda veri, uzun süreli hafızadan unutmanın ana nedeninin müdahale olarak kabul edilmesi gerektiğini gösterdi: hafızada bulunan materyal, uzun süre sonra, görünüşe göre yok edildiği için unutuldu. diğer bilgilere göre. Bu nedenle, çeldirici ile yapılan deneyin sonuçları, iki unutma mekanizmasının varlığını öne sürdü - pasif yok olma ve LTP'ye müdahale ve bu, iki bellek sistemine karşılık gelen iki tür unutma olasılığını kuvvetle önerdi. Başka bir deyişle, Peterson'ların kısa aralıklarla solmanın etkisine ilişkin verileri ve diğer yazarların uzun aralıklarla girişimin etkisine ilişkin verileri, unutmanın iki farklı bilgi deposunda meydana geldiği gerçeğine bağlanabilir. CP ve DP'de.
Bütün bunlar, bir tür hafıza konusunda daha rahat olan teorisyenlerin, şu ya da bu şekilde Peterson'ların sonuçlarının daha önce bilinmeyen bir kısa süreli hafızanın varlığını göstermediğini gösterme göreviyle karşı karşıya kalmalarına yol açtı. hangi unutma, yok olma ile gerçekleşir. KP kavramını çürütmenin en umut verici yolu, müdahalenin gerçekten de kısa vadeli unutmayla ilgili olduğunu kanıtlamak olacaktır. Bunun nasıl yapılabileceğini anlamak için, DP'de unutmanın nedeni olarak girişim hakkında bildiklerimizi hayal etmemiz gerekiyor. Verilerin çoğu, sözde proaktif inhibisyon (PT) ve retroaktif inhibisyon (RT) ile deneylerde çift ilişkilendirme yöntemiyle elde edildi.
PT ve RT ile deneylerin şeması, Şek. 6.3. Bu iki fenomenden geriye dönük engelleme (RT), girişim dediğimiz şeye daha yakındır: burada yeni bilginin, daha önce öğrenilen materyalin hafızada tutulması üzerindeki olumsuz etkisinden bahsediyoruz; bu nedenle böyle bir engellemeye geriye dönük denir. RT ölçülürken, kısa süreli hafıza çalışırken sıklıkla olduğu gibi, genellikle bir değil, birkaç öğe listesi kullanılır. RT ile yapılan deneylerde, iki grup denek katılır - deneysel ve kontrol. Deney grubu, iki eşli çağrışım listesini ezberler - önce "liste A" ve sonra "slip B".
Denekler, hatırlama etkinliği belirli bir seviyeye gelene kadar her listeyi ezberler - örneğin, listenin tek bir hatasız üç kez oynatılması gerekebilir. Daha sonra, akılda tutma aralığından sonra, deneklerden öğrendikleri listelerin ilki olan A listesini yeniden oluşturmaları istenir. Kontrol grubu da aynısını yapar, tek fark deneklerin B listesini ezberlememesidir. Bu deneylerde gösterildiği gibi, kontrol grubunda hatırlama etkinliği deney grubuna göre daha yüksektir. Bunun nedeni muhtemelen, sadece deney grubu tarafından gerçekleştirilen B listesinin ezberlenmesinin, A listesinin bellek izleri üzerinde yıkıcı (müdahale edici) bir etkiye sahip olmasından kaynaklanmaktadır.
Geriye dönük frenleme (RG)
Zaman
Ltsrmozhenis (PT)
zaman >
Pfc. 6.3. Geriye dönük ve proaktif inhibisyon (RT ve PG) ile deney şeması . B listesinin ezberlenmesi, A listesinin ezberlenmesini kötüleştirdiğinde , geriye dönük engellemeden söz edilir; A listesi £І№SKY B'yi zasіfmngtakke yapmayı zorlaştırıyorsa , O ZAMAN BU BUDSTORM OZH CJİ IV IS,
Peterson'ların deneylerinde geçmişe dönük ketleme gerçekleşmiş olabilir mi? Geri sayım bellekte depolanan trigrama müdahale ederse cevap evet olacaktır. O zamanlar bu pek olası görünmüyordu, çünkü sayım yeni bilgilerin bellekte tutulmasını gerektirmiyordu. Ayrıca sayarken çağrılan sayılar, hatırlanması gereken harflerden çok farklıydı. Peterson'lar araştırmalarını yaparken, hatırlanacak malzeme (Liste A) ve engelleyici malzeme (Liste B) benzer olduğunda etkisinin büyük, farklı olduğunda etkisinin küçük olduğu RT hakkında iyi biliniyordu. Ve görünüşe göre sayılar harflere benzemediği için, girişim teorisinin destekçileri, bellekte depolanan trigramın saymanın yarattığı RT'nin etkisi altında unutulduğunu göstermeye çalışmadılar.
Kısa süreli bellekte saklanan bilgileri unutmanın başka bir olası nedeni olarak proaktif engellemeden (PT) daha önce bahsetmiştik. PT çalışma yöntemi, RT çalışma yöntemine çok benzer, ancak burada yalnızca zaman içinde ters yönde yönlendirilen girişimle ilgileniyorlar - A listesini ezberlemenin, ondan sonra ezberlenen B listesini hatırlama üzerindeki etkisi ; tutma aralığı geçtikten sonra bu ikinci listenin ezberlenmesi kontrol edilir (Şekil 6.3). Genellikle, önce A listesini ezberleyen ve ardından B listesini ezberleyen deney grubu, B listesini A listesini ezberlemeyen kontrol grubundan daha kötü yeniden üretti. Bu gibi durumlarda, deney grubunda proaktif inhibisyonun tezahüründen bahsedebiliriz.
Peterson'ların deneyinde unutmanın nedeni proaktif ketleme olabilir mi? Bu deneyde bariz bir PT kaynağı yoktu, çünkü öyle görünüyor ki, her testte bir trigram sunumunun bir sınırı yok: unutmak, herhangi bir materyalin ezberlenmesini takip etti. Ancak sonuca varmak için acele edilmemelidir; çünkü her numune kendi başına yapılmaz, ancak uzun bir başka numuneler dizisine dahil edilir ve bu nedenle önceki numunelerin sonraki numuneler üzerinde bir etkisinin olması mümkündür. PT'nin böyle bir etkisi, deneyin kurulma şekli tarafından gizlendiğinden, Peterson'ların verilerinde açıkça ortaya konamadı.
Şöyle mantık yürütebiliriz. Petersons'ın deneylerinde denekler iki eğitim denemesine, ardından 48 denemeye (altı farklı tutma aralığının her birinde 8 deneme) katıldı. Bildiğiniz gibi, proaktif engelleme hızla maksimuma çıkar. Bu nedenle, bir listeyi öğrenmenin diğerini ezberleme ve hatırlama üzerindeki olumsuz etkisi büyük olsa da, iki listeyi öğrenmenin etkisi birinin etkisinden çok daha büyük olmayacak ve beş listenin etkisi diğerinden çok daha büyük olacaktır. dördün etkisi. Bu nedenle, Petersonov deneyinde, PT'nin ilk birkaç denemede (iki eğitim denemesi dahil) hızlı bir şekilde maksimuma ulaşması ve ardından 48. denemeye kadar maksimum seviyede olması beklenir. AT'nin burada tezahür edip etmediğini bulmak için, her konu için yalnızca ilk birkaç örneği dikkate almak, tüm tutma aralıklarının birbirini izleyen örnekler arasında eşit olarak dağıtılmasını sağlamak gerekli olacaktır.
Yukarıdaki akıl yürütme Keppel ve Underwood'dan kaynaklanmaktadır (Kerrey ve ark.
Underwood, 1962), ilgili deneyi kuran kişi. Dikkat dağıtıcı deneylerde proaktif ketlemenin işe yarayıp yaramadığını bulmaya çalıştılar. Bunu yapmak için, her denekle en fazla birkaç deneme yapmaları ve ek olarak, her akılda tutma aralığının birinci, ikinci vb. denemelerle eşit sıklıkta birleştirildiğinden emin olmaları gerekiyordu. Bunu, üç tutma aralığı, denek başına üç örnek (her aralık için bir) ve çok sayıda denek kullanarak başardılar. Elde edilen veriler Şekil 1 de gösterilmiştir. 6.4.

Hendek. 6.4. Vurucu ve menton'un mom.ia'nın kısa süreli tutulmasına ilişkin sonuçları gösteriliyor. tekrar üretilebilirlik yüzdesinin yalnızca tutma aralığına değil, aynı zamanda önceki örneklerin sayısına da bağlı olduğu (Kerrei a. UnrferwocxJ, ISÛ2).
Keppel ve Underwood'un deneylerinin sonuçları, hafıza birliği teorisinin destekçileri için büyük önem taşıyordu. İlk deneme için elde edilen veriler, 18 saniyelik süre boyunca herhangi bir unutmanın gerçekleşmediğini göstermektedir. Ancak sonraki denemelerde PT'de artış olasılığı yaratıldığında, daha önce Peterson'lar tarafından gözlemlenen hızlı bir unutma bulundu. Görünüşe göre, bilgilerin uzun süreli depolanması sırasında unutmayı yöneten yasalar, yani proaktif engelleme yasaları, aynı zamanda, müdahalenin sonucu olan kısa süreli bellekten sözde unutmanın zamanını da belirler.
Keppel ve Underwood, Petersons deneyinde gözlemlenen kısa süreli hafıza unutmasını proaktif ketlemenin etkisindeki değişikliklere bağladılar. PT'yi geleneksel yöntemle incelerken, tutma aralığındaki artışla birlikte TP'de bir artış gözlendi (Şekil 6.3'te bu, B listesinin ezberlenmesi ile çoğaltılması arasındaki süredir). Bu, tutma aralığı sırasında A listesi izlerinin gücünün (başlangıçta öğrenme listesi B'nin bir sonucu olarak azaldı) restorasyonu ile açıklandı. A listesinin yenilenmesi, muhtemelen liste B ile daha fazla etkileşime girmesine neden olur. Bir çeldirici ile yapılan deneylerde, benzer bir etki, 18 saniyelik bir aradan sonra, proaktif inhibisyonun 3 saniyelik bir aralıktan sonra olduğundan daha fazla olması gerektiği anlamına gelir. gözle görülür bir unutmaya yol açar. Tabii ki, bu sadece artabilecek bazı PT varsa, yani PT'yi oluşturmak için zaten birkaç test yapılmışsa mümkün olabilir. Bu nedenle, hatırlama materyali miktarının artan tutma aralığı ile azalması gerektiğini, ancak yalnızca ilk birkaç denemeden sonra tahmin edebiliriz. Bu tam olarak Keppel ve Underwood'un gözlemlediği şeydi.
Keppel ve Underwood sonuçlarını yorumladılar: sonuçları hafızanın birliği teorisine göre; dualite teorisinin destekçileri değillerdi. Ancak belleği PC ve TP olarak alt bölümlere ayırmanın başka nedenleri olduğunu bildiğimiz için, bunların sonuçlarını girişim hipotezi lehine bir argüman olarak yorumlayabiliriz. SP unutması, proaktif inhibisyona ilişkin verilerden tahmin edilebilecek bir fenomen olarak ortaya çıkıyor.
PROB YÖNTEMİ
Şimdi PC'deki girişimle ilgili farklı türde veriler elde eden başka bir çalışmayı (Waugh ve Norman, 1965) ele alalım. Halihazırda CP'de bulunan materyal üzerindeki müteakip bilgilerin müdahale etkisini inceledi. Gerçekleştirilen deneyler, bir çeldirici kullanmadıkları için yukarıda açıklanan ideal deneye bir yaklaşım değildi; bunun yerine, "saf" zamanın etkilerini ve ara elementlerin sayısını - belirttiğimiz gibi genellikle birlikte değişen etkiler - ayırma girişiminde bulunuldu. Bu ayırma için "prob yöntemi" denen yöntem kullanıldı. Bu yöntem şu şekildedir: deneğe ezberlemesi için bir dizi sayı sunulur (örneğin, 16 sayı). On altıncı rakam zaten diğer on beş arasında gerçekleşti ve bir "sonda" olarak kullanılıyor. Denekten yoklama basamağının ilk geçtiği yeri takip eden basamağı hatırlaması istenir (ikinci kez geçtiğinde, yoklama basamağına bu basamağın satırın sonuncusu olduğunu belirten sesli bir sinyal eşlik eder, böylece öznenin bunu yapmasına gerek kalmaz) sayıları sayın).
Konu okunabilir, örneğin aşağıdaki satır
1 4 79 5 1 2643 8 729 05
(burada yıldız işareti bip sesini gösterir). Deneğe şu soru sorulur: "İlk göründüğünde 5 rakamından sonra gelen sayı hangisidir?" Doğru cevap "bir" dir. Bu deneylerde, doğru yanıtların ortalama yüzdesinin, yani sondanın ilk kez ortaya çıkışından sonra basamağın doğru hatırlanmasının, bu basamağın ilk gösterimi ile yeniden üretilmesi arasındaki basamak sayısına bağımlılığını bulmak önemlidir. (bir ses sinyali ile prob basamağından sonra). Yukarıdaki örnekte, bu tür on ara basamak vardı (sonda basamağı dahil). Bu yöntem, burada müdahale eden birimler olarak alınan ara basamakların sayısına doğrudan bağlı olarak hatırlamayı incelemeyi mümkün kılar.
"Saf" zamanın etkisini araştırmak için, bir değişkenin daha tanıtılması gerekir: rakamların sunum hızı değiştirilebilir (örneğin, saniyede dört basamaktan saniyede bire). Bu, müdahale eden birimlerin zamanını ve sayısını bağımsız olarak değiştirmenize olanak tanır. Başka bir deyişle, artık iki faktörün etkisini ayrı ayrı inceleyebiliriz, araştırma basamağının birinci ve ikinci oluşumu arasındaki süre ve müdahale eden birimlerin sayısı.
Yok olma hipotezinden ve girişim hipotezinden hangi sonuçların bekleneceğine bakarsak, bunun önemi daha açık hale gelecektir. Sönümleme hipotezi doğruysa, hatırlama geçen zamana bağlı olmalı ve ara basamak sayısından bağımsız olmalıdır. Ve bu, farklı bir sunum hızının, belirli sayıda ara öğe için farklı hatırlama verimliliğine yol açacağı anlamına gelir, çünkü sonda basamağının birinci ve ikinci görünümü arasında geçen süre, basamak sunumunun hızına bağlı olacaktır. Bu sürenin doğru cevapların yüzdesi üzerindeki etkisini bir grafik şeklinde sunarak, Şekil 1'de gösterilen eğriyi elde ederiz. 6.5A. Bu, unutmanın, o süre boyunca sunulan ara basamak sayısına bakılmaksızın, zamanın bir fonksiyonu olarak kademeli olarak meydana geldiği varsayımına dayanan varsayımsal bir eğridir (bu nedenle, sonuçlar her iki sunum hızında da aynıdır, ancak herhangi bir veri için daha hızlı bir oran, küçük olandan daha fazla müdahale eden öğeye karşılık gelir). Şek. 6.5, B'de, aynı veriler biraz farklı bir şekilde sunulur: ara elemanların sayısı apsis boyunca çizilir. Böyle bir eğri, tek başına öğe sayısının unutmayı belirlemediği anlamına gelir; böyle bir grafikte unutma, belirli sayıda öğeye karşılık gelen zamana ve sunum hızlarına da bağlıdır.
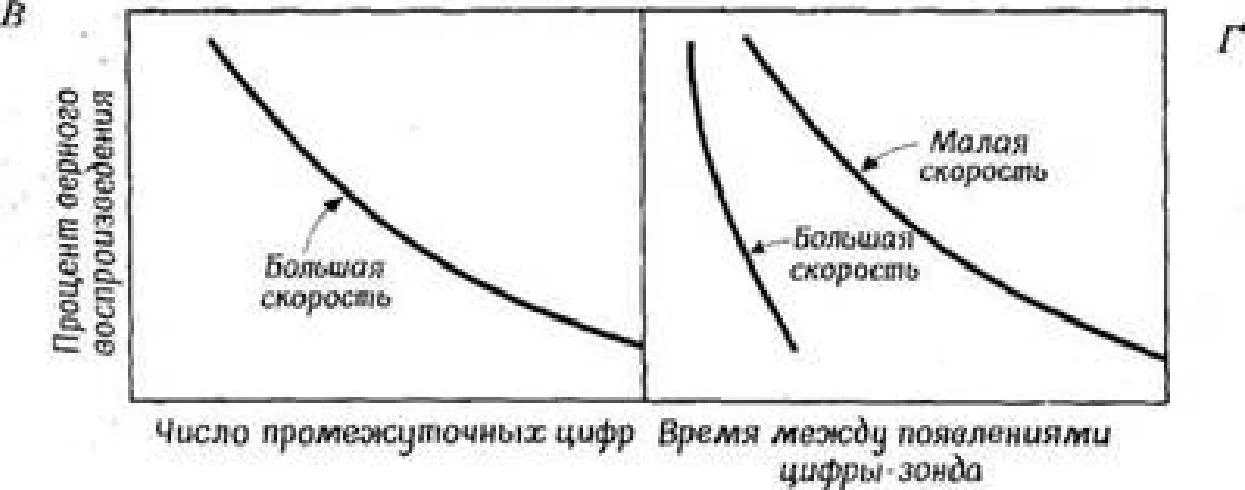
RESİM. -fkiî. Beklenen sonuçlar:! yok olma hipotezine (DnB ) ve girişim hipotezine (C ve D) göre.İlk hipoteze göre, zbenzin her iki sunum hızında da zamanın bir fonksiyonudur ve bu nedenle herhangi bir verili ara basamak için verimlilik daha düşük olacaktır. düşük hız.İkinci hipoteze göre, zabyionne ara basamak sayısına bağlıdır , bu nedenle, belirli bir aralık için, Sudet ses üretiminin verimliliği yüksek sunum hızında daha düşüktür.
Şimdi, unutmayı belirleyen ana faktörün, sondanın birinci ve ikinci görünümü arasındaki aralıkta sunulan basamak sayısı olduğu girişim hipotezinin tahminlerini ele alalım. Bu tahminler ayrıca grafik olarak iki şekilde gösterilebilir (Şekil 6.5, C ve D). Şek. 6.5, B, hatırlamanın ara öğelerin sayısına bağlı olduğu ve sunum hızlarına bağlı olmadığı varsayımına dayanan varsayımsal veriler sunar. Pirinç. 6.5, D, aynı verileri zaman içinde çizersek, iki sunum hızı için iki farklı eğri elde edeceğimizi gösterir, çünkü bu iki hızda, herhangi bir süre için farklı sayıda öğe sunulacaktır (yüksek bir oranda) , düşükten daha fazla).
İki hipotezden hangisinin doğru olduğunu bulmak için, bu tahminleri Şekil 1'de gösterilen deneysel verilerle karşılaştırıyoruz. 6.6 (Waugh ve Norman, 1965). Bu veriler girişim hipotezini desteklemektedir. Her iki sunum hızında da unutma, hatırlanan rakamın ilk geçtiği yeri yeniden üretilmesinden ayıran hane sayısına göre belirlenir. Burada, bu sonucun, serbest hatırlamanın elemanın serideki yerine bağımlılık eğrisinden tahmin edilebileceğini not etmek uygun olacaktır. Sunum hızının, görünüşe göre SP hatırlamayı yansıtan bu eğrinin uç kısmını etkilemediğini biliyoruz (bkz. Şekil 2.2B). Bu durumda, "sonda" deneylerinde olduğu gibi, CP'den hatırlamanın sunum hızına bağlı olmaması, burada zamanın bir rol oynamadığı, ara elemanların sayısının (dizideki yeri) olduğu anlamına gelir. önemli. anlamı.

Pirinç. 6.G. Deneyin sonuçlarına uygunluk. i ipotek j kiteferenmі (Waugh a, Msptplp, ІЯ65) tahmin eden <3inda> yöntemiyle gerçekleştirildi . Ara basamak sayısı arttıkça doğru tahmin sayısı azalır.
DİĞER ÇAYIRICI DENEYLER
Yukarıda sonda basamağıyla açıklanan deneylerin sonuçları, CP'den unutmanın girişimden kaynaklandığı gerçeğinden yanadır. Bu sonuçları Peterson deneylerinde hızlı unutmanın proaktif ketleme ile de ilişkili olduğunu gösteren Keppel ve Underwood'un (Keppel ve Underwood, 1962) verilerine eklersek, girişim hipotezinin oldukça sağlam bir temele sahip olduğu görülür. Bu nedenle, ideal deneyimize başka bir "yaklaşım" ele alacağız - Judith Reitman (Reitman, 1971) tarafından yürütülen deney; bu, şu ana kadar ele aldığımız tüm yaklaşımların en iyisidir. Reitman, dikkat dağıtma görevinin bir geri sayım değil, bir sinyali algılama görevi olduğu bir çeldirici ile bir deney yaptı. Deneklere önce hatırlamaları gereken üç kelime sunuldu. Ardından, beyaz gürültünün arka planında belirli bir tonun görünmesini bekleyerek 15 saniye dinlediler (sinyal algılama); bu sesi duyunca bir düğmeye basmak zorunda kaldılar. Görev oldukça zordu; ses o kadar zayıftı ki, denekler onu yalnızca zamanın yaklaşık yarısı kadar duyabildiler. Bu nedenle, görev, kelimelerin tekrarına müdahale edecek kadar zor kabul edilebilir. Ayrıca, CP'deki üç kelimeye müdahale ediyor gibi görünmüyordu. Bu nedenle, ideal bir deneyde tutma aralığını doldurması gereken "hiçbir şey yapmama" durumuna makul bir yaklaşım olarak düşünülebilir. Denekler ses sinyalini dinledikleri 15 saniyelik bir sürenin ardından, deneyin başında sunulan üç kelimeyi hatırlamaya çalıştılar.
Reitman, deneklerin bu üç kelimeyi hatırlayıp hatırlamadıklarını öğrenmek istedi. Ayrıca deneklerin 15 saniyelik aralıkta bu kelimeleri tekrar etme ihtimalini de dışlamaya çalıştı. Tekrarlamayı ortadan kaldırıp kaldıramadığını belirlemek için, deneklerin ses sinyalini algılama hızlarını ve doğruluğunu, üç kelimeyi hatırlaması gerekmeyen, yalnızca ses sinyalini takip eden kontrol deneklerinin aynı göstergeleriyle karşılaştırdı. Bu testte iki grup arasında fark bulunmadı; bu, deney grubunun gerçekten de sinyali tespit etmekle meşgul olduğunu ve sunulan kelimeleri tekrar etmediğini gösterdi. Bu nedenle Reitman, deneylerinin sonuçlarının, tekrar hariç tutulursa CP'deki bilgilere ne olduğunu yargılamamıza gerçekten izin verdiğini düşündü. Bu sonuçlar, 15 saniyelik süre boyunca hiçbir unutmanın olmadığını açıkça gösterdi: Peterson'ların aksine Reitman, 15 saniyeden sonra kelimelerin neredeyse tamamen akılda kaldığını gözlemledi. Başka bir deyişle, yok oluşun bu dönemde gerçekleştiğine inanmak için hiçbir sebep yoktu.
Deneyin başka bir versiyonunda Reitman, Peterson'ların ilk verilerine daha çok benzeyen biraz farklı sonuçlar elde etti. Bu versiyonda, dikkat dağıtan görev sadece bir ses sinyalini değil, belirli bir heceyi tespit etmekti, bazen bir dizi hece DON olarak telaffuz edilen TON hecesini fark etmeleri gerekiyordu. Böyle bir çeldiriciyle, başlangıçta sunulan kelimeleri yeniden üretme verimliliği keskin bir şekilde düştü - %100'den yaklaşık %75'e. Açıkçası, dikkat dağıtan görevin doğası SP'den unutmayı önemli ölçüde etkiler.
Reitman'ın verileri, sinyal tespitini 1, 8 veya 40 saniye süren bir çeldirici olarak kullanan Shifrin'in (Shiffrin, 1973) deneyleriyle doğrulandı ve tamamlandı. Ek olarak, bazı denemelerde o;n, sinyal algılandıktan sonra çözülmesi gereken bir aritmetik problem sunarak tutma aralığını artırdı. Son seçenek, "tavan etkisini" belirlemeyi amaçlıyordu. Bununla, deneklerin sinyal tespiti ile meşgul oldukları dönemde hafıza izlerinin gücünde sözde "gizli" azalmayı kastediyorlar - güçte, "tavana" kıyasla herhangi bir şekilde üreme verimliliğini azaltmak için yetersiz bir azalma, yani. .100% üreme.
Shifrin'in deneylerinde tipik bir test şu şekilde gerçekleştirildi: denek bir pentagram dinledi - beş ünsüzden oluşan bir grup (örneğin, RLXBT). Daha sonra 1, 8 veya 40 saniye boyunca sinyal algılama görevi gerçekleştirdi. Bazı denemelerde, deneğe daha sonra aritmetik işlemlerle birlikte, yürütülmesi 5 veya 30 saniye süren başka bir görev teklif edildi. Görev, 2 saniyelik aralıklarla arka arkaya sunulan tek basamaklı sayıları başlangıçtaki üç basamaklı sayıya eklemekti (örneğin, 203+4+7+6+9+...).
Reitman gibi Shifrin, süresi ne olursa olsun sinyal algılama süresinin pentagramın geri çağrılması üzerinde hiçbir etkisi olmadığını buldu; her durumda yeniden üretimi neredeyse hatasızdı. Ancak bir aritmetik görevin eklenmesi, 30 saniyelik bir görevin, 5 saniyelik bir görevden daha fazla hatırlamayı kesintiye uğratmasıyla, hatırlamayı bozdu. Bununla birlikte, bu olumsuz etki, sinyal tespit süresinin süresine bağlı değildi: 40 saniyelik bir süreden sonra, en fazla 1 saniyelik bir süre sonra kendini gösterdi. Bu, sinyal saptama süresi boyunca izde herhangi bir solmanın meydana gelmediğini, yani "tavan etkisi" olmadığını gösterir. Ne de olsa, bu süre zarfında pentagram izinin gücü azalırsa (en azından unutmaya yol açacak kadar değil), o zaman aritmetik görevin ek etkisi "meseleyi sona erdirir." Pentagramın sunumu ile çoğaltılması arasındaki zaman aralığı maksimum olacağından ve bu nedenle yok olma en büyük olacağından, özellikle bu, uzun bir sinyal algılama döneminden sonra beklenebilir. Bir aritmetik problemi eklemek, gözle görülür bir unutmaya yol açar. Bu nedenle, iz sönümlemesi durumunda, bir aritmetik görevin getirilmesi, 1 saniyelik bir süreye sahip varyanta göre 40 saniyelik bir sinyal algılama periyoduna sahip varyantta ünsüzleri hatırlama verimliliğini daha fazla azaltacaktır. Böyle bir farkın olmaması, sinyal algılama görevlerini gerçekleştirmenin bellekteki izlerin gücü üzerinde herhangi bir etkisinin olmadığını düşündürür.
Bu deneyler sonucunda, CP'de saklanan bilgilerin unutulmasını izlerin yok olmasıyla açıklayacak hiçbir neden olmadığı izlenimi yaratıldı; tamamen müdahaleden kaynaklandığı düşünülebilir. Ancak Reitman, "tavan etkisini" ve tekrarı kontrol etmek için yeni koşullar getirerek orijinal deneyini tekrarladığında işler değişti. "Tavan etkisi" ile ilgili olarak, Shifrin ile aynı koşullardan endişe duyuyordu: artık mümkün olmayacak kadar olmasa da, tutma süresi boyunca deneklerin bilgilerin bir kısmını unutma olasılığını dışlamak istedi. sunulan üç kelimeyi de hatırlamak için. Ayrıca, deneklerin akılda tutma süresi boyunca sunulan materyali tekrar edip etmediğini bulmaya çalıştığı ilk deneylerin belki de yeterince titiz olmadığını düşündü. Sonuçta, denekler bunu fark edilmeden tekrarladıysa, unutmanın gerçekleşmemesinin nedeni bu olabilir.
Bunun ışığında Reitman, "tavan etkisini" ortadan kaldıracak ve tekrar olasılığını doğru bir şekilde belirleyecek şekilde tasarlanmış deneyler yaptı. "Tavan etkisini" ortadan kaldırmak için konuyu orijinal versiyondaki gibi üç kelimeyle değil, beş kelimeyle sundu. Ve tekrarlama olasılığını hesaba katmak için, kelime hatırlama ve sinyal algılamanın etkinliğine ilişkin yedi farklı derecelendirmeye sahip karmaşık bir analiz sistemi geliştirildi; bu analiz, deneğin kelimeleri tekrar edip etmediğini, çeşitli tekrarlama yöntemlerinden hangisini seçtiğini ve bu tekrarın ne kadar aktif olduğunu yargılamayı mümkün kıldı. Bu değerlendirmeler aşağıdaki koşullar altında yapılmıştır: 1) özneden materyali sessizce tekrar etmesi istendiğinde; 2) materyali tekrarlamamanız istendiğinde; 3) kendisine tekrar için herhangi bir unsur sunulmadığında; 4) orijinal deneyin tam reprodüksiyonu ile.
Reitman'ın sonuçları korkularını doğruladı: İlk verilerinin bir tavan etkisinden etkilendiği ortaya çıktı. Ayrıca orijinal deneyde deneklerin materyali sessizce tekrarladıklarını ve bunu test etmek için kullandığı yöntemlerin yeterince etkili olmadığını da buldu. Dahası, yeni deneylerinde, 52 denekten yalnızca onu, bunu yapmaları istendiğinde tekrardan kaçınabilmiş gibi göründü. Bu 10 denekten, belirleyici bir deney yapmak için bir grup oluşturuldu: solma mı yoksa girişim mi? Bip sesini algılamakla ve tekrardan kaçınmakla meşgul oldukları 15 saniyelik bekleme aralığında kendilerine sunulan bilgileri gerçekten unuttular mı? Yanıtın olumlu olduğu ortaya çıktı: Bu 15 saniye boyunca, başlangıçta alınan bilgilerin ortalama olarak yaklaşık %25'i kayboldu. Bu, tutma süresi boyunca izlerin kaybolduğunu gösterdi. Başka bir gerçeği not etmek de önemlidir: ara görev belirli bir heceyi (DON ve TON hece serisindeki TON hecesi) tespit etmek olduğunda, Unutma derecesi, bir ses tespit edildiğinden% 44 daha yüksekti. Bundan Reitman, "tavan etkisinin" (deneylerinde, ancak muhtemelen daha etkili önlemler alan Shifrin'in deneylerinde değil) ve algılanamayan tekrarın (hem orijinal deneylerinde hem de Shifrin'in deneylerinde) sonuçları çarpıttığı ve sonuçları tersine çevirdiği sonucuna vardı. yok olma hipotezi ve aslında KP'den unutmanın en azından kısmen izlerin yok olmasından kaynaklandığını.
Bununla birlikte, Reitman, deneyinde, engellemenin bir sonucu olarak unutmayı gösteren verilerin elde edildiğini, bu durumda belirli bir heceyi bulma göreviyle ilişkili girişimin elde edildiğini de kaydetti; bu koşullar altında unutmanın, basit bir ses sinyalinin (ton) algılandığı duruma göre daha önemli olduğunu buldu. Shifrin ayrıca, bir ses sinyalini algılama görevinin böyle bir etkisinin olmadığı durumlarda aritmetik probleminin unutmaya neden olduğunu da bulmuştur. Çeldirici görevler, hatırlanacak öğelere müdahale etmeyerek tekrarı önlemeyi amaçlasa da, bu görevlerden bazılarının girişim yarattığı görüldü. Ve unutmanın en yüksek yüzdesinin gözlendiği bu tür müdahaleci görevlerde oldu.
Bir dizi deney, dikkat dağıtıcı görevlerin gerçekten de girişim yaratabileceğini göstermiştir. Bu, bilinen sözel beceriler (kelime veya hece becerileri) gerektiren görevlerin sözel materyalin (heceler veya sözcükler) akılda tutulmasına işaret saptama gibi sözel olmayan görevlere göre daha fazla müdahale ettiği Reitman ve Shifrin'in deneylerini içerir. Watkins ve iş arkadaşları (Watkins a.o., 1973), sözlü olmayan zor görevlerin de SP'yi unutmaya yol açabileceğini göstermiştir. Deneklere ezberlemeleri için beş kelimelik bir dizi sundular. Çeldirici, deneğin piyanoda üretilen bir dizi sesi dinlediği ve her ses çıktıktan sonra belirli bir düğmeye basarak bunları takip ettiği bir görevdi. Bu, Petersons'ın deneylerindeki kadar önemli olmasa da, 20 saniyelik akılda tutma aralığında (Şekil 6.7) sunulan beş kelimenin kısmen unutulmasına neden oldu.

Pirinç. 6.7. Dil öncesi sözcüklerin sürüm sayısının "akılda tutma sorunu"nun süresine bağlılığı üç önemli* koşul altında (Watfcirts a. o. 1973). / - gömme aralığı sırasında sessizlik oldu; t! — іshteriya.іа tutma sırasında, denek bir dizi ses (ton) dinledi; UI— ancak tutma aralığında, denek iii'ün her birine aynı şekilde tepki vererek ton dizisini takip etti.
Watkins ve işbirlikçileri, dikkat dağıtıcı görev nedeniyle CP'den unutma derecesinin bu görevin iki özelliğine bağlı olduğunu öne sürdüler. Biri hatırlanacak malzemeye benzerlik derecesidir. Parazitin bu benzerlikten kaynaklandığı varsayılmaktadır: benzerlik ne kadar büyükse, CP'deki izlerin zayıflamasına yol açan girişim o kadar güçlüdür ve bu durumda bilgi, tutma aralığından sonra artık geri yüklenemez. Burada tarif ettiğimiz deneyler (Peterson a. Peterson; Reitman; Shiffrin, Watkins a.o.) ve henüz dikkate alınmayan diğer veriler bunu doğrulamaktadır. Wickelgren (1965), çeldirici görevi gören malzeme ile hatırlanan malzemenin ses açısından benzer olması durumunda, unutma derecesinin, farklı olma durumlarına göre daha yüksek olduğunu bulmuştur. Deutsch (Deutsch, 1970), başka bir ton serisini dinlerken belirli bir ton setini tutmanın, bir dizi sayıyı dinlemekten daha zor olduğunu bulmuştur. Tüm bunlar, çeldiricilerin CP'de bulunan ezberlenecek malzeme ile temasa geçip müdahale edebileceğini düşünmemizi sağlar. Bu görüş, CP'nin bir tür "işin" yapıldığı yer olduğu fikriyle tutarlı görünüyor (örneğin, bir dikkat dağıtıcı görevi yerine getirirken). Bu malzemenin saklanması PC'de de gerçekleştiğinden, iki malzeme setinin temas etmesi ve bu temasın, derecesi bir malzeme ile diğer malzeme arasındaki benzerliğe göre belirlenen girişimle sonuçlanması muhtemeldir.
Watkins ve arkadaşlarına göre SP'den unutmanın bağlı olduğu bir diğer faktör, çeldiriciyi ayarlamanın genel zorluğudur. Bu yazarlar, bilgi işleme sisteminin kapasitesinin (veya bilinen bir kapasite anlamında dikkatin) bir çeldirici görevin yerine getirilmesinde kullanıldığı ölçüde, bu görevin girişim yaratacağına inanmaktadır. Bu tür görevlere örnek olarak şunlar verilebilir: 1) bir dizi tonu izlemek; 2) geri sayım; 3) ek görevler. Bu fikir, çeldirici görevin zorluk derecesinin SP'deki materyalin akılda tutulmasını etkilediğini gösteren diğer deneylerin sonuçları tarafından desteklenmektedir (bkz. örneğin, Posner ve Konick, 1966; Posner ve Rossman, 1965). Reitman'ın verilerine dayanarak, bu tür görevlerde müdahale mekanizmalarından birinin tekrara müdahale etmeleri ve böylece izlerin yok olması için koşullar yaratmaları olduğu varsayılabilir. Ayrıca bunun, yalnızca bilgi depolamak için değil, aynı zamanda bilgi işlemek için de bir yer olarak CP kavramıyla tutarlı olduğunu not edebiliriz. Daha zor görevlerin bir çalışma alanı gerektirmesi beklenebilir; bu, bilgilerin tekrarı gibi işlerin yanı sıra saklanması için alanın azalmasına ve dolayısıyla daha fazla unutmaya yol açacaktır. Bu görüş, Murdock'un (Murdock, 1961) hatırlamanın depolanacak bilgi miktarından etkilendiğine dair verileriyle de tutarlıdır. Geri sayım görevinin bir dikkat dağıtıcı görevi gördüğü bir deneyde Murdoch, bir ünsüz harf veya üç kelimeden oluşan bir trigramın hatırlanması gerektiğinde unutmanın daha hızlı ve tek bir kelime olduğunda daha yavaş olduğunu gözlemledi. İlk durumda, malzeme üç yapısal birim içeriyordu (ve daha fazla depolama alanı gerektiriyordu), ikinci durumda ise yalnızca bir yapısal birim içeriyordu.
BİLİŞSEL SÜREÇLERİN UNUTMA ÜZERİNDEKİ ETKİSİ
Akılda tutma aralığında yapılan işin niteliği, saklanan bilgi miktarı ve ara görevin zorluk derecesi gibi faktörler CP'deki materyalin akılda tutulmasını etkiliyorsa, bu bizi tanıdık bir noktaya geri getiriyor. Bu fikir, girdi bilgilerinin seçici işlenmesini ve örüntü tanımanın yanı sıra yapılandırma ve tekrarlama gibi süreçleri düzenleyen faktörlere benzer şekilde, CP unutmasında yer alan bilişsel bir bileşen olduğudur. Bu fikir, bir "rakam sondası" ile bir dizi ek deney yürüten Wee ve Norman'ın (Waugli ve Norman, 1968) çalışmalarının sonuçlarıyla pekiştirildi. Bu yazarlar, CP unutmanın yalnızca belirli bir öğenin sunumu ile onun kontrol yeniden üretimi arasındaki öğelerin sayısından değil, aynı zamanda bu öğelerin içeriğinden de etkilendiğini bulmuşlardır. Waugh ve Norman'ın verileri, meselenin ara elementlerin toplam sayısında değil, ezberlenecek malzemeye müdahale eden elementlerin sayısında olduğunu gösteriyor. Bazı unsurlar, özellikle bu deney bağlamında tahmin edilebilecek olanlar karışmaz.
Bunu görmek için, 555, 666, 333 gibi üç özdeş rakamdan oluşan bir sayı dizisi sunulduğunda ne olacağına bir bakalım. Bir rakamın her tekrarı girişim yapan bir öğe olarak kabul edilebilir mi? Tamamen sezgisel nedenlerden dolayı, bu pek olası görünmüyor: Sonuçta, her tekrarı ayrı ayrı hatırlamak yerine, a'nın her basamağının üç kez tekrarlandığı kuralını hatırlamamız gerekiyor. Gerçekte olan da tam olarak budur; Waugh ve Norman, tahmin edilebilir unsurların, beklenmedik unsurların yaptığı gibi müdahale etmediğini keşfetti. Ve bir kez daha, bilgi işleme sisteminin pasif olmadığı, bilişsel süreçlerle ilişkili bir tür düzenleyici mekanizma içerdiği sonucuna varmalıyız.
Bu, KP'den unutma süreçleri hakkındaki değerlendirmemizi sonlandırıyor. Mevcut tüm verileri açıklamak için, hem pasif iz yok olmasına hem de girişime yer olan bir teoriye ihtiyacımız olduğu sonucuna varabiliriz: yok olma, tekrarlama olmadığında meydana gelir; müdahale, yeni bilgiler sunarak veya orijinal olarak sunulan bilgileri korumanın gerekli olduğu bir zamanda bazı görevleri (işleri) gerçekleştirerek oluşturulabilir. Belirli bir görev tarafından yaratılan girişimin derecesi, görevin CP'de depolanan malzemeye olan yakınlığına ve ayrıca onu tamamlamak için kullanılması gereken CP'nin kapasitesine bağlı olarak değişiyor gibi görünüyor. Belirli bir görevde ne kadar çok müdahale olursa, rakip malzemenin unutulmasına o kadar çok neden olur. Son olarak, unutmanın doğasının düzenleyici süreçler tarafından belirlendiğini not etmek çok önemlidir. Bellekte ne tür bilgilerin depolandığı, üzerinde ne tür çalışmaların yapıldığı ve tekrar olup olmadığı bu süreçlere bağlıdır; bu nedenle, CP'de hangi bilgilerin tutulacağını belirlemede de önemli bir rol oynarlar.
Bölüm 7 _
Kısa süreli bellek: bilgiyi akustik olmayan biçimde depolamak
Ch'de. 2, insan bilgi işleme sisteminin genel modelini ele aldık. Zorunlu olarak, bu modelin tanımı basitleştirilmiştir; basitleştirmelerden biri, bilginin CP'de akustik (işitsel) biçimde ve DP'de anlamsal biçimde kodlandığı iddiasıydı. Bölümün sonunda, SP tanımımızda bazı karmaşık noktaların çıkarıldığını fark ettik. Bu bölümde, bu komplikasyonlardan bazılarının neler olduğunu göreceğiz ve SP ve ilgili süreçler hakkındaki tartışmamızı bitireceğiz.
Kısa süreli belleğin ilk basitleştirilmiş tanımıyla ilgili en önemli sorunlardan biri, CP'nin akustik olarak kodlanmış öğelerin bir deposu olarak tasvir edilmiş olmasıdır. Tabii ki, bu alandaki orijinal araştırmaların çoğu (örneğin, Conrad tarafından not edilen "işitsel" hatalar, 1964), bilginin CP'de akustik bir biçimde depolandığını gösterdi. Bununla birlikte, CP'deki öğelerin görsel ve anlamsal kodlaması lehine kanıtlar da vardır. Örneğin, CP ile ilgili ilk tanımımızda, bir harfin görsel olarak sunulduğunda, akustik olarak işaretlendiği ve CP'de saklanmak üzere kodlandığı (böylece, C harfinin "ES" sesine dönüştüğü) varsayılmış olsa da, bazı kanıtlar görsel olarak sunulan bir harfin CP'de aynı görsel formda kodlanabileceğini önerir (yani, C, bir "C" şekli olarak saklanır). Bu bölümde, bu tür akustik olmayan bilgi depolama lehine mevcut verilere odaklanacağız.
CP'nin akustik olmayan kodlarını incelemeye başlamadan önce, CP'deki bilgilerin görsel veya anlamsal temsilinden söz edildiğinde ne kastedildiği açıklığa kavuşturulmalıdır. CP'yi keyfi bir şekilde belirli öğelerin sözlü tanımlarının (yani heceler veya kelimeler) akustik biçimde depolandığı yer olarak tanımladık ; ancak bu tanım, CP'de görsel veya anlamsal kodlama olasılığını dışlar. Bu nedenle, CP'de depolanan bilgilerin doğasını incelemek için, şu veya bu türdeki koddan bağımsız olarak CP'yi tanımlamamız gerekir.
Böyle bir belirleme için, bilgi depolama süresinin bir işareti kullanılabilir. Kısa süreli belleğin, öğelerin kısa bir süre için tutulduğu bir depo olduğunu öne sürebiliriz - tekrar olmadığı sürece birkaç saniye mertebesinde. CP'nin duyu organlarından (veya duyusal kayıtlardan) veya uzun süreli bellekten gelen bilgileri depolayabildiğini de söyleyebiliriz. CP'nin bu tanımıyla, içinde depolanan bilgiler herhangi bir biçimde düşünülebilir. Ancak bu durumda duyusal kayıtlar ile CP arasındaki sınırın çizilmesi özellikle önemli olacaktır çünkü bilgiler duyusal kayıtlarda da kısa bir süre saklanmaktadır. Bu nedenle, bir özelliğin daha tanıtılması gerekiyor. Duyusal kayıtlardan CP'ye giren öğelerin, ham duyusal bilgi biçiminde içerilmediklerini , ancak örüntü tanımanın çok önemli aşamasından geçtiklerini ve bu sırada karşılık gelen temsille temasa geçtiklerini söyleyebiliriz. DP. Bu unsurlar kategori öncesi olmaktan çıktı. Bu nedenle, bilgilerin duyusal olmayan bir biçimde - akustik olmayan (yani görsel veya anlamsal) bir kod biçiminde kısa süreli saklanma olasılığını gösteren verileri dikkate almak istiyoruz.
KISA SÜRELİ HAFIZADAKİ GÖRSEL KODLAR
Akustik olmayan duyusal olmayan kısa süreli bellek kodlarından önce görsel kodları ele alacağız. Özellikle, görsel bilginin uyaran kaybolduktan sonra bir süre daha devam edebileceğine dair kanıtları tartışacağız, ancak bu bilgi artık duyusal kayıtta görünmüyor. Ayrıca, görsel biçimde kodlanmış, içinde depolanan bilgilerin kısa bir süre için DP'den çıkarılma olasılığı hakkındaki verileri de tartışacağız. Bu nedenle, CP'nin önceki analizinin odak noktası olan akustik depolama ile aynı özelliklere sahip olan görsel bir biçimde bilgi depolama olasılığını destekleyen araştırma kanıtlarını dikkate almamız gerekecek.
POZNER'İN MEKTUPLARIN KARŞILAŞTIRILMASI DENEYLERİ
PC'de görsel kodlamanın varlığını öne süren bir dizi veri, Posner tarafından geliştirilen bir yöntemden gelmektedir (Posner, 1969; Posner a. o "1969; Posner a. Mitchell, 1967). Posner'ın araştırması şu konularda güçlü kanıtlar sunar: 1) maruz kaldıktan sonra görsel bir uyarana görsel bilgi, ikonik depolama ile bağdaşmayan koşullarda saklanabilir ki bu çok kısa sürer.Her denemede deneğe iki harf sunulur.Bu harflerin aynı isme sahip olup olmadığını (örneğin , A ve A veya Önlük) veya farklı (örneğin, A ve B); özne bunu önündeki düğmelerden birine tıklayarak yapar.
■<—— . —Bpeifya reaksiyonları ve — >
Ryas, 7.1. Posner'ın sahte yemek örnekleri p zhperkmivtak Pozner harflerine göre.
Bu görevin - daha önce ele alınanların çoğunun aksine, konunun hatasız tamamlanabileceği oldukça açıktır. Bu nedenle, bu durumda deneyi yapan kişi, sadece doğru ve yanlış cevapların yüzdesi gibi verilerle tatmin olamaz. Buradaki bağımlı değişken, konunun tepki süresi (RT) olacaktır - harfleri sunduktan sonra "aynı" veya "farklı" bir cevap vermesi için geçen süre. Daha doğrusu RT, harflerin ortaya çıkışı ile öznenin tepkisi arasındaki süredir.
Teorik olarak bu değer, karşılık gelen dahili işlemler için ne kadar süre gerektiğini gösterir. Posner'ın sanal gerçeklikteki görevi, deneğin kayınları görsel olarak algılaması, birbirleriyle karşılaştırması, aynı mı yoksa farklı mı olduğuna karar vermesi ve istenilen butona basması için gereken süreyi içeriyor. VR, öznenin bu eylemleri gerçekleştirmesinin ne kadar sürdüğüne bağlı olarak aşağı yukarı olacaktır. Bununla birlikte, deneysel psikolojide VR kullanımı bu tür görevlerle sınırlı değildir. Bu göstergenin uzun bir geçmişi vardır. Posner bunu, zihinsel süreçlerin incelenmesinde Sanal Gerçekliği kullanmak için bir "çıkarma yöntemi" öneren Donders'in (Bonders, 1862) çalışmasından ödünç aldı. Bu yöntem çok basittir. X ve Y olmak üzere iki görevimiz olduğunu ve bu Y görevinin, X görevinin tamamını artı bazı Q bileşenlerini (yani Y=X+Q) içerdiğini varsayalım. Ardından, X ve Y görevleri için RT'yi ölçerek, X için RT'yi Y için RT'den çıkarabilir ve Q bileşenini tamamlamak için gereken süreyi elde edebilir. bileşen doğrudan izolasyonda gözlemlenemez. Daha genel bir biçimde: Tepki süresini kullanarak, görevlerin bireysel bileşenlerini ayırabilir ve zihinsel süreçlerin bazı özelliklerini keşfedebilirsiniz.
Posner'ın deneylerine geri dönelim. Olarak Şekil l'de görülebilir. 7.1, öznenin "aynı" yanıtını vereceği iki durum vardır. Sunulan iki harf aynıysa (örneğin, A ve A) böyle bir cevap verecektir; buna "tam eşleşme" diyeceğiz. Ve harfler aynı değilse, ancak aynı ada sahipse (A ve a gibi) yine "aynı" cevabını verecektir; bir "isim tesadüfü" olacaktır. Diğer durumlarda, konu "farklı" olarak cevap verecektir. ("Aynı" ve "farklı" yanıtları da sırasıyla olumlu ve olumsuz olarak adlandırılır.) Kural olarak, bu üç durum için - tam bir eşleşme ile, aynı adlarla ve farklı harflerle - VR'nin değerleri farklı. Tam bir eşleşme durumunda, denek genellikle isimlerin çakışması veya olumsuz bir cevap durumunda olduğundan 0,1 s daha hızlı yanıt verir (VR ile yapılan deneylerde bu çok büyük bir değerdir). Bu, bu tür görevlerin yürütülmesiyle ilişkili dahili süreçlerde bazı farklılıklar olduğunu göstermektedir.
Bu farklılıkların ne olduğunu bulmak için, yaptığınız görevi, her biri harcanan toplam sürenin bir kısmını kaplayan ayrı bileşenlere ayırmalısınız. Bu şekilde, tam bir eşleşme durumu dışındaki durumlarda o bileşeni veya fazladan zaman alan bileşenleri izole etmeye çalışıyoruz. Muhtemelen görevi şu şekilde ayırabiliriz: ilk olarak, özne harfleri algılar (görsel olarak kodlar); o zaman onlara isim vermeli; daha sonra isimlerin aynı mı yoksa farklı mı olduğuna karar verir ve son olarak butona basarak cevabı verir. Bu işlemler, mektupların sunumunun başlangıcından cevaba kadar her zaman alır. Harflerin algılanması için gereken sürenin farklı durumlarda değiştiğini varsaymak için yeterli neden yoktur; aynı şekilde, bir düğmeye basmak için geçen süre de neredeyse hiç değişmiyor. Büyük olasılıkla, RT'deki farklılıklar adlandırma ve karşılaştırma işlemleri için gereken süreye bağlıdır. Harfler aynı olduğunda, bu işlemlerin tamamlanması, harflerin farklı olduğu duruma göre daha kısa sürer.
Posner'a göre, VR'deki farklılıklar, iki özdeş harf olması durumunda, onları adlandırmaya gerek olmamasından kaynaklanmaktadır. Fiziksel formlarının görsel olarak algılanmasıyla kimliklerinin hemen fark edildiğine inanıyor. Ancak harfler aynı olmadığında onlara isim vermek ve bu isimleri eşleştirmek gerekli hale gelir. Kısacası tam tesadüf durumlarında (A, A) görev algı ve görsel kodlamaya, fiziksel görüntülerin karşılaştırılmasına ve cevap verilmesine indirgeniyor; isimlerin çakışması (A, a) veya olumsuz cevap (A, B) durumunda, algı ve görsel kodlama, sözlü kodlama (adlandırma), isimlerin karşılaştırılması ve cevap verilmesini içerir. İsimler eşleşirse yanıt - içerdiği daha fazla sayıda bileşen nedeniyle - daha uzun sürer ve bu da VR'de gözlenen farklılıklara yol açar. Kısacası, Posner'a göre tam çakışma durumlarında karşılaştırma görsel bilgilere, adların çakışma durumlarında ise sözlü kodlara dayanmaktadır (Şekil 7.2).
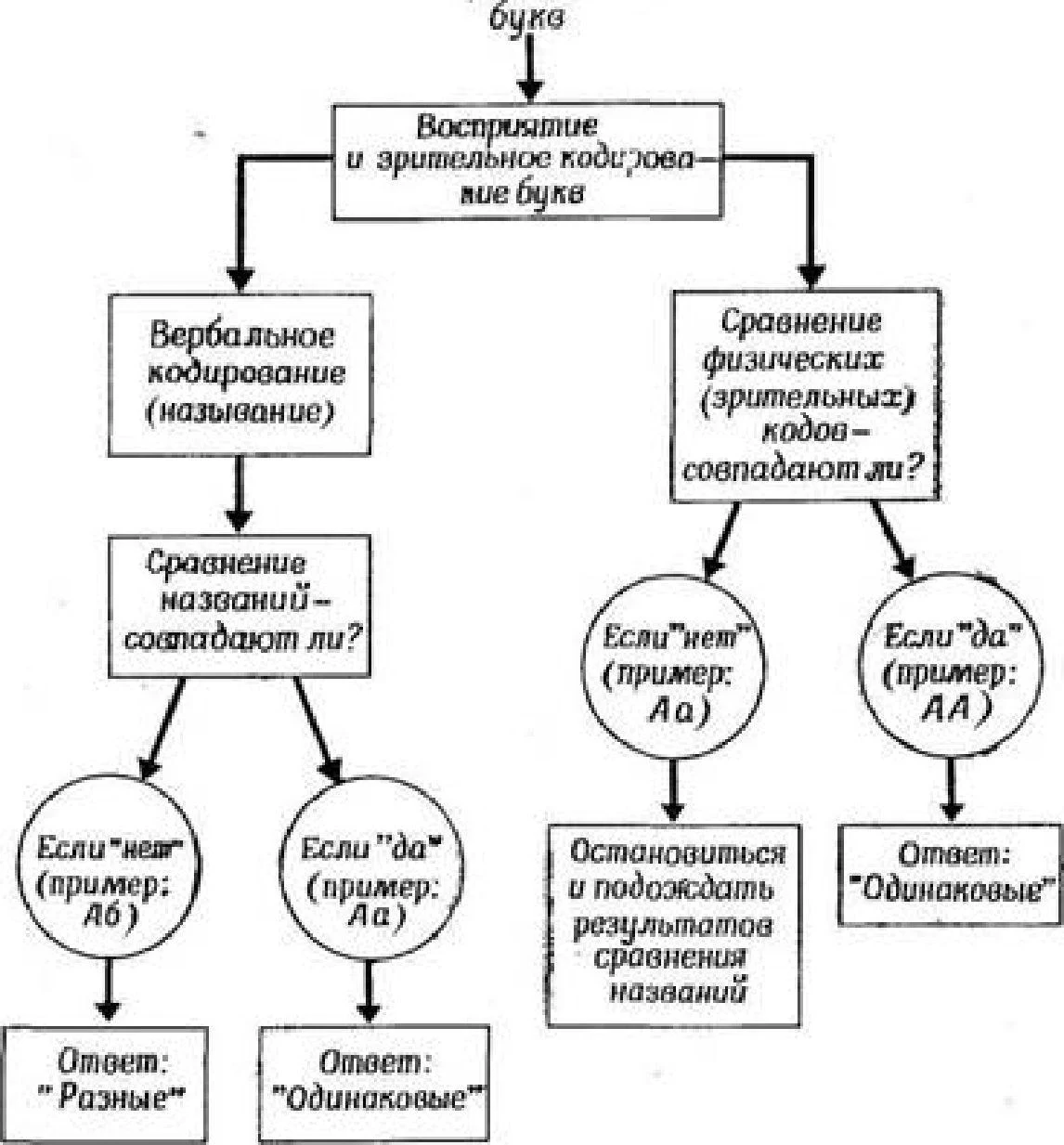
Tam bir eşleşme durumunda görsel bilgilerin karşılaştırıldığını düşünürsek, bu bilgilerin varlığını ima etmiş oluyoruz. İkincisi, iki harfin aynı anda sunulması ve konu bir cevap verene kadar görünür kalması şüphe götürmez - düşündüğümüz durum budur. Bununla birlikte, uyaran kaybolduktan sonra görsel bilginin bellekte kaldığına dair kanıtlara ihtiyacımız var. Ayrıca, bu bilginin ikonik görüntüde değil, dışında, yani CP'de bulunduğunu göstermek istiyoruz.
Bellekte bu tür görsel bilgilerin varlığını göstermek için, Posner görevi aynı anda değil, sırayla iki harf sunarak değiştirilebilir. Tipik bir deneme aşağıdakilerden oluşur: önce ilk harf yaklaşık yarım saniye görünür, ardından deneğin boş bir alan gördüğü bir uyaranlar arası aralık gelir ve ardından ikinci harf görünür. Konu, önceki versiyonda olduğu gibi, kendisine sunulan iki mektubun "aynı" mı yoksa "farklı" mı olduğunu belirtmelidir. Tepki süresi, bu durumda, ikinci harfin ortaya çıkması ile öznenin tepkisi arasındaki aralık olarak tanımlanır.
Bu görevde, uyaranlar arası aradan önce ekrandan kaybolduğu için, yanıtını verdiğinde ilk harf deneğin belleğinde kalmalıdır. İki harfi eşleştirmek için hafızadaki bilgiler kullanılmalıdır. Burada kullanılanın görsel bilgi olduğuna dair kanıt var mı? Diğer bir deyişle, deneyin bu varyantında, isimlerin tam olarak çakışması durumunda, isimlerin çakışması ile karşılaştırıldığında, isimlerin çakışması için gözlenen BP büzülmesi midir? Bu, en azından bazı koşullar için olumlu olarak yanıtlanmalıdır. Eğer uyaranlar arası aralık 1 s'den azsa, o zaman üç tam tesadüfün karşılaştırılması daha az zaman alır.
Zaman, ancak 2 s'ye yaklaşırsa, VR'deki farklılıklar ortadan kalkar (Şekil 7.3). Daha önce olduğu gibi tartışarak, tam bir eşleşme için VR'nin bir isim eşleşmesinden daha az olması durumunda, harflerin tam kimliğini oluşturmak için görsel bilgilerin kullanıldığı sonucuna varabiliriz. Ancak eşleştirme anında ilk harf fiziksel olarak bulunmadığından, karşılık gelen görsel bilginin beyinde olması gerekir. Böylece, ilk harfe ilişkin görsel bilginin, bu harfin kaybolmasından sonra yaklaşık 2 saniye boyunca saklandığına dair kanıtımız var. Uyaranlar arası süre uzadıkça tepki süresindeki farkın giderek kaybolması, bellekteki ilk harfin görsel izinin giderek kaybolmasıyla açıklanabilir.

Pirinç. 7.3. Karşılaştırma sırasında uyaranlar arası aralığın ve reaksiyon süresinin etkisi
Böylece, görsel bilginin uyaranın ortadan kaybolmasından sonra bir süre daha bellekte tutulabileceğine dair kanıtımız var. Bununla birlikte, önemli bir soru kalır: görsel bilginin ikonik bellekte değil de PC'de olduğunu nasıl bilebiliriz? Ne de olsa, burada açıklanan deneyler, iki özdeş harfi karşılaştırırken ikonik bilgilerin kullanılmadığını iddia etmemize izin vermiyor. Bununla birlikte, ilgili izlerin duyusal kayıtta olmadığına ve bunun yerine (bölümün başında oluşturduğumuz kriterlere göre) "kısa süreli" bellek olarak sınıflandırılması gerektiğine dair kanıtlar vardır.
Bu görsel izlerin duyusal olmayan doğası lehine olan argümanlardan biri, ikonik görüntünün ortadan kaybolmasından sonra bile devam ediyor gibi görünmeleridir (Posner a. o., 1969). Örneğin, iki harf ( () arasındaki aralıkta bir tür maskeleme alanının sunulduğunu varsayalım - örneğin, rastgele bir siyah beyaz desen. Bu desenin ilk harfin ikonik görüntüsünü silmesi beklenebilir. Bir deneyde, tam bir eşleşme, deneklere ad eşleştirmeden daha hızlı ortaya çıkar (her iki durumda da "boş" bir uyaranlar arası aralıktan daha fazla zaman harcanmasına rağmen). maskeleme alanının sunumu, bu da onun duyusal kayıtta değil, başka bir yerde depolandığı anlamına gelir.
Tartıştığımız görsel belleğin duyusal olmadığının bir başka göstergesi, karşılık gelen görüntüyü LTP'den "ödünç alma" olasılığına ilişkin verilerdir. Bu deneylerden birinin sonuçlarını açıklayalım (Posner a.o., 1969). İlk harfi görsel olarak sunmak yerine özneye "Bu büyük bir A." Bunu "boş" bir aralık izler ve ardından büyük bir A veya başka bir harf sunulur. Bu tür koşullar altında, olumlu tepkiler için tepki süresi (ikinci harf duyurulan harfe karşılık geldiğinde), uyaranlar arası bir aralık ile tam tesadüf durumlarında (normal koşullar altında, yani her iki harfin görsel sunumu ile) RT ile karşılaştırılabilir. 1 s veya daha fazla sıra. 1 s'den daha kısa bir aralıkta, denekler tarafından tam bir eşleşme biraz daha hızlı algılanır. Bu sonuçlar, deneğin beyan edilen mektubun içsel bir görsel görüntüsünü oluşturmak için sözlü sunumu kullandığını göstermektedir (harflerin sesi ve görünümü arasındaki yazışmayı açıklayan kuralları kullanarak). İkinci harfin ortaya çıkmasından sonra yarattığı bu içsel imajı onunla karşılaştırır. Konunun bu dahili görüntüyü oluşturmak için en az bir saniyesi varsa, bu görüntü, ilk harf görsel olarak sunulmuş olsaydı ne olacağıyla karşılaştırılabilir. Süre çok kısaysa (1 saniyeden az), görsel olarak sunulan bir harfin izinden "daha kötü kalitede" bir görüntü elde edilir. Gördüğümüz gibi, özne muhtemelen DP'de yer alan kurallara uygun olarak görsel bir temsil oluşturabilir veya benzer bir görüntüyü uyarıcının gerçek sunumundan sonra hafızasında tutabilir. Bu, uyaranın ortadan kaybolmasından sonra devam eden görsel görüntünün ikonik bir iz olmadığı gerçeği lehine güçlü bir argümandır, çünkü bu tür bir görüntü sadece duyular yoluyla doğrudan alınmakla kalmayıp DP'den de çıkarılabilir.
'ZİHİNSEL DÖNÜŞLER' İLE DENEYLER
Öznenin DP'den gelen bilgileri kullanarak oluşturduğu temsil, zihninde alfabenin harflerini görsel olarak ayırmaya çalışırken ortaya çıkabilecek olana benzer. Bu tür temsiller hakkında ek bilgiler Roger Shepard, Lynn Cooper ve işbirlikçilerinin çalışmalarından elde edildi (Cooper a. Shepard, 1973; Shepard a. Metzier, 1971). Bu yazarlar, düşündüğümüze benzer şekilde, sözde zihinsel dönüşler - görsel imgelerin dönüşleri üzerine çalıştılar. Deneklere Pozner'ınkine benzer görevler verdiler. Bir deneyde, deneklere bir harf sunulduğunda bir düğmeye ve o harfin ayna görüntüsü sunulduğunda başka bir düğmeye basması gerekiyordu. Özellikle ilgi çekici olan, uyaranın kendi düzleminde döndürülebilmesidir. Bu nedenle, örneğin, L'nin "normal" bir harf (doğru döndürülürse olacağı) ve - onun ayna görüntüsü olarak tanımlanması gerekiyordu. Normal konuma göre dönüş açısı 0 ile 360° arasında değişmiştir. Shepard ve ekibi, doğru bir cevap için gereken VR'nin doğrudan mektubun dönüş derecesine bağlı olduğunu buldu (Şekil 7.4). 0'dan 180°'ye dönerken BP arttı; 180°'den 360°'ye (ters yönde 180°'den 0°'ye dönüşlere karşılık gelir) daha fazla döndürme ile kademeli olarak azaldı. VR'deki değişikliğin doğası, öznenin mektubu zihinsel olarak döndürerek normal konumuna getirdiğini (hangi yolun daha kısa olduğuna bağlı olarak saat yönünde veya saat yönünün tersine, örneğin * ) ve ardından ortaya çıkan görsel görüntüye göre karar verdiğini gösteriyor .
normal bir mektup veya bir "ayna" harfidir. Uyarıcının döndürülmesi gereken her bir derece, reaksiyon süresini arttırdı, bu da artan dönüş açısı ile bu sürenin kademeli olarak artmasına neden oldu. Böylece, bu sonuçlara bakılırsa, denekler uyaranın bir tür zihinsel görüntüsünü - bir tür kısa vadeli görsel kod - döndürebilirler. Bu görsel kodun doğası hakkında da bir sonuca varabiliriz: her durumda
durumda, döndürülebilecek şekilde olmalıdır, bu da kodun yalnızca üç karakterlik bir liste olmadığı anlamına gelir. Özellikler listesi nasıl döndürülebilir? Herhangi bir listeyi döndürmek, tepki süresinde nasıl bu kadar düzenli bir değişikliğe neden olabilir? Shepard ve işbirlikçileri, görsel kodun aşağı yukarı orijinal uyaranın doğrudan bir temsili olması gerektiğine inanıyor.
koyun . Harcanan zamanın, mektubun "jormal" biçimde mi
yoksa ayna görüntüsü şeklinde mi
sunulduğunu belirlemeye bağımlılığı . notoria mektubunun st açısı (Cooper a. Shtpard, 1973). Grafiğin altında
, bütan en havalı konumlarda gösterilmektedir.
Diğer birçok yeni deney de CP kodunun akustik olması gerekmediği fikrini desteklemektedir: CP'de birkaç saniye veya mümkün olduğu kadar uzun süre depolanan bu tür görsel temsiller (DI1'den gelen bilgiler kullanılarak veya doğrudan bir dış uyaranı yansıtan) olabilir. üzerlerinde bazı "işler" yapıldığı için. Bu tür o kadar çok çalışma var ki hepsini burada incelemek mümkün değil. Bununla birlikte, görsel PC tartışmasından ayrılmadan önce, görsel kodların varlığı hipoteziyle ilgili bir grup deneye daha göz atacağız. Bu deneyler, görsel CP'yi incelemek için tasarlanmamıştı. Yazarları Saul Sternberg, öncelikle kısa süreli bellekten bilgi çıkarma sorunuyla ilgileniyordu.
BELLEK TARAMA VE GÖRSEL CP
Sternberg ( 1966), bilginin CP'den nasıl çıkarıldığını incelemek amacıyla ana deneyini kurdu: bir bütün olarak mı algılanıyor, taranıyor mu yoksa okunuyor mu? Tüm bilgiler aynı anda incelenebilir mi - bir tür paralel tarama işlemiyle? Yoksa tarama sırayla mı yapılıyor, böylece her eleman veya yapısal birim arka arkaya mı okunuyor? Bunu ve diğer soruları açıklığa kavuşturmak için Sternberg aşağıdaki problemi geliştirdi. Her denek bir dizi denemeye katıldı ve her denemede ona önce örneğin birden beşe kadar basamaklı bir "standart küme" sunuldu (dört sayı kümesinin bir örneği "2, 4, 7, 3"). Kümedeki öğe sayısı CP'nin hacminden daha azdı ve denekten bunları hatırlaması istendi. Daha sonra kendisine bir "kontrol uyaranı" sunuldu
- orijinal sete dahil edilebilecek veya edilmeyecek bir rakam. Denek, kontrol uyaranı standart setin öğelerinden birine uyuyorsa "evet", bunlardan hiçbirine uymuyorsa "hayır" cevabını vermek zorundaydı. Posner'ın deneylerinde olduğu gibi, denekler bu görevi çok az hatayla tamamlayabildiler, dolayısıyla ölçülen değişken reaksiyon süresiydi (RT). Bu durumda RT, kontrol uyaranının sunumu ile deneğin tepkisi arasındaki zaman aralığı olarak tanımlandı (genellikle bir düğmeye basmaktan oluşur, Şekil 7.5, A).
Igshlіugltom
KflHm/JÖJltrHüU;
sdnіd tsri

Şekil 7.5. Bellek taramasıyla ilgili Sternberg sorunu . 4. Tipik bir numunenin aşamaları
. B. Yargılama sırasında
meydana geldiği iddia edilen zihinsel süreçler ,
Bu kısa sürede ne tür bilgi işlemleri gerçekleşir? Problem muhtemelen Posner'ın deneylerinde olduğu gibi (Şekil 7.5, B) aynı türden ayrı bileşenlere bölünebilir. Bir kontrol uyaranı göründüğünde, öznenin CP'sinin standart bir dizi öğe içerdiği gerçeğinden yola çıkıyoruz. Sonraki işlemenin üç aşamadan oluştuğunu varsayıyoruz. Birincisi, özne kontrol uyaranını algılar ve kodlar - onu bir tür içsel forma çevirir; daha sonra bu uyaranı standart kümenin öğeleriyle karşılaştırır ve son olarak bu karşılaştırmalara dayanarak bir yanıt verir. Tüm bu aşamalarda harcanan toplam süre, belirli bir konunun VR'sidir.
Sternberg, standart kümenin boyutundaki, yani bu kümedeki öğelerin sayısındaki bir değişiklikle ilişkili VR'deki değişikliklerle özellikle ilgilendi. VR'deki bu değişikliklerden, görevin ikinci aşamasında özne tarafından gerçekleştirilen karşılaştırma süreci hakkında bir şeyler çıkarılabilir. Standart seti bir basamak artırırsanız ne olur? Denek, kontrol uyaranını standart setin her bir öğesiyle karşılaştırması gerektiğinden daha fazla karşılaştırma yapmak zorunda kalacaktır. Bir rakam eklendiğinde VR'deki değişiklik, öznenin görevi nasıl yerine getirdiğine bağlı olarak farklı olmalıdır; bu nedenle, VR'nin nasıl değiştiğini öğrendikten sonra, sunulan bilgileri nasıl işlediğine karar verebileceğiz.
, CP'de
paralel bir karşılaştırma süreci hakkında basit bir hipotezimiz olduğunu varsayalım - öznenin bilgi işlemek için sınırsız olasılıkları vardır ve CP'de bulunan her şeyi bir kerede inceleyebilir, harcayabilir.
bu, CP'nin içeriğinin yalnızca bir kısmını görüntülemek için gerekenden daha fazla bir çaba değildir. Bu hipotez, VR'deki değişiklikler hakkında belirli tahminler yapmamızı sağlar. Özellikle, standart sete bir hane eklemenin kan basıncı üzerinde herhangi bir etkisinin olmayacağını bekleyebiliriz. Hafızanın 2, 3 veya 4 öğe içermesinden bağımsız olarak, bu görev için VR değişmeyecektir, çünkü özne, kontrol uyaranıyla birkaç öğeyi karşılaştırmak için bir öğeyi karşılaştırmaktan daha fazla zaman harcamaz. Bu tahmin, Şekil 1'de gösterilmektedir. 7.6, A, BP'nin standart bir setteki eleman sayısına bağımlılığının bir grafiğini gösterir.

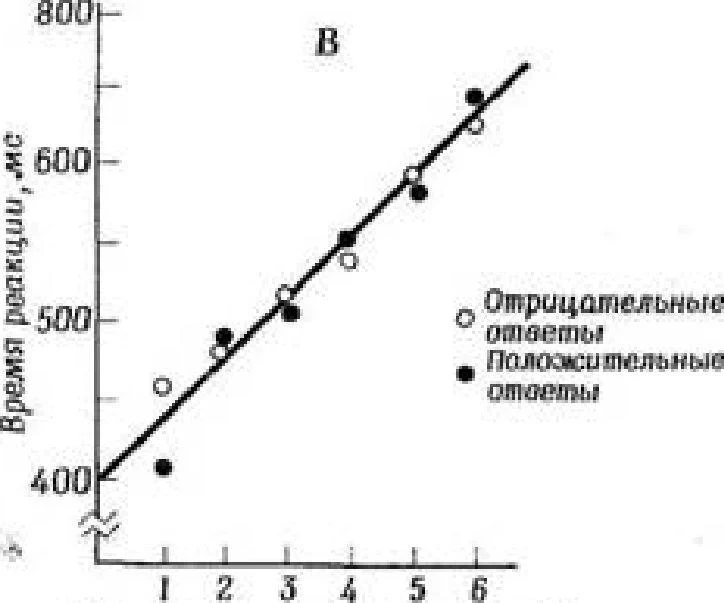
^ keps P 1[ Sternberg* görüntüleyiciden ve bellekten gelen veriler (Âjemberg, iSoO}, L. Paralel tarama hipotezine göre beklenen yanıt süresinin standart setin değerine bağımlılığı ) tarandı.
Başka bir olası hipoteze göre, görev sıralı tarama ile çözülür - özne, uyaranı aynı anda standart kümenin öğelerinden yalnızca biriyle karşılaştırabilir. Bu durumda kümeye eklenen her öğe, görevi tamamlamak için gereken süreyi uzatacaktır. Buna bağlı olarak, RT artacak ve bu artışın derecesi, başka bir figürü bir kontrol uyaranı ile karşılaştırmanın ne kadar zaman alacağına bağlı olacaktır. Bunun, Şekil 1'de gösterilene benzer bir grafikle sonuçlanması beklenmelidir. 7.6B.
Bu seri tarama hipotezini daha ayrıntılı olarak ele alalım. Deneklerin görevi tamamlama sürecinin, her biri harcanan toplam sürenin bir bölümünü kaplayan üç aşamadan oluştuğunu varsaydık. Deneğin bir kontrol uyaranını kodlaması için e milisaniye, standart setin bir öğesini bu uyaranla karşılaştırması için c milisaniye ve üçüncü aşamaya (cevap vermek için) g milisaniye sürdüğünü varsayalım. Standart set sadece bir elemandan oluşuyorsa, denek görevi e + c + r milisaniyede tamamlayabilecektir.
- bu onun VR'ı olacak. Şimdi standart kümede 5 öğe olduğunu ve hiçbirinin kontrol uyaranına karşılık gelmediğini varsayalım. Denek bu durumda olumsuz cevap verecek ve VR'si e + c + c + c + c + c + r milisaniye olacaktır. Genel olarak deneğin benzer bir durumda olumsuz cevap vermesi için geçen süre e + sXc + r'ye eşit olacaktır, burada 5 standart kümedeki eleman sayısıdır. BP'nin bağımlılığını 5'e çizerseniz, düz bir çizgi elde edersiniz. BP=(e+r)+(sXc) denklemiyle tanımlanabilir. Böylece, bu doğrunun eğimi c'ye eşit olacaktır . Başka bir deyişle, eğer bir denek bu görevi yerine getirirse ve biz onun VR'sinin standart kümenin boyutuna olan bağımlılığını olumsuz cevaplarla çizersek, o zaman düz bir çizgi elde ederiz. Bu düz çizginin eğimi teorik olarak deneğin bir karşılaştırma için harcadığı süreye/zamanlara karşılık gelecektir. 5=0'daki RT, uyaranı (e) kodlamak ve yanıtı (d) vermek için gereken süredir .
Tüm dikkatimizi olumsuz yanıtlara odaklamış olmamız okuyucuya garip gelebilir. Bunun nedeni, ancak özne standart setin tüm öğelerini kontrol uyaranı ile karşılaştırdıktan sonra olumsuz bir yanıt verilebilmesidir; yoksa bu sette kontrol uyaranı olmadığını nasıl anlayabilirdi ? Olumlu yanıtlar durumunda, konu standart kümenin öğelerinden birinin kontrol öğesine karşılık geldiğini bulduğunda karşılaştırmayı durdurabileceğinden, resim daha karmaşık hale gelir. Tüm olası karşılaştırmaları yapmak zorunda değildir. Bu, sözde "kendi kendini sonlandıran" hipotezdir: öznenin, kontrol uyaranına karşılık gelen bir öğe bulduğu anda taramayı durdurduğunu varsayar. "Tam görüş" hipotezi olarak adlandırılan başka bir varsayım öne sürülebilir. Bu hipoteze göre denek, karşılık gelen unsuru keşfedip keşfetmemesine bakılmaksızın, karşılaştırma aşamasında tüm standart setini "görüntüler". Karşılaştırmayı durdurmaz, ancak sona getirir. Bu son hipotez sezgisel olarak temelsiz görünüyor, ancak yine de test edilmesi gerekiyor.
"Kendi kendini sonlandıran" ve "tam gözden geçirme" hipotezleri arasında seçim yaparken belirleyici kriter, pozitif yanıtlar için RT fonksiyonunun eğimidir (RT'ye karşı standart ayar değerinin bir grafiği). Denek kontrol uyaranı ile standart setin öğelerinden biri arasında bir eşleşme bulduğunda, bu ortalama olarak setin yarısını izledikten sonra olur. Kendi kendini sonlandıran hipoteze göre, bu, cevabın olumlu olduğu durumlarda, öznenin (ortalama olarak) kümenin ortasına ulaşarak taramayı durduracağı ve olumsuz bir cevap olması durumunda tamamlayacağı anlamına gelir. bu süreç. Konunun kendisi taramayı bırakırsa, olumlu bir yanıtla ortalama (s+l)/2 karşılaştırması yapar. Olumlu yanıtları olan VR'si e+r+[(s+l)/2]Xc olacaktır. Bu formülü, BP'yi 5'in bir fonksiyonu olarak temsil edecek şekilde dönüştürürsek (bu durumda BP=(e+r+c/2)+[(c/2)s] elde ederiz), o zaman eğim şu olur: Olumlu yanıtlar için grafiğin değeri, olumsuz yanıtların yarısı kadardır (olumlu için c/2 ve olumsuz için c-). Buna karşılık, tam görünüm hipotezi, olumlu ve olumsuz yanıtlar için karşılaştırma adımının aynı olduğunu - her iki durumda da olası tüm karşılaştırmaların yapıldığını - ve bu nedenle grafiğin eğiminde böyle bir fark olmaması gerektiğini belirtir (her iki durumda da, eğimler c)'ye eşit olacaktır.
Şimdi üç hipotezimiz var. Bunlardan biri, VR'nin 5'e bağımlılığının hem pozitif hem de negatif yanıtlar için yatay bir düz çizgi olarak ifade edileceğini öngören paralel tarama hipotezidir (Şekil 7.6, A). Diğer iki hipotez, ardışık tarama hipotezinin varyantlarıdır, buna göre karşılaştırmalar bire yapılır ve standart setteki eleman sayısıyla VR artar (Şekil 7.6, B). Bir düzenlemede, tarama işleminin kendi kendini sonlandırdığı varsayılmaktadır. Bu durumda, pozitif cevaplar için grafiğin eğimi, negatif cevaplar için olanın yarısı olacaktır. Başka bir seçeneğe göre, tarama kapsamlıdır ve olumlu ve olumsuz cevaplar için grafikler arasında fark olmamalıdır.
Bu hipotezlerin ne kadar makul olduğunu belirlemek için bir deney yapmalıyız. Her biri birçok deneme yapmış olan birkaç denek için .BP değerine ilişkin veri toplamak gereklidir. Numuneler hem pozitif hem de negatif olmalı ve birkaç farklı standart set boyutunda gerçekleştirilmelidir. Ardından, pozitif ve negatif olmak üzere her numune türü ve standart setlerin her biri için ortalama reaksiyon süresini hesaplamalısınız. Bundan sonra, BP'nin s'ye bağımlılığını çizmeniz gerekir. Sternberg'in yaptığı tam olarak buydu ve sonuçları Şekil 1'de gösteriliyor. 7.6, B. Yukarıdakilerin hepsinden, onun: verilerinin sıralı kapsamlı tarama hipotezi lehine konuştuğu sonucu çıkar. Sternberg'in sonuçlarının bu varsayımı desteklemesi özellikle ilgi çekicidir, çünkü gördüğümüz gibi, tam tarama hipotezi sezgisel beklentilerimizle çelişir. Bu hipoteze göre, deneğin, standart kümenin öğelerinden birinin kontrol uyaranı ile eşleşmesini bulsa da bulmasa da, her zaman standart kümenin tüm öğelerini bu uyaranla karşılaştırdığını hatırlayın. Bir eşleşme bulursa karşılaştırmayı bırakmaz. Ve bu, öyle görünüyor ki, olumlu bir cevap durumunda, yani bir eşleşme bulunduğunda, öznenin birçok gereksiz karşılaştırma yaptığı anlamına gelir.
Bununla birlikte, kapsamlı tarama açıklanabilir. Bunun için öncelikle tarama sırasında gerçekleşen karşılaştırma sürecini iki bileşene ayırıyoruz. Biri karşılaştırma eyleminin kendisi, diğeri ise karşılaştırmanın sonuçları hakkında verilecek karardır . Karşılaştırma, standart kümenin öğelerinden biri ile kontrol uyaranı arasında bir eşleşme olduğunu ortaya çıkarırsa, karar olumlu olacak ve olumlu bir yanıta yol açacaktır. Aksi takdirde cevap olumsuz olacaktır.
Şimdi, öznenin kontrol uyaranını standart setin öğeleriyle karşılaştırması için mevcut olan süre çok kısaysa ve bu karşılaştırmanın olumlu bir sonuca yol açıp açmadığına karar vermesi gereken süre nispeten uzunsa ne olacağını görelim. Kendi kendini sonlandıran bir süreç olması durumunda, standart set boyunca ilerlemesi şu şekilde temsil edilebilir: bir eşleşme bulunana kadar (“evet” kararı verilir) veya standart tükendi.kit. Kapsamlı süreç şu şekilde görünecektir: karşılaştırın, karşılaştırın, karşılaştırın vb. ve ardından - standart set tükendiğinde - karar verin. Karar, karşılaştırmadan çok daha uzun sürerse, kapsamlı bir taramanın daha faydalı olabileceğini görmek zor değildir: yalnızca tek bir karar gerektirir. Bu nedenle, özne çok hızlı bir şekilde - karar vermek için durması zor olacak kadar hızlı - karşılaştırmalar yapabilirse kapsamlı tarama daha etkili olacaktır. Bunun yerine, konu tüm set boyunca "ateş eder" ve ancak o zaman bir karar verir ve bir cevap verir.
Kapsamlı taramanın bu açıklaması doğruysa, karşılaştırma çok az zaman alacaktır. Bu, RT'ye karşı standart ayar değeri grafiğinin eğimi hesaplanarak RT verilerinden doğrulanabilir; teorik olarak bu eğim, kontrol uyaranını standart setin bir öğesiyle karşılaştırmak için geçen süreye karşılık gelir. Hesaplama, gerçek verilerin çok hızlı bir karşılaştırma varsayımını desteklediğini gösteriyor. Tilkiler üzerinde sunulan verilerden. 7.6B'de, negatif yanıtlar için RT grafiğinin eğimini belirleyen c değişkenimizin yaklaşık 35 ms (0.035 s) olduğu sonucuna varabiliriz. Denek, kontrol uyaranı standart setin bir öğesiyle karşılaştırarak 0,035 s harcar. Bundan, öznenin bir saniyede yaklaşık 30 benzer karşılaştırma yapabileceğini hesaplamak kolaydır. Şaşırtıcı derecede hızlı!
Bu keşif bizi bu bölümün ana temasına geri getiriyor. Çıkarılan eşleştirme hızı, karşılaştırmaların CP'de akustik olarak sunulan sözel etiketler temelinde yapılmadığını gösterir. Sternberg (1966), nispeten yavaş iç konuşma hızı hakkında bildiklerine (ve bizim de bildiklerimize) dayanarak bunu tartışabilir. Bu hızın ölçümleri ve ayrıca dış konuşmanın hızı (bkz. Bölüm 5), öznenin akustik olarak saniyede yalnızca altı öğeyi tekrarlayabildiğini gösteriyor. Sternberg görevindeki karşılaştırmalar akustik kodlara dayalıysa (ve uyaranlar dahili olarak "seslendirildi"), o zaman saniyede altıdan fazla karşılaştırma beklenemezdi. Bu durumda, VR grafiğinin eğimi yaklaşık olarak şuna karşılık gelirdi: 170 ms, fiilen gözlemlenen eğim ise 35 ms'ye karşılık gelir. Bu nedenle, karşılaştırmalar pek akustik olamaz.
Bu bağlamda Sternberg (1967), akustik kodlardan ziyade görsel kodların karşılaştırıldığını ve görsel tabanlı karşılaştırmaların sözel karşılaştırmalardan daha hızlı yapıldığını öne sürmüştür. (Burada, görsel tekrarın sözlü tekrardan daha yavaş olduğu şeklindeki önceki varsayımımızla çeliştiğine dikkat edilmelidir. Ancak, sözlü tekrar sırasında, harfler DP'den çıkarılırken, görsel tekrar sırasında, açıkça zaten CP'de yer almaktadırlar. sürecin başında taramalar yapılır ve grafiğin eğimi sadece karşılaştırmalar için harcanan zamanı yansıtır.) Göreceğimiz gibi, Sternberg görevi sırasında görsel temsillerin işlendiği fikrini destekleyen çok sayıda veri vardır.
Bellek taramasında görsel kodların kullanıldığı varsayımını test etmek için Sternberg (1967), kontrol uyaranını ya kısmen maskelenmiş ya da "normal" bir biçimde sunmuştur. Maskeleme için kontrol uyaranına satranç tahtası şeklinde bir desen uygulandı. RT'nin standart setin boyutuna bağımlılığı çizildiğinde, maskelenmiş uyaran için bu fonksiyonun y ekseni ile kesişme noktasının normal olandan daha yüksek olduğu ortaya çıktı. Bu, bir dama tahtası deseniyle maskelenen bir uyaranın algılanması ve kodlanmasının daha uzun sürmesi (toplam RT'nin e bileşeni artar) gerçeğiyle açıklanabilir. Ancak daha da önemlisi, grafiğin eğimini de artırdı (karşılaştırma için geçen süreye karşılık geldiğine inanıyoruz). Bununla birlikte, ikinci etki zayıf bir şekilde ifade edildi ve iyi eğitilmiş deneklerde, uyaranın iki varyantı için grafiğin eğiminde hiçbir fark yoktu.
Sternberg bu sonuçları şu şekilde yorumladı. Kontrol uyaranının kısmi maskelenmesinin grafiğin eğimi üzerinde bir miktar etkisi olduğundan, karşılaştırma için görsel bir kodun kullanıldığını düşünebiliriz: sonuçta, uyaran sözlü bir forma dönüştürüldüyse (yani, özne uyaranı algıladıysa) , adlandırdı ve ardından bu adı standart kümenin öğeleriyle karşılaştırdı), ardından uyaranın maskelenmesi onu algılamayı ve adlandırmayı zorlaştırabilir, ancak sonraki karşılaştırmalarda bu adın kullanılmasını etkilemez. Dolayısıyla karşılaştırma süresinin değişmemesi ve dolayısıyla grafiğin eğiminin değişmemesi gerekirdi. Eğimin değişmesi, karşılaştırılanların isimler değil, görsel imgeler olduğunu gösteriyor. Ancak iyi eğitilmiş deneklerde grafiğin eğimi çok az değişti. Bu, karşılaştırma için birincil olmayan duyusal görüntülerin kullanıldığını gösterir. Kontrol uyaranının maskelenmesi, duyusal görüntünün keskin bir şekilde bozulmasına yol açtı ve karşılaştırma için kullanılması, karşılaştırma süresini büyük ölçüde artıracaktı. Bu arada grafiğin bu zamanı yansıtan eğimi biraz değişti; bu, görünüşe göre, standart setle duyusal bir görüntünün karşılaştırılmadığı anlamına gelir. Kısacası Sternberg görevinde kullanılan uyaran kodunun görsel olduğu ancak duyusal olmadığı düşünülebilir, yani benimsediğimiz terminolojiye göre kısa süreli belleğin görsel kodudur.
Başka bir deneyde, Clifton ve Tash (Clifton ve Tash, 1937), standart kümenin öğelerinin harfler, 6 harfli üç heceli sözcükler (örneğin, POLICY) veya 6 harfli tek heceli sözcükler olduğu Sternberg probleminin versiyonlarını kullandılar. (örneğin, SOKAK). Her bir uyaran türü için, RT grafiğinin eğimini hesapladılar. Tüm eğimlerin yaklaşık olarak aynı olduğu ortaya çıktı. Bundan, standart kümenin öğelerindeki ve kontrol uyaranındaki hece sayısının karşılaştırma için gereken süreyi etkilemediği sonucuna varabiliriz. Bununla birlikte, bu, karşılaştırma hızının, öğelerin adlarını telaffuz etmenin ne kadar süreceğinden bağımsız olduğu anlamına gelir; bu, karşılaştırma için akustik kodlar kullanıldığında saçma görünen bir sonuçtur. Aynı zamanda eğimlerde bir farkın olmaması da elemanın görsel olarak algılanan uzunluğunun karşılaştırma hızını etkilemediğini göstermektedir. Bu, görsel görüntüler karşılaştırıldığında, görsel olarak algılanan boyutların büyük olasılıkla VR üzerinde bir etkiye sahip olacağı duyusal seviyeden muhtemelen çok uzak oldukları anlamına gelir. Dolayısıyla bu deney, Sternberg problemindeki karşılaştırmaların duyusal olmayan, akustik olmayan kodlara dayandığını öne sürüyor, ancak sonuçlardan bu kodların görsel olup olmadığı net değil.
Klatzky ve Atkinson'ın (Klatzky ve Atkinson, 1971) deneyinde Sternberg görevlerinin yerine getirilmesinde görsel kodlama lehine biraz daha inandırıcı kanıt elde edilmiştir. Bu yazarlar, beynin iki yarımküresinin spesifik işleme yeteneklerinden, yani beynin sol yarısının (çoğu insanda) sözel materyali işlemek için ve sağ yarısının görsel uzamsal bilgiyi işlemek için uzmanlaştığı gerçeğinden hareket ettiler. Araştırmalarının temeli olarak, Sternberg'inkine benzer bir bellek tarama deneyi gerçekleştirdiler, tek fark, kontrol uyaranının özneye görsel alanının solunda veya sağında sunulmasıydı. İnsanlarda göz ile beyin arasındaki bağlantılar, her iki gözün görme alanının sol tarafından gelen bilgiler doğrudan beynin sağ yarıküresine, sağ tarafından da sol yarıküresine gidecek şekilde düzenlenmiştir. Bu sayede Klacki ve Atkinson, kontrol uyaranını önce bir yarım küreye, sonra diğerine yönlendirebildiler ve her yarım küre için VR'nin standart kümenin boyutuna bağımlılığını belirlediler. Uyaran sol yarım küreye yönlendirildiğinde, her iki durumda da arsanın eğimi aynı olmasına rağmen, VR grafiğinin y ekseni ile kesişme noktası sağ yarım küreye gönderildiği duruma göre daha yüksekti. Klacki ve Atkinson, bu farkı bir yarım küreden diğerine bilgi aktarımının sonucu olarak yorumladılar. Şu şekilde akıl yürüttüler: sol yarıküreye bir kontrol uyaranı geldiğinde, bununla ilgili bilgi önce sağ yarıküreye iletilmelidir ve ancak o zaman eşleştirme başlayabilir; bu aktarım için biraz zaman gerekir ve sonuç olarak VR grafiğinin y ekseni ile kesişme noktası buna göre kaydırılır. Uyaran doğrudan sağ hemisfere iletildiğinde, böyle bir iletime gerek yoktu. Bu, karşılaştırma sürecinin, sözel bilgiden ziyade uzamsal bilgiyi işlemek için uyarlanmış olan sağ yarıkürede gerçekleştiğini gösterir. Bu, karşılaştırmaların sözlü bir kod yerine görsel imgeler kullandığı fikrine önemli ölçüde destek vermektedir. Bu deney, Sternberg'inki gibi (Slernberg, 1967), SP'nin muhtemelen görsel kodlar kullanabileceğini ve SP'nin tamamen akustik doğası kavramının yeniden gözden geçirilmesi gerektiğini doğrulamaktadır 1 . Daha sonra göreceğimiz gibi, CP'deki bilgilerin semantik bir biçimde de saklanabileceğine dair kanıtlar var.
1 Burada, Sternberg deneyinin ve diğer benzer çalışmaların açıklamasını biraz basitleştirmemiz gerektiğini not etmek önemlidir. Bazı önemli basitleştirmelerden bahsetmek gerekir. Her şeyden önce, sıralı ayrıntılı tarama modeli, standart setteki eleman sayısındaki artışla RT'deki doğrusal artışı açıklayabilen tek model değildir. Aynı sonuçlara yol açacak bir paralel tarama modeli önerilebilir (Townsend, 1972). Böyle bir model, incelediğimiz basit paralel modelden (VR'nin standart kümenin boyutundan bağımsızlığını öngören model) farklıdır, çünkü öznenin bilgiyi işlemek için yalnızca sınırlı bir yeteneğini varsayar. Aynı zamanda, işleme mekanizmalarının etkinliği, işlenecek tüm öğeler arasında eşit olarak dağıtılmalıdır. Bu unsurlardan birkaçı olduğunda, her biri nispeten daha fazla bu aktiviteye sahiptir ve işlem hızlı bir şekilde gerçekleşir. Eleman sayısı fazla ise bu aktivite daha "akıcı" dağıtılır, her eleman daha az alır ve işlem daha uzun sürer. Bu paralel bir modeldir çünkü tüm öğelerin aynı anda taranabileceğini varsayar. Bu arada, sınırlı bilgi işleme yeteneği nedeniyle standart setteki öğelerin sayısındaki artışla birlikte VR'de bir artış öngörüyor. Sternberg'in elde ettiği sonuçları tahmin etmeyi mümkün kılan bir başka model de, sıralı bir kendi kendini sonlandıran süreç olarak bellek taraması kavramıdır (Theios. a. o., 1973).
İkinci açıklama, kontrol uyaranıyla çakışan öğenin standart sette kapladığı yerin etkisi ile ilgilidir. Olumlu tepkiler için, VR'nin bu öğenin yerine bağımlılığı çizilebilir (örneğin, standart bir set ve bir kontrol uyaranı P ile bu ikinci, bir kontrol uyaranı Q ile üçüncü, vb. olacaktır.) . Ardışık kapsamlı tarama modeli, özne aranan öğenin konumuna bakılmaksızın her zaman tüm standart kümeyi "taradığından" böyle bir grafiğin yatay bir düz çizgi olacağını tahmin eder. Bununla birlikte, bu türden çeşitli deneylerde, serideki yere bağlı olarak RT'nin artması, RT'nin azalması ve son olarak ters U şeklinde bir eğriye karşılık gelen veriler elde edildi. Bunların ve diğer verilerin bir incelemesi Nickerson'da (1972) bulunabilir. Sternberg'in (1969) ayrıntılı analizi de ilgi çekicidir.
KISA SÜRELİ HAFIZADAKİ SEMANTİK KODLAR
CP'de bilgileri akustik biçimde depolama fikri ilk olarak karışıklık hatalarının doğası ile bağlantılı olarak ortaya çıktığından, CP'de yer alan anlamsal bilgilerin ilk gösteriminin de karışıklıklara dayanması çok şanslı görünüyor. Shulman (1972), SP'de meydana gelen karıştırmanın doğasının muhtemelen bilginin anlamından tahmin edilebileceğini göstermiştir. Deneylerinde deneklere, her biri kendilerine 10 kelimelik bir liste sunularak başlayan bir dizi deneme verildi. Onuncu kelimeyi bir kontrol kelimesi takip etti ve deneğin listede yer alan kelimelerden herhangi birine "karşılık gelip gelmediğini" söylemesi gerekiyordu. Bazı denemelerde "yazışma", tam kimlik anlamına gelirken, diğerlerinde aynı anlam (veya eşanlamlılık) anlamına geliyordu. Her denemede, kontrol sözcüğünden hemen önce deneğe bu denemede ne tür bir eşleşmenin kastedildiği söylendi.
Kontrol kelimesinin listede yer alan kelimelerden birinin eşanlamlısı olduğu ve deneğin özdeşlik ilkesine göre eşleşmesinin istendiği durumlar özellikle ilgi çekicidir. Listede aynı kelime olmamasına rağmen özne "evet" yanıtı verirse, bu anlam karışıklığını gösterir; öznenin bu hatayı yaptığından şüphelenebiliriz (kontrol kelimesini liste öğelerinden biriyle yanlış tanımlamıştır, oysa aslında sadece eşanlamlıdır), çünkü aralarındaki anlamsal benzerlikten dolayı iki kelimeyi karıştırmıştır. Bunun olması için, öznenin CP'sinin yazım yanlışında yer alan kelimelerin anlamsal içeriği hakkında bazı bilgiler içermesi gerekir. Shulman, tam da özneyi yapabilirse bu tür anlamsal bilgileri etkinleştirmeye teşvik etmek için, yazışmaların eşanlamlılık anlamına geldiği deney denemelerine dahil etti.
Shulman tarafından elde edilen sonuçlar, CP'deki bilgilerin anlamsal temsili lehine tanıklık ediyor. Bir kontrol kelimesinin listenin unsurlarından biriyle yanlış tanımlanmasının, bu kelime ile listenin unsurları arasında herhangi bir anlamsal ilişkinin yokluğundan ziyade, bu kelimenin unsurlardan birinin eşanlamlısı olduğu durumlarda daha sık meydana geldiğini bulmuştur. . Bu tür hatalar, kontrol kelimesi en son sunulan kelimelerden birinin eşanlamlısı olduğunda bile (örneğin, satırdaki son üç yerden birini işgal ediyor), yani CP'de neredeyse kesinlikle yer alan kelimeler (eğriyi hatırlayın) olduğunda bile meydana geldi. sıradaki yerlere karşı ücretsiz geri çağırma - bkz. bölüm 2). Böylece, CP'de anlamsal bir temeli olan karışıklıklar bulduk.
SP'deki anlamsal temsiller lehine kanıtlar başka yollarla da elde edilmiştir (inceleme için bkz. Shulman, 1971). En kapsamlı çalışma, proaktif ketlemeyi serbest bırakma fenomenini kullanan Wickkeyas ve iş arkadaşlarına aitti (inceleme için bkz. Wickens, 1972).
Wickens'ın çalışmasını anlamak için, Bölüm 1'de açıklanan iki deneyi hatırlamamız gerekiyor. 6 KP'den unutmayı tartışırken. Bunlar Peterson ve Peterson (Peterson ve Peterson, 1959) ile Ketshel ve Underwood'un (Keppel ve Underwood, 1962) deneyleridir. Özetle, Peterson'lar sunum ve hatırlama arasındaki 18 saniyelik aralıkta ünsüz trigramın hızlı bir şekilde unutulduğunu gözlemlediler ve ardından Keppel ve Underwood, bu tür bir unutmanın yalnızca ilk birkaç denemeden sonra proaktif frenlemenin olduğu durumlarda meydana geldiğini gösterdi. Bu verilere dayanarak, Wickens ve ark. (Wickens a. o., 1963) aşağıdaki tipte bir deney gerçekleştirdi. Bir özneye, sessiz harflerden oluşan çeşitli trigramların ezberlenmiş malzeme olarak hizmet ettiği ve 11 saniyelik bir akılda tutma aralığında belirli bir görev-dikkat dağıtıcının gerçekleştirilmesi gereken Peterson görevinde üç deneme verildiğini hayal edin. Bu süre zarfında, proaktif engelleme (PT) oluşturulur ve her denemede denek daha az ünsüz ezberler. Dördüncü testten önce ezberlenen materyalin doğası değiştirilir: üç ünsüz yerine üç sayı sunulur. Böyle bir deneyin tipik sonuçları Şekil l'de görülebilir. 7.7. Sayılarla sunulan deney grubunda, ünsüzlerle sunulmaya devam edilen kontrol grubuna göre hatırlama yeteneği aniden arttı. Esasen, dördüncü denemede (sayılarla) deney grubundaki hatırlama etkinliği, ilk denemedekine (ünsüzlerle) yakındır. Görünüşe göre ilk denemelerde kırılan PT, belirli bir malzeme türüne (bu durumda ünsüzler) özgüdür ve yeni malzemeyi (sayıları) etkilemez. Bu nedenle, sayılara geçiş, etkinliği AT'nin varlığından önemli ölçüde daha yüksek olan, proaktif inhibisyondan bağımsız bir aktiviteye geçiştir.
PhŞ 7.7. Vrsіzktnvііogy tbrolozhechiya'nın kaldırılması (Wfckens, 1972). Grafikte, deneme sayısının bir fonksiyonu olarak doğru hatırlanan öğelerin yüzdesine ilişkin idealize edilmiş veriler gösterilmektedir.
PT'nin şu veya bu tür ezberlenmiş materyalle ilgili özgüllüğü son derece önemli bir gerçektir. PT'nin çıkarılması, bu durumda "yeni" bir malzemenin kullanıldığını gösterir. Bu nedenle, PT geri çekme etkisi, SP'de uyaranların hangi yönlerinin temsil edildiğini bulmak için bir araç olarak hizmet edebilir. Bunu belirli bir örnekle açıklayalım. Onunla birkaç deneme yaparak konuyla ilgili bir PT oluşturduğumuzu varsayalım, burada üç kelimelik gruplar ezberlenmiş materyal görevi görüyor. İlk üç denemede, tüm kelimeler yiyecek anlamına gelir. 1. numunede bunlar EKMEK, YUMURTA, SÜT; 2. numunede — ET, BALIK, PEYNİR, 3. numunede — TEREYAĞI, YUMURTA, PEYNİR. Ve 4. örnekte, hayvanların adlarından oluşan yeni bir tür trigram tanıtıyoruz: KÖPEK, KOPTKA, HORSE. Bu numunede PT geri çekilmesi gözlemlenecek mi? Geri çağırma verimliliğinde çarpıcı bir artış olacak mı? Mevcut olasılıkları ele alalım.
PT'nin çıkarılmasının gözlenmediğini varsayalım. Bu, ezberlenen materyalin türünün aynı kaldığı anlamına gelir. Biraz daha ileri gidersek, konu açısından malzemenin doğasını değiştirmedik, yani test sırasında kodlayıp depoladığı bilgileri değiştirmedik demektir. Açıkçası, ilk üç denemede tüm kelimelerin gıda maddelerinin isimleri, dördüncü denemede ise hayvanların isimleri olduğunu hatırlamıyor. Şimdi PT'nin geri çekildiğini - dördüncü denemede hatırlama yeteneğinde ani bir sıçrama - bulduğumuzu varsayalım. Bu, farklı bir malzeme türüne geçişi gösterir. Dolayısıyla, deneğin ilk denemelerde edindiği bilgiler bağlamında, yiyeceklerden hayvanlara geçiş mantıklıydı. Ancak bundan, öznenin ezberlenen kelimelerin anlamı hakkında bazı bilgileri kodlaması ve depolaması gerektiği - ilk kelime grubunun yiyecek türlerini ifade ettiği ve ikincisinin olmadığı sonucu çıkar. Kısacası, bilginin anlamının CP'de saklandığına dair kanıtımız olur.
Wickens, semantik içerikteki değişikliklere gerçekten de hatırlama verimliliğindeki bir kaymanın eşlik ettiğini buldu. Bir örnek, az önce tarif edilene benzer bir değişimdir (yemekten hayvanlara); PT'yi kaldırma etkisine yol açarlar. Aynı etki, bir dilden diğerine geçerken de görülür (örneğin, Fransızcadan İngilizceye); eril isimlerden (uşak, horoz, halı) dişil isimlere (kraliçe, etek, inek); soyut isimlerden (kar, can sıkıntısı, mevki) somut isimlere (saray, akrobat, fabrika) ve daha birçok geçiş. CP'nin sadece akustik kodlarını değil, ezberlenmiş öğelerin anlamsal seviyesini temsil ettiği sonucuna varabiliriz.
Az önce sıralanan deneylerin sonuçları CP'de anlamsal kodlama fikrini destekliyor gibi görünse de, başka bir şekilde yorumlanabilirler. Baddeley (1972), anlamsal SP ile ilgili bu ve diğer verilere itiraz eder. Ona göre, semantik CP'ye ilişkin veriler aslında öznenin DP'de saklanan tekniklerin ve kuralların kullanımına başvurmasının bir sonucu olarak ortaya çıkıyor. Örneğin, özne, bir dizi harfi hatırlaması gereken bellek miktarını belirleme görevini yerine getirdiğinde, çoğaltma sırasında bir karışıklık hatası yapması ve herhangi bir sayıyı adlandırması pek olası değildir. Geri çağırma sırasında CP, "a" harfinin bir izini içeriyorsa, konu onun yerine "h" harfini adlandırabilir, ancak "8" 1 sayısını söyleyemez - çünkü bildiği gibi , seri sunulan mektuplardan oluşuyordu. Aynı şekilde, denek, sonuçların anlamsal bilginin CP'de depolanabileceği teorisi ile tutarlı olacak şekilde DP ile yapılan deneylerde DP'den gelen bilgileri kullanabilir.
Akustik bir miksaj hatasından bahsediyoruz: İngilizcede a, hu 8 sesi sırasıyla "hey", "h" ve "ayt" gibi, — Not. ed.
Proaktif engellemeyi kaldırma olgusunu düşünün. Baddley'e göre, bu fenomen, CP'de değil, DP'de bilgilerin işlenmesini gösterir. Bu testte denek, sıradaki en son öğeleri hatırlamaya çalışır. Tutma aralığı, aradığınız bilgilerin artık CP'de bulunmayabileceği kadar uzundur. Ek olarak, önceki birkaç örnekte sunulan malzeme, bir girişim kaynağı olarak işlev görür. Eğer bu malzeme şu anda hatırlanması gerekene benziyorsa (örneğin, tüm öğeler aynı kategorideki kelimelerse, örneğin hayvanların adları), o zaman deneğin yapabileceği tek şey en son öğeleri seçmektir. elemanların sunum sırası veya zamanı hakkında bazı bilgileri kullanmak. Öte yandan, hatırlanacak materyal daha önce sunulandan farklıysa (PT çıkarma testinde olduğu gibi), o zaman bu fark, deneğin en yeni unsurları seçmesine yardımcı olan ek bir faktör olarak hizmet eder. Örneğin, önceki denemelerde hayvan adları kullanılmışsa ve mevcut denemede gıda türlerinin adları kullanılmışsa, bu farklılıklar mevcut denemede sunulan en son unsurların çıkarılması için temel oluşturabilir. Bu ayrımın kullanılması daha iyi hatırlamaya ve PT'nin geri çekilmesi fenomenine yol açar.
Proaktif inhibisyonun ortadan kaldırılmasının LTP'den bilgi çıkarılmasıyla açıklandığı yönündeki ampirik veriler Gardiner ve arkadaşları tarafından elde edilmiştir (Gardiner a.o., 1972). Bir alt sınıfın malzemesinden aynı sınıfın başka bir alt sınıfının malzemesine geçişi kullanarak PT'nin kaldırılması için testler yaptılar. Örneğin, önceki denemelerdeki tüm öğeler kır çiçeklerinin adlarıysa, son denemede bunun yerine bahçe çiçeklerinin adları sunulabilir. Deneyciler, tipik PT geri çekilmesinin yalnızca belirli koşullar altında gerçekleştiğini bulmuşlardır. Görevi kolaylaştırmak için konuya sınıfın genel adı (örneğin, ÇİÇEKLER) verildiyse gerçekleşmedi. Bununla birlikte, sunum sırasında veya geri çağırma sırasında kendisine daha spesifik bir alt sınıf adının (örneğin, WILDFLOWERS) söylendiği durumlarda gözlemlendi. Bu sonuçlardan özellikle önemli iki sonuç çıkmaktadır. İlk olarak, aynı malzeme için PT'nin çıkarılması belirli koşullar altında gerçekleşebilir, ancak diğer koşullar altında gerçekleşemez. Bu, ezberlenen malzemenin doğasındaki değişikliğin kendi başına PT'nin çıkarılmasına neden olmadığını gösterir. İkinci olarak, PT'nin kaldırılması, ilgili "anahtarın" - belirli bir sınıfın adı - geri çağrılması sırasında konuyu bilgilendirerek elde edilebilir. Bu, PT'nin çıkarılmasının bilgilerin çıkarılması sırasında gerçekleştirilmesi lehine güçlü bir argümandır. Başka bir deyişle, "anahtarın" yalnızca geri çağırma anında verildiğinde (ve materyalin kodlanmasının gerçekleştiği zamanda değil) etkili olması, PT'nin kaldırılmasının kodlamaya bağlı olmadığını gösterir. Görünüşe göre anahtarın etkisi bilgi alma döneminde olabilir ve varlığı veya yokluğu TP'nin kaldırılıp kaldırılmayacağını belirler. Bu nedenle, mevcut kanıtlar, PT'nin kaldırılmasının, uzun süreli bellekten bilgi alma süreçlerine bağlı olduğunu göstermektedir.
Baddley'in eleştirileri ve yukarıdaki veriler, kısa süreli bellekte anlamsal temsillerin varlığı konusunda şüphe uyandırmaktadır. Ancak KP konseptimiz bu sorunu çözmeye yardımcı olabilir. CP'nin malzemenin mekanik tekrarla tutulduğu kısmını basitçe ele alırsak, o zaman semantik içeriğin burada herhangi bir önemli rol oynaması olası görünmüyor. Ancak CP'nin çalışma alanını, özellikle de CP'nin yapılandırma gibi işlevleri yerine getirmedeki rolünü göz önünde bulundurarak, CP'nin esasen semantik bir yapıya sahip olan kısmıyla ilgileniyoruz. KP konseptimizden, bilgilerin kısa süreli depolanmasıyla ilgili birçok görevin aynı zamanda DP'nin önemli ölçüde katılımını gerektirdiği sonucu çıkar. Bu iki bilgi deposu arasındaki etkileşim düşüncesi, anlamsal bilginin CP'de depolamak için kodlanabileceği ve DP'nin dahil olduğu CP için kodlama eyleminin dikkate alınabileceği fikrini modelimize dahil etmemize yardımcı olur. CP'nin "çalışmasının" bir biçimi olarak.
Bu aşamada, aşağıdakiler açık görünüyor: Bu üç bölümdeki tartışmanın bir sonucu olarak yaratılan SP resmi, Bölüm 1'de ana hatları çizilen basit teoriye çok az benziyor. 2. Ama en başından beri yeterli bir teorinin bu kadar basit olamayacağını biliyorduk. Kanıtlar kısa süreli belleğin gerçekten de çok karmaşık olduğunu gösterdiğinden SP teorileri daha karmaşık hale geldi.
DUALITE TEORİSİ HAKKINDA BİRKAÇ SÖZ DAHA
Şimdi kısa süreli hafıza tartışmasından uzaklaşalım ve hafızanın dualite teorisinin ilginç bir versiyonuna - sözde "tampon model" e (Atkinson ve Shiffrin, 1968) daha yakından bakalım. Bu teori, karmaşık, "bilişsel" bir CP fikrini zaten bilinen iki tür hafıza kavramı çerçevesine sokmaya çalışması bakımından dikkat çekicidir. Hafızadaki "düzenleyici süreçler" ile "yapısal bileşenler" arasında ayrım yapmayı önerenler Atkinson ve Shifrin'di ve bu bağlamda özellikle ilgi çekici olan, CP'deki düzenleyici süreçlere yaklaşımlarıdır.
Düzenleyici sürecin yerleşik olmadığını, yalnızca dahili yapılara bağlı olduğunu hatırlayın. Yüzün önünde. öznenin hafıza sistemini belirli bir şekilde çalıştırma kararı vermesinin sonucudur, bu bilinçli olmayabilir. Şu soruyu sorabiliriz: bilgi işleme sistemi CP'yi hangi parametrelere göre düzenleyebilir? Bir işlem grubu, bu modelde "tekrarlama arabelleği" olarak adlandırılan bilgileri depolamak için CP'de bulunan alan miktarını düzenler. Atkinson ve Shifrin'e göre burası, daha karmaşık bazı "işlerin" değil, yalnızca az sayıda yapısal birimin mekanik tekrarının gerçekleştirilebileceği yerdir. Buradaki ayarlanabilir parametreler arasında şunlar yer alır: kullanılan arabelleğin boyutu (elbette, bellek miktarıyla belirlenen sınırlar dahilinde), arabellekteki öğe sayısı ile çalışma alanı arasındaki oran (küçük bir değere sahip çok sayıda öğe olmalı) çalışma alanı veya çok daha geniş bir çalışma alanına sahip birkaç öğe) . İkinci durumda, seçim tekrarlama sürecinin kendisine bağlıdır. Belirli öğeleri tekrarlamayı seçebiliriz çünkü bunlar birbirine çok iyi uyuyorlar, örneğin ritimleri benzer: "iş", "deste", "esneme", "doğa" ("tutarsızlık" kelimesini bu kümeye eklemezdik) tekrarların sayısı). "). Ya da bazı elemanların tekrarını durdurabilir ve tampondan kaldırabiliriz.
Bu, bizim basit hücre modelimize yeniden benzemeye başlarsa, böyle bir izlenime kapılmamak gerekir. Sonuçta bu model, CP'nin çalışma alanını etkileyen düzenleyici süreçleri de içerir ve CP'den DP'ye iletilen bilgi biçiminin bu süreçleri abartacağını şart koşar. Atkinson ve Shifrin, birçok öğenin tekrarının mekanik olarak yapılabileceğini kabul ediyor, ancak bu durumda bunlar, yalnızca bir dereceye kadar zenginleştirilerek DP'ye aktarılacak. Belki de bu durumda, yalnızca CP'de oldukları gerçeği DP'ye giriyor. Bu, işlenen unsurlar hakkında DP'ye aktarılan bilgilerle karşılaştırılmalıdır. Öğeler aracılık edilebilir, bir şeyle ilişkilendirilebilir veya yapılandırılabilir, ardından bilgiler zenginleştirilmiş bir biçimde DP'ye aktarılabilir. Ancak bu zenginleştirme maliyetli bir süreçtir: CP'de bulunabilecek öğelerin sayısını azaltır.
Bu nedenle, çalışan bellek ile depolama alanı arasında (Bölüm 6'da tartışıldığı gibi) sürekli bir "ticaret" olduğu fikri daha da geliştirilmektedir. Ama sadece bu değil. Tampon modeli, CP ile DP arasındaki yakın ve karmaşık bağlantıların yanı sıra CP'de anlamsal ve görsel bilgilerin saklanma olasılığı fikrine dayanmaktadır. Ele aldığımız deneylerin sonuçlarına göre bu model, bir hücre kümesi olarak bir CP fikrinden çok daha karmaşıktır.
8. Bölüm
Uzun süreli bellek: bilginin yapısı ve anlamsal olarak işlenmesi
Daha önce de söylediğimiz gibi, çevremizdeki dünya hakkında bildiğimiz her şey uzun süreli hafızada saklanır. DP'deki malzeme sayesinde geçmiş olayları hatırlayabiliyor, sorunları çözebiliyor, görüntüleri tanıyabiliyor - kısacası düşünebiliyoruz. Bir kişinin bilişsel yeteneklerinin altında yatan tüm bilgiler DP'de saklanır.
DI1'in bazı yönlerinden önceki bölümlerde zaten bahsedilmişti. Soyut görüntü kodlarının DP'de saklandığını ve bu kodların giriş uyaranlarıyla karşılaştırılabileceğini ve bu uyaranların tanınmasını sağlayabileceğini biliyoruz. Bilginin çeşitli kurallar kullanılarak yapılandırılabileceğini gördük - imla kuralları, sayı serilerini yeniden kodlama kuralları, sözdizimi kuralları. Tüm bu kurallar DP'de saklanır. Ayrıca DP'nin kelimelerin ve gerçeklerin anlamlarını içerdiğinden emin olduk. Shifrin'in CP'den unutmaya ilişkin deneyleri (Shiffrin, 1973), DP'de saklanan aritmetik kuralları kullandı. Macbeth'i kim yazdı? Bu sorunun cevabı muhtemelen DP'nizde. John, Mary'den daha hızlı koşarsa ve Sally, John'dan daha hızlı koşarsa, o zaman en hızlı kim koşar? Bu soruyu yanıtlarken, DP'de saklanan bilgileri kullanırsınız. DP'de depolanan bilgi miktarı inanılmaz. Bazı teorisyenlere göre (örneğin, Penfield, 1959), bir kişinin DP'ye koyduğu her şey, sonsuza kadar onun içinde kalır. Bu durumda, uzun süreli hafızamız her türden büyük miktarda bilgi içerir.
DP'deki tüm bu bilgilerin "düzenlenmesi", miktarından daha az ilginç değildir. Bilgiler burada son derece düzenli bir şekilde saklanıyor gibi görünüyor. Gerçekler diğer gerçeklerle rastgele olmayan bir şekilde ilişkilidir; bir kelime diğerleriyle anlam olarak bağlantılıdır. Muhtemelen bu sıralı depolama sayesinde DP'den - örneğin "Macbeth"i kimin yazdığı hakkında - birkaç saniye içinde bilgi çıkarabiliyoruz. Ve her halükarda, bunu yapmak yıllar alacağından, "Macbeth"in yazarını DP'de rastgele aramıyoruz.
UZUN SÜRELİ BELLEĞİN YAPISI
Brown ve McNeill (Brown ve McNeill, 1966), sözde "hazır durum"un -bir kelime veya "dilin ucunda dönen" adı, ancak kişi tam olarak hatırlayamıyor. Bu deneyde deneklere kelimelerin tanımları sunuldu ve bu kelimeleri isimlendirmeleri istendi. Örneğin konuya "Japonya ve Çin'in limanlarında ve nehirlerinde kullanılan, kıçtan tek kürekle çekilen ve genellikle yelken açan küçük bir tekne" denildi. Brown ve McNeill, deneğin kelimeyi bildiğini hissedeceği ("dilin ucunda dönecek"), ancak basitçe hatırlayamayacağı bir hazır olma durumu yaratmak istediler. Tabii ki, birçok denemede bu olmadı - denek ya kelimeyi hemen hatırladı ya da onu hiç bilmediğini fark etti. Bu nedenle, hazır olma durumunu tespit etmek oldukça zordu, ancak yazarlar bunu oldukça sık yaratmayı başardılar (muhtemelen iyi bir tanım seçimi nedeniyle). Bu durum ortaya çıktığında, bir takım karakteristik özelliklere sahipti. Denek sadece kelimeyi bildiğini hissetmekle kalmıyor, bazen kelimenin kaç heceli olduğunu, hangi harfle başladığını veya hangi hecenin vurgulandığını bile söyleyebiliyordu. (Örneğin: "İki hecelidir, vurgu birincidedir ve "S" harfiyle başlar.) demiştir.) Anlamca birbirine yakın kelimeler. Öznenin kelimenin genel özelliklerini belirleyebildiği bu tür hatırlamaya türsel hatırlama denir.
Brown ve McNeill, ataların hatırlanmasıyla ilgili düşüncelerini özetleyerek, D11 yapısının bazı yönlerini açıkladılar. Onların görüşüne göre, şu veya bu kelime DP'de belirli bir yerde saklanır, burada hem işitsel hem de anlamsal bilgilerle temsil edilir. Bu nedenle, belirli bir kelimenin DP'den çıkarılması, onun sesine (örneğin, KÖPEK kelimesini söylüyorum ve siz bana bunun ne anlama geldiğini açıklıyorsunuz) veya anlamına (LU CHTTTI VE İNSANIN ARKADAŞI diyorum ve "köpek" diye cevap verirsiniz ) . Hazır olma durumunda, anlama göre tam bir çıkarma imkansızdır, ancak özne gerekli kelimeyi yine de kısmen çıkarır. Sesi hakkında bir fikri var ama belli ki tam akustik görüntüsüne sahip değil. Brown ve McNeil ayrıca, her kelimenin yanı sıra, diğer kelimelerle olan ilişkilerinin veya bağlantılarının DP'de saklandığına, böylece öznenin neredeyse aynı anlama gelen diğer kelimeleri adlandırabileceğine inanıyor. Bu nedenle, bu yazarlar DP'yi, her biri tek bir kelime veya gerçekle ilgili karmaşık bir bilgi seti içeren, birbirine bağlı çok sayıda bölüm olarak tanımlamaktadır.
DP'nin yapısı bu bölümün ana konusu olacaktır. Hazırlık durumu ile yapılan deneylerin sonuçları, DP'nin bilgi bağlantılarından oluşan bir ağ olarak tasvir edilebileceğini göstermektedir. Bu kavram, Bölüm 1'de tartışılan uyaran-tepki teorisi ile doğrudan ilişkilidir. • LTP'nin yapısının sonraki bazı modelleri de çağrışımlara dayanmaktadır (Anderson ve Bower, 1973; Quillian, 1969; Rumelhart, a.o., 1972); bununla birlikte, DP'nin yapısı hakkında başka fikirler de mümkündür, örneğin, DP'nin belirli bilgi kümelerinden (Meurer, 1970) veya önemli özellik gruplarından (Rips a.o., 1973; Smith a.o., 1974) oluştuğu kavram. ). Bu yaklaşımların her birinin kendi avantajları vardır ve bunları sırayla ele alacağız. DP yapısının her modeli, DP'de meydana gelen süreçlerin belirli açıklamalarıyla ilişkilidir - yapılandırılmış bilgilerin kullanılabileceği yollar.
DP modellerinin ayrıntılı incelemesine geçmeden önce birkaç açıklama yapılmalıdır. Her şeyden önce, modern DP modellerinin çok karmaşık olduğu akılda tutulmalıdır. Bu, DP'nin kendisinin karmaşıklığı tarafından belirlenir. Bunlardan bazılarından daha önce bahsetmiştik: ilk olarak, DP'de depolanan bilgilerin kullanımı problem çözme, mantıksal çıkarım, soruları yanıtlama, gerçekleri hatırlama ve diğer pek çok şeyle ilişkilidir; ikincisi, DP şaşırtıcı derecede geniş bir bilgi yelpazesi içerir; üçüncüsü, organizasyonu gelişigüzel değil, düzenlidir. Modern modellerin hiçbiri, DP'de saklanan bilgileri, miktarını ve organizasyonunu kullanmanın sayısız yolunu yeterince açıklayamaz. Ancak modeller, yeni ortaya çıkan verileri hesaba katmak için sürekli olarak değiştirilmektedir.
Başka bir açıklama da DP ile ilgili tüm karmaşıklıkları yansıtıyor: aslında, bir değil, iki DP hakkında konuşmak mantıklı. İki DP'nin varlığı fikri, anlamsal ve epizodik bellek arasında bir ayrım öneren Tulving (Tulving, 1972) tarafından ortaya atılmıştır. Her iki bellek de uzun süreli bilgi depoları olarak hizmet eder, ancak bu bilgilerin doğası gereği farklılık gösterir.
Konuşmayı kullanmak için ihtiyacımız olan her şey anlamsal bellekte saklanır. Sadece kelimeleri ve onları temsil eden sembolleri, anlamlarını ve göndergelerini (yani adlandırdıkları şeyleri) değil, aynı zamanda bunları ele alma kurallarını da içerir. Anlamsal bellek, gramer kuralları, kimyasal formüller, toplama ve çarpma kuralları, eksenin yazdan sonra geldiği bilgisi gibi şeyleri depolar - belirli bir zaman veya yerle ilgili olmayan, sadece gerçekler olan tüm bu gerçekler. Olaysal bellek ise belirli bir zamana göre kodlanmış bilgi ve olayları, belirli şeylerin nasıl göründüğüne ve onları ne zaman gördüğümüze ilişkin bilgileri içerir. Bu hafıza, "1970 kışında bir not kırdım" gibi her türlü otobiyografik veriyi saklar. Bağlama özgü bilgiler içerir: "Her gün akşam yemeği için balık pişirmem ama dün balık yedik."
Anlamsal ve epizodik bellekte depolanan malzeme, yalnızca doğası gereği değil, aynı zamanda unutmaya yatkınlığı bakımından da farklılık gösterir. Olaysal bellekte, bilgiye sürekli olarak yeni bilgiler eklendiği için bilgiye kolayca erişilemez hale gelebilir. Bir anıdan veya diğerinden bir şey alırken -örneğin, 3 ile 4'ü çarptığınızda (anlamsal belleği kullanarak) veya geçen yaz ne yaptığınızı hatırladığınızda (olaysal bellekten)- bu bilgi alma eyleminin kendisi bir olaydır. Bu nedenle, bu olay, 3'e 4 çarptığınızı veya geçen yazı hatırladığınızı gösterecek olan epizodik belleğe girmelidir. Bu nedenle, epizodik bellek sürekli bir değişim halindedir ve içerdiği bilgiler genellikle dönüştürülür veya erişilemez hale getirilir. Buna karşılık, semantik hafızanın çok daha az sıklıkla değişmesi muhtemeldir. Geri alma eyleminden etkilenmez ve içinde depolanan bilgiler genellikle yerinde kalır.
D11'in bu tür iki parçaya bölünmesiyle bağlantılı olarak, özellikle kelime listelerini kullanan deneylerin yardımıyla (Bölüm 1'de ele alındılar) insan hafızasını incelemenin geleneksel yöntemleriyle ilişkilerini kurmak özellikle önemlidir. Bu tür kelime listeleri şüphesiz olaysal bellekte sabitlenmiştir. Örneğin bir özneye "kurbağa" kelimesinin de içinde bulunduğu 20 kelimelik bir liste sunulursa, bu onun "kurbağa" kelimesini tekrar öğrendiği anlamına gelmez. Bu kelime, öznenin dil sürçmesini ezberlemeden önce anlamsal belleğinde bulunuyordu, şimdi onun içinde ve gelecekte de orada kalacak. Ancak denek, belirli bir zamanda kendisine sunulan listede "kurbağa" kelimesinin yer aldığını öğrendi - bu, belirli bir zamana ve belirli bir duruma bağlı bir gerçektir. Bu gerçek, epizodik hafızasında korunacaktır. Bu da, geleneksel psikolojik deneylerde semantik bellek yerine olaysal belleğin incelendiği anlamına gelir. Ebbinghaus'un zamanından beri semantik hafıza çalışması çok az ilgi gördü.
Semantik hafıza ancak son on yılda pek çok araştırmanın konusu haline geldi. Bu çalışmalar öncelikle çevremizdeki dünya hakkındaki semantik bilgimizin yapısal organizasyonu ve bu bilginin çeşitli görevlerin yerine getirilmesinde kullanılması ile ilgilidir. Bu bölümde, birkaç semantik bellek modeline bakacağız (bazı modellerde epizodik bellek de bulunur); şimdi DP'nin yapı ve işlevlerinin bu modellere göre açıklamasına dönüyoruz. Anlamsal bellek modelleri kabaca ağ, küme-kuramsal ve anlamsal özelliklere dayalı modeller olarak sınıflandırılabilir. Bu tür modeller tamamen ayırt edilemez; hepsi birbirine bağlıdır ve hepsi aynı insan yeteneklerini açıklamaya çalıştıkları için bu şaşırtıcı değildir. Ancak her türden modelin kendine has bazı özellikleri vardır; sonraki bölümlerde, her bir model türünün doğasını ve onunla ortaya çıkan bazı sorunları ele alacağız.
UZUN SÜRELİ BELLEĞİN AĞ MODELLERİ
Brown ve McNeill'in teorisi gibi anlamsal belleğin ağ modelleri, D11'i birbirine bağlı kavramlardan oluşan son derece geniş bir ağ olarak tanımlar. Ağ modelleri, belleği bir çağrışımlar demeti olarak gören "uyarıcı-tepki" kavramıyla belirli bir benzerliğe sahiptir. Bununla birlikte, bu modeller bazı açılardan geleneksel çağrışımcı kavramlardan önemli ölçüde farklıdır. Her şeyden önce, bu modellerin çoğu çeşitli çağrışımların oluşumuna izin verir, yani tüm çağrışımların aynı olmadığını kabul ederler. Bu, iki kavram ilişkilendirildiğinde aralarındaki ilişkinin bilindiği anlamına gelir; bir ilişki sadece bir bağlantıdan daha fazlasıdır. Bu yaklaşıma "neo-çağrışımcılık" adı verilmiştir (Anderson ve Bower, 1973). Böyle bir DP kavramı, çağrışımsal ağların mümkün olan en yüksek düzene ve yoğunluğa sahip olduğu fikrini de içerir. Kavramsal olarak birbirine yakın olan nesnelerin DP ağlarında yakından ilişkili olması beklenmelidir. Bu anlamda DP bir sözlük gibidir, ancak burada "sözcükler" alfabetik sırada değildir; Sıradan sözlüklerimizin üzerine inşa edildiği alfabetik ilke, kavramlar arasındaki bağlantıları açıklığa kavuşturmada çok az işe yarar. Örneğin, görece alışılmadık iki hayvanın, argali ve yak'ın adlarını ele alalım. Kavramsal olarak çok yakınlar, ancak sözlükte maksimum düzeyde ayrılıyorlar. DP'de muhtemelen sözlükte olduğundan daha yakından ilişkilidirler.
Ancak DP bu kadar düzenli bir ağ yapısıysa, şu soru sorulabilir: "düzenli" ne anlama geliyor? Bize bu ağın daha ayrıntılı bir tanımını vermenizi isteyebiliriz - bu, tam olarak ele alacağımız modellerin görevidir. Bu değerlendirmede, her şeyden önce kavramlar arasındaki bağlantıların dairesel olduğunu göreceğiz. Ne anlama geliyor? Sözlük örneğimize geri dönelim. Diyelim ki "müşteri" kelimesinin anlamını sözlükten öğrenmemiz gerekiyor. Bulacağız: "müşteri, isim-1. Normal müşteri veya müşteri. 2. Avukat gibi bir profesyonelin hizmetlerinden yararlanan kişi." "Müşteri" kelimesinin oldukça ayrıntılı bir tanımını aldık - bu bir isim, yani bir "şeyin" adı; birkaç anlamı vardır ve bize bu anlamlar anlatılmıştır. Ancak sözlüğün derlendiği dili bilmediğimizi ve bu nedenle "profesyonel" gibi bizim de bilmediğimiz başka kelimelerle verilen tanımın bize pek yardımcı olmayacağını varsayalım. Sözlükte "profesyonel" kelimesini aratıp "bu mesleğin sahibi olan kişi" olduğunu görebiliriz. Bize pek yardımcı olmayacak. "Avukat" kelimesine bakabilir ve özellikle şunu bulabiliriz: "...avukat, meslekteki tüm kişiler için geçerli olan genel bir terimdir; avukat ve avukat, müvekkilleriyle ilgilenen avukatlardır." Kısacası kafamız karıştı: "müvekkil", "avukat" ve "profesyonel" kelimeleri ile tanımlanır; "avukat", "meslek" ve "müvekkil" sözcükleriyle tanımlanır; "avukat" kelimesi aracılığıyla "profesyonel" vb. Çemberin tanımdaki anlamı budur. Sözcükler başka sözcüklerle tanımlanır. Ve göreceğimiz gibi, DP ağ teorileri, kavramların diğer kavramlarla ilişkileri yoluyla anlam kazandığını varsayar.
Modern DP modellerini tanımlamak için kullanılan dille ilgili son bir açıklama yapılmalıdır. DP özne, yüklem, isim vb. sözcükler kullanılarak tanımlandığından, bu terminolojinin doğrudan bir dilbilgisi ders kitabından alındığını düşünebilirsiniz. Burada sorun nedir? Biraz düşündükten sonra bunda bir tuhaflık olmadığını göreceğiz. Örneğin, "özne" ve "yüklem" terimlerini ele alalım. "Özne", belirli bir nesne, bir isim veya nominal bir ifade ile temsil edilebilen belirli bir kavramdır. "Yüklem", bize konu hakkında bir şeyler söyleyen bir kavramdır. Özne ve yüklem, şeylerin "şeyliği" ve yüklemi, aktüel ilişkilerin çeşitli yönlerine açıkça tekabül etmektedir. Bu itibarla, sadece dilbilgisel değil, aynı zamanda psikolojik bir gerçekliğe de sahiptirler ve muhtemelen DP'de birbirinden ayrılabilir öğeler olarak sunulurlar. Böylece gramer kavramları psikolojik bir gerçekliğe sahip olduğu ölçüde dilbilgisi terimleri içeren DP modelleriyle karşılaşacağız. Ek olarak, semantik DP'nin yapısının modern modellerinde, asıl vurgu, dil aracılığıyla aktarılan bilgiyi nasıl temsil ettiğidir. Bu nedenle, gramer terimleri DP'yi tanımlamak için özellikle uygundur. Dilin rolüne yapılan bu vurgu tamamen haklıdır, çünkü bir insanı diğer canlılardan ayıran konuşmanın olağanüstü gelişimidir. Hafızamızın muazzam kapasitesini belirleyenin bu dilsel yetenekler olması bile mümkündür. Tüm bu nedenlerden dolayı, dilin yapısı DP'nin tanımlarının merkezinde yer alır.
QUILLIAN MODELİ
Dilin ve ilişkisel ağların önemli bir rol oynadığı birkaç uzun süreli bellek modeli vardır. Bunlardan ilki olan "Dil Anlama Öğrenilebilir Sistemi" (LTSL) 1 , Quillian tarafından önerilmiştir (Quillian, 1969; Collins ve Quilliap, 1969). Bu model şu şekilde uygulanır:
bir kişinin dili doğal bir şekilde anlama ve kullanma yeteneğini taklit etmeye çalışan bir makine programı. Temel olarak, bir bilgisayara konuşmayı öğretme girişimidir. Aslında Quillian modeli burada sunulandan çok daha kapsamlıdır çünkü DP'nin açıklaması bu modelin yalnızca bir yönüdür. DP'nin yapısı, bu yapıya etki eden süreçler ve bu konuyla ilgili deneysel verilerle ilgili modelde yer alan varsayımları dikkate almakla yetiniyoruz.
} Orijinali (TLC). — Yaklaşık. isim - Öğretilebilir Dil Anlayıcısı
Önce Quillian modeline göre DP'nin yapısını ele alalım. Gerçek bilgiler bu modelde üç tür yapıyla temsil edilir - öğeler, özellikler ve oklar. Öğeler ve özellikler, Brown ve McNeil'in anladığı anlamda DP'deki belirli "yerlerdir", yani belirli kavramlar hakkındaki bilgilere karşılık gelen bölümlerdir. Öğeler ve özellikler arasındaki fark, farklı kavram türlerini temsil etmeleridir. Öğe, bir nesneye, olaya veya fikre karşılık gelen bir yapıdır; bunlar İngilizce'de bir isim, isim tamlaması veya yeterince karmaşıksa bütün bir cümle ile temsil edilen şeylerdir. Temelde bir öğe, "şey" dediğimiz şeydir (öğe örnekleri "köpek", "Amerika", "baba", "iyi hava", "iyi vibrafon" vb. kavramlarıdır). Özellik, bize bir öğe hakkında bir şeyler söyleyen bir yapıdır; gramer olarak, cümledeki yükleme veya sıfat, zarf vb. karşılık gelir. ve. (örnekler: "sıkı", "zarif", "hızlı", "kedileri sever"). Unutulmamalıdır ki, burada örnek olarak sözcükleri kullansak da, öğeler ve özellikler aslında sözcüklerden daha soyut yapılardır. Bunlar, kelimelerin kendilerine değil, belirli kelimelere karşılık gelen DP'de yapılan girişlerdir. Bununla birlikte, kelimeyi kullanmak, DP'de depolanan belirli öğeleri veya özellikleri adlandırmanın uygun bir yoludur.
Okların, öğeler ve özelliklerle birlikte nasıl bir DP'nin yapısını oluşturduğunu anlamak için, Şekil 1'e başvurmak yararlıdır. 8.1, "müşteri" kelimesiyle ifade edilen tek bir kavram-kavrama karşılık gelen bir yapıyı gösterir (bu nedenle, burada DP'nin yalnızca küçük bir bölümü gösterilmektedir). Bu şemadan da görülebileceği gibi, "client" kelimesi DP'nin ağ yapısının dışındadır; "zihinsel sözlükte" bu ağın dışında yer alır. Ancak, ağda "istemci" kelimesine karşılık gelen konumu (yani öğeyi) belirtir. Zihinsel sözlükte "müşteri" kelimesinin çağrışımı,
ve "müşteri" öğesi ok olarak adlandırılır. Özünde, oklar SIEA sistemindeki ilişkilendirmelerdir. Sözlük etiketlerini DP'de depolanan kavramlarla ilişkilendirmenize ve ayrıca DI1 ağındaki öğeleri ve özellikleri birbirine bağlamanıza olanak tanırlar. Böylece, bu unsurları ve özellikleri tanımlamaya hizmet ederler; aslında tanımlar çağrışım komplekslerine karşılık gelir.

Pirinç. 8.1. 4N#H¥* {Qnsllian, £969) kavramına karşılık gelen, OSJA'nın belleğinde yer alan ve depolanan bilgiler .
SIDS modeline göre, elemanların doğası ve özellikleri az sayıda kural kullanılarak tanımlanabilir. Bir öğe oluşturabileceğiniz kuralları göz önünde bulundurun (Şekil 8.1). Herhangi bir öğe, sıralı bir ok grubundan oluşur. Belirli bir öğenin ilk oku, başka bir öğeyi, yani birincinin hemen üstündeki öğeyi göstermelidir. (Örneğin, "müşteri" kavramına karşılık gelen öğede, "kişi" kavramı "müşteri" kavramını içerdiğinden, ilk ok "kişi" öğesini yönlendirir. Özünde bu bir sınıftır ("kişiler") ), "clients" sınıfının bir adım yukarısında "clients" sınıfını içeren en yakın üst sıradaki sınıftır.) Bu öğenin üzerindeki okların geri kalanı özelliklere götürür. Bu tür okların sayısı sınırlı değildir. Ancak bu örnekte, "bir profesyonel kullanır" olarak tanımlanan özelliğe götüren yalnızca bir ok gösteriyoruz.
Özellikleri anlamak için, CVL modelinde oluşturuldukları kurallara aşina olmanız gerekir. Öğeler gibi, özellikler de sıralı ok gruplarından oluşur. Birazdan göreceğimiz gibi, ilk iki ok kesinlikle gereklidir. Nereye yönlendirildiklerini anlamak için öncelikle genel olarak özelliklerin doğasını ele almalıyız. "Beyazdır" gibi herhangi bir öğeyi karakterize edebilecek bazı tipik özellikleri ele alalım. Bu özellik, belirli bir özniteliği ifade eder - bu özellikle karakterize edilen öğe, bir renk özelliğine sahiptir ve bu durumda bu özelliğin değeri "beyaz" dır. Genel olarak bir özellik, belirli bir nitelik artı bu özelliğin belirli bir değeri olarak düşünülebilir. Bir sıfatla ifade edilmeyen başka bir şey olabilir ("beyaz" gibi); "tepede" gibi bir yer zarfı olabilir. Burada "on" bir niteliktir ve "tepe" bu özelliğin değeridir. Başka bir özellik türü daha çok "top atar" gibi bir yüklem gibi olabilir. Bu nedenle, "öznitelik-değer" formu oldukça geneldir ve hemen hemen her türden özelliği içerebilir.
Şimdi mülk oluşturma kurallarına geri dönelim. İki zorunlu "ok" içermeleri gerektiğini daha önce söylemiştik. Bunlardan ilkinin bazı öznitelikleri, ikincisi ise bu niteliğin amacını gösterdiği açıktır. Müşterinin özelliğini tanımlayan ilk ok" (Şek. 8.1), "hizmetleri kullanır" (öznitelik) ve ikincisi "profesyonel" (değer) anlamına gelir. Bu şekilde, müşterilerin mülkiyetinin profesyonellerin hizmetlerini kullanmak olduğunu öğreniyoruz. Özniteliğe ve değerine karşılık gelen bu iki gerekli oka ek olarak, bir özellik, diğer özelliklere götüren herhangi bir sayıda ok içerebilir. Düşündüğümüz mülkte şu ekstra ok var; "müşteri" özelliğine işaret eder (bu durumda şu soruyu yanıtlayan bir özellik: bir profesyonelin hizmetlerini kim kullanır?). Böylece, müşterinin bir profesyonelin hizmetlerini kullanan bir kişi olduğu ortaya çıkıyor; profesyonel müşteri (kim?) tarafından kullanılır. Yukarıdaki diyagramı tüm bu kitabın boyutuna genişletmek zor olmayacaktır. "Yüz" öğesinin özelliklerini ve bu öğelerin özelliklerini ve "yüz" kavramının tanımında yer alan özellikleri görüntüleyebiliriz. Bu tanım, örneğin, "canlı varlık" öğesini içerebilir; bu yeni öğeyi ve işaret ettikleri tüm nesneleri tanımlamak için gerekli olacak tüm okları hayal edin. Sonuç, birbirine bağlı devasa bir kavramlar dizisi olacaktır - bu, OSS sisteminin hafızasıdır.
Dolayısıyla, tüm bunlar devasa bir kavramlar ağının yaratılmasına yol açar. Öğeler ve özellikler olmak üzere iki türde gelirler ve aralarındaki ilişkiler onlara anlam verir. Öğeler diğer öğeler ve özellikler tarafından, özellikler diğer özellikler ve öğeler tarafından tanımlanır. Ayrıca (SILS modelinde bu özellikle vurgulanmasa da) kavramların duyu organları aracılığıyla dış dünyayla olan bağlantılarıyla da tanımlanmaları gerektiğine dikkat edilmelidir. DP kendi içinde tamamen kapatılamaz. Örneğin, hepsini gördüğümüze dair bir anımız yoksa, hastane, vadideki zambaklar, çarşaflar vb. Bu nedenle, nihai olarak, uzun süreli belleğin modelleri, yalnızca iç kısımları arasındaki ilişkileri değil, aynı zamanda dış dünya ile etkileşimini de açıklamalıdır. Kavramları diğer kavramlarla ilişkileri yoluyla tanımlayan iç ilişkileri, DP'ye açıklayıcı bir sözlüğe büyük bir benzerlik verir. Gördüğümüz gibi bu tür sözlüklerde kelimelerin tanımları başka kelimeler yardımıyla verilir ve bu diğer kelimeleri aramaya başlarsak onların da kelimeler yardımıyla tanımlandığını görürüz. Sözlükteki her kelime, yalnızca açıklanmakta olan kelimeler ile kelimelerin görsel duyusal deneyimle ilişkilendirilmesine izin veren oldukça nadir resimler arasındaki karmaşık ilişkiler nedeniyle anlamlıdır.
Quillian'ın DP modelinin geniş bir çağrışımsal ağın resmini sağladığını öne sürebiliriz. Burada kavramlar ilişkilendirilir - örneğin, "müşteri" veya "renk sahibi olmak" veya "şu veya bu şekilde hareket etmek" gibi. Kavramlar, temelde çağrışımları gösteren oklarla birbirine bağlanır. Bu ilişkilendirmeler, geleneksel uyaran-tepki ilişkilendirmelerinden, birkaç farklı türde gelmeleri bakımından farklılık gösterir: hiyerarşik ilişkilendirmeler, özellikler, nitelikler ve değerleri aracılığıyla ilişkilendirmeler. DP'nin, etiketli ilişkilerle birbirine bağlanan bir dizi hücre olarak tasvir edilmesi, DP ağ modellerinin ana özelliğidir.
ANDERSON VE BOWER MODELİ
Quillian'ın modeli, uzun süreli belleği, belirli bir kişinin etrafındaki dünya hakkında bildiği her şeyi içeren bir ağ olarak tasvir eden ilk modellerden biriydi ve bir bilgisayar için ayrıntılı bir program oluşturarak insan dilini taklit etmeye çalıştı. Daha sonra, her birinin kendine has özellikleri olan başka ağ modelleri ortaya çıktı. Ağın anlaşılmasını genişletmek için, Anderson ve Bower (Anderson ve Bower, 1973) tarafından oluşturulan ve HAP, yani "İnsan İlişkisel Bellek" (HAM - İnsan İlişkisel Bellek) olarak adlandırılan bu türden başka bir modeli ele almakta fayda var. 1 .
1 Rumelhart, Lindsay ve Norman (Rumelhart a.o., 1972) tarafından geliştirilen benzer bir model, Lindsay ve Norman'da (Lindsay ve Norman, 1972) ayrıntılı olarak tartışılmaktadır. Bu kitap, ağ modelleriyle ilgilenenlere ek okuma için önerilebilir.
AFC modeli, Quillian'ın OSTIA'sı ile genel benzerlikler paylaşsa da, uzun süreli belleğin sözde ayrıntılı yapısında büyük farklılıklar gösterir. Tabii ki, bir ağ modeli olarak AFC, uzun süreli belleği geniş bir hücre koleksiyonu ve etiketli çağrışımlar olarak tanımlar. Bununla birlikte, AFC'nin ana bileşenine - DP'nin "molekülüne" - ifade denir. Bu ifadeler, daha soyut olmaları farkıyla cümlelere benzer. Başka bir deyişle, ifade, cümle gibi bir tür dilsel yapıyı temsil edebilir, ancak cümlenin kendisi değildir. (Sözler sadece dil bilgisinden daha fazlasını temsil edebilir; ayrıca DP'de dilsel olmayan bilgileri de temsil edebilirler. Örneğin, Anderson ve Bower'a göre, görsel sahnelerin açıklamaları DP'de ifadelerle temsil edilebilir.)
Genellikle bir ifade, küçük bir ilişkiler ve hücreler grubudur (tıpkı OCTI modelindeki bir birimin küçük bir öğeler ve özellikler kümesi olması gibi). Her ilişkilendirme ikilidir; bu, içinde iki kavramın bağlantılı veya ilişkili olduğu anlamına gelir.
Dernekler birkaç türdendir. Dernek türleri ve ifadeleri oluştururken bağlantı yöntemleri Şek. 8.2. Her biri iki basit fikri birleştiren dört ana çağrışım türü dikkate alınmalıdır.

Bazı bağlamları belirli bir gerçeğe bağlayan bir ilişkilendirme. Bağlam, olgunun nerede ve ne zaman gerçekleştiğini söyler ve olgu, verilen bağlamda ne olduğu hakkında bilgi taşır.
Yer ve zamanı birbirine bağlayan bir ilişki; bu kombinasyon belirli bir bağlam oluşturur. Yer bize nerede olduğunu ve zaman bize ne zaman olduğunu söyler.
Özne ile yüklemi birbirine bağlayan bir ilişki. Böyle bir kombinasyon belirli bir gerçeği oluşturur. Özne bize gerçeğin neye atıfta bulunduğunu söyler ve yüklem bize özneye ne olduğunu söyler.
Yüklemin kendisi iki bölümden oluşan bir ilişki olabilir: yüklem bize genellikle özne ile bir nesne arasındaki ilişkiyi anlatır. Bu nedenle, yüklemin bir tür ilişkiyi ("daha yüksektir", "vurmak" veya "şunun ve bunun babasıdır" gibi fiil benzeri bir biçim) ve nesnesini birbirine bağladığını söyleyebiliriz.
Uygun kombinasyonlarda, bu dört tür çağrışım (bağlam - olgu, yer - zaman, özne - yüklem, ilişki - nesne) bir ifade oluşturur. Bir ifade en iyi şekilde, farklı kavramların bir ifadede nasıl birleştirilebileceğini gösteren bir dallanma diyagramı olan bir ağaçla gösterilir. Şek. 8.2 böyle bir ifade ağacını gösterir. "Sınıfta, öğretmen Bill'e sordu." Ağacın tepesindeki A harfi, bir bütün olarak verilen ifadeye karşılık gelen kavramı ifade eder. A noktasına ve iki ilişkili öğenin bağlandığı diğer tüm noktalara "düğüm" adı verilir. İfade düğümü, bağlam ve olgu arasındaki ikili (binary) ilişkinin sonucudur. İkincisi, şemanın bir sonraki seviyesinde sunulur. Daha aşağıda, bağlam düğümünün (B) belirli bir yer (D, sınıfta) ile bir zaman (E, geçmişte, çünkü öğretmen Bill'e sormuştu) arasındaki bir ilişki olduğunu görüyoruz. Olgu düğümü (C), diğerleri gibi, özne (F) ve fiil (G) olmak üzere iki kısma ayrılabilir. Ancak yüklem düğümü ayrıca iki bölümden oluşur: bir ilişkiyi (H, "sormak" fiili) ve bir nesneyi (I, "Bill") ilişkilendirir.
Bu ifadenin yapısıdır. Bazı bağlamlardan ve bazı olgulardan oluşur (ancak bazen, örneğin "Fareler peynir yer" gibi ifadelerde bağlam olmayabilir). Bağlam (eğer varsa), yer ve zamandan oluşur. Bir gerçek, bir özne artı bir yüklemdir ve bir yüklem, bir ilişki artı bir nesnedir. Planın alt satırında, daha fazla ayrışmaya uygun olmayan birimler var. Bunlara "terminal düğümler" denir (terminal - çünkü dallanma burada sona erer). Bu düğümler, burada sözcüklerle temsil edilen DP'nin temel kavramlarına karşılık gelir (tıpkı CASN modelinde birimleri ve özellikleri sözcüklerle temsil edebildiğimiz gibi). Sözceyi DP'ye "iliştirmeye" hizmet ederler; bunlar, herhangi bir sayıda ağacın bağlanabileceği sabit noktalardır. Böylece, DP'nin farklı hücreleri (ağaçların terminal düğümlerine karşılık gelen) ilişkilendirmeye hizmet eden bu tür ağaçlardan (ifadelerden) oluşan bir ağ gibi olduğunu görüyoruz.
MODELLERDE GERÇEKLEŞEN İŞLEMLER
Artık ağ modellerinde DP'nin ilişkilendirme tabanlı bir yapıya sahip olduğunu biliyoruz. Ama bu hikayenin sadece bir parçası. Bu modeller, diğer herhangi bir DP modeli gibi, her şey tek bir yapıya indirgenirse çok az şey başaracaktır. İnsan davranışını taklit etmek veya (biraz sonra tartışılacak olan) anlamsal bellek deneylerinin sonuçlarını tahmin etmek için modelin süreçleri de temsil etmesi gerekir. Süreçler yapı üzerinde hareket eder ve onunla birlikte bilgilerin kodlanması, saklanması ve alınmasına katılır.
Örneğin, Quillian modeli söz konusu olduğunda, NOSJ'nin yeni bilgileri nasıl edindiğini, yani dilsel girdileri nasıl yorumladığını (ki bu, yeni bilgiler elde etmek için gereklidir) ve soruları nasıl yanıtladığını açıklamak gerekir. Bu amaçla kullanılan en önemli işleme "kavşak arama" denir. Diyelim ki ÖYD şu cümleyi girdi olarak anlamaya çalışıyor: "Kurt ısırır." Bu cümlede bazı kavramlar ("kurt" ve "ısırık") adlandırılmıştır. Arama işlemi, adlandırılmış kavramların her biri için aynı anda DP hücrelerine girer ve ardından okları, yani bu hücrelerden ayrılan yolları takip eder. Herhangi bir ok ne zaman yeni bir kavrama yönlendiriyorsa, o kavram bir etiket alır, bu da
arama sürecinin bu noktadan geçtiğini ve hangi kavramdan buraya geldiğini gösterir. Bir noktada, arama yollarından birinin zaten etiketlenmiş bir konsepte yol açması mümkündür (yani, arama zaten ona daha önce yol açmıştır). Bu nokta bir kavşağı temsil eder. Bir kesişme bulunursa, bu noktaya iki farklı kavramdan arama yapılarak ulaşılabileceği ve dolayısıyla bu iki kavramın bir şekilde ilişkili olduğu anlamına gelir. Belirli bir noktada bir etiket olup olmadığı kontrol edilerek ve kesişime giden yolu ters yönde takip ederek, hangi kavramların kesiştiği ve birbiriyle nasıl ilişkili olduğu tam olarak tespit edilebilir. D11'deki kavramlar arasındaki ilişki giriş cümlesindeki ilişki ile uyumlu ise bu cümle anlaşılmıştır diyebiliriz.
OSSY modelinde kesişime göre arama, Şekil 1'de gösterilmektedir. 8.3. Bazı hayvanlar ve özellikleri hakkında kavramlar içeren DP'nin ağ yapısının bir bölümünü (tüm elementlerin ve özelliklerin bir göstergesi ile Şekil 8.1'dekinden biraz daha net) gösterir. Diyelim ki "Kanarya balıktır" cümlesini SPIE'ye soktuk. Arama işlemi "kanarya" ve "balık" unsurlarına karşılık gelen noktalarda başlayacaktır. "Kanarya" yolunda "kuş", "ötücü" ve "sarı" kavramları işaretlenecek; "balık" yolunda - "palet", "yüzmek" ve "hayvan" kavramları. Son olarak, "kanarya" araması "hayvan" terimine ulaştığında, orada "balık" teriminden burayı gösteren bir ok bulunan bir etiket bulunacaktır. "Hayvan"a giden yolları ters istikamette takip ederek "balık" ve "kanarya" kavramları arasındaki ilişki ortaya çıkarılabilir. "Kanarya balıktır" demeleri tavırlarıyla tutarsız. Ancak bu ifade "kanaryanın balıkla akraba olduğunu" söylüyorsa, bu doğrulanmış olur. Benzer şekilde, arama sonuçları "bir kanaryanın derisi olduğunu" doğrulayabilir ("kanarya"dan "kuş"a, "kuş"tan "hayvana" ve "hayvan"dan "deriye" giden bir yol bulunabilir) veya şuna yol açabilir: "kanarya uçabilir" ("kanarya kuştur" ve "kuş uçabilir") sonucu.

Teşekkür ederim. JE OSLJ belleğinin ortasındaki hiyerarşik sistemin parçası; ^aieisugnoiieliya'da k birimleri ile "hayvanlar" sınıfı
içindeki özellikler arasında
gösterilir . (Coilijıs a. QuiUian, 1969).
APJ modelinde, CASN'deki !'nin kesişmesine karşılık gelen işleme "eşleştirme" işlemi denir. Şek. 8.4. Bu süreç, girdi bilgisini hafıza ile ilişkilendirmeyi amaçlar, bunun sonucunda model bu bilgiyi yorumlayabilir. İlk olarak, AFC sistemi, giriş mesajını "ayrıştırma" adı verilen bir kodlama işlemi olan bir ağaç biçiminde sunarak giriş bilgisini (örneğin herhangi bir cümle) kodlamaya çalışır. O zamanlar
devrenin terminalini - en alttaki - DP'deki karşılık gelen hücrelerle eşler. (Giriş mesajında yabancı bir kelime belirirse, DP'nin belirli bir hücresi ile karşılaştırılamaz; daha sonra DP'de bu kelimeyi temsil eden yeni bir düğüm oluşturulur ve bu düğüm hakkında bilgi toplama başlar: ne bu kelimenin yazılışı, cümlede hangi kelimelerle nasıl ilişkilendirildiğidir.) Daha sonra DP'de girdi ağacına benzer bir ağaç bulunmaya çalışılır. Böyle bir arama, giriş cümlesindeki kelimelerden birine karşılık gelen her bir DP hücresinden başlar; DP ağında terminal düğümlerini giriş mesajında bağlandıkları şekilde bağlayan yollar için yapılan bir aramadır. Diğer bir deyişle, giriş mesajındaki ile aynı kavramları ve aynı şekilde birbirine bağlayacak böyle bir DP ağacının bulunması gerekmektedir. Böyle bir ağaç bulunduğunda, giriş mesajı ile DP ağı arasındaki yazışmanın kurulduğu ve cümlenin anlaşıldığı anlamına gelir.

Aynı süreç, sorular gibi birçok farklı girdi türü için kullanılabilir. "Bill'i kim vurdu?" sorusu verildiğinde, sistem soruyu ayrıştıracak ve "kim" zamirinin doldurulacak bir boşluk olarak değerlendirileceği bir girdi ağacı oluşturacaktır. Ağacın geri kalanını hafızadaki bilgilerle eşleştirmeye çalışacaktır. Hafızada "Bill John tarafından vuruldu" bilgisi varsa, sistem boşluğu doldurabilecek ve soruyu cevaplayabilecektir. (Bu örnek biraz önemsizdir, ancak açıklanan yöntem daha karmaşık soru-cevap durumlarına genişletilebilir.) AFC modelindeki eşleştirme yönteminin bir diğer önemli özelliği de "görsel" gibi dilsel olmayan girdilere genişletilebilmesidir. " (sahneler). AFC sistemindeki bazı işlemler, bu girdilerin ne olduğunu bulmak için ağaçlar oluşturarak bu girdileri ayrıştırmak veya tanımlamak için tasarlanmıştır. Bu girişle, sistemin sunulan resmi tanıyabilmesinin bir sonucu olarak bellekte bulunan açıklamaları karşılaştırmak mümkündür. Kısacası, mevcut deneyimin çevreleyen dünya hakkında daha önce edinilmiş bilgilerle ilişkilendirilebileceği ana mekanizma olduğu ve bu nedenle bilgi kodlama ve geri almada önemli bir rol oynadığı için yan yana koyma sürecinin birçok işlevi vardır.
SEMANTİK HAFIZA VERİLERİ
Artık bir tür DP modeline (yani ağ modellerine) aşina olduğumuza göre, bu modellerin açıklamak için yaratıldığı bazı verileri dikkate almak uygun olacaktır. Bu bölümde anlamsal bellekle ilgili verilere bakacağız (epizodik belleğe daha sonraki bölümlerde değineceğiz). HORN, AFC ve diğer modellerin açıklama gücünü, bilinen gerçekleri anlamamıza ne ölçüde izin verdiklerini gördüğümüzde takdir edebileceğiz.
Kural olarak, anlamsal bellek çalışılırken, "epizodik olmayan" bilgi, yani edinildiği zaman veya yerden bağımsız olarak var olan bilgi ele alınır. Bu tür bilgilere verilebilecek en güzel örneklerden biri kelime tanımlarıdır. Hemen hemen herkes "kanaryanın kuş olduğunu" ve "tüm elmasların taş olduğunu" bilir. Bu nedenle, kelime tanımlarının semantik bellek üzerine yapılan birçok deneyde kullanılmış olması şaşırtıcı değildir. Bu tür deneylerde kullanılan en yaygın yöntemlerden biri, bir ifadenin doğruluğunu test etme görevidir. Özneye bir ifade sunulur ve bunun doğru mu yanlış mı olduğuna karar vermesi istenir; örneğin: KANARYA - KUŞ 1 (doğru) veya KANARYA - BALIK (yanlış). Beklendiği gibi, denekler bu tür görevleri çok az sayıda hatayla gerçekleştiriyor. Bu tür görevlerde bağımlı değişken, genellikle bir ifadenin sunumu ile öznenin yanıtı arasındaki süre olarak tanımlanan tepki süresidir (RT).
Kesin konuşmak gerekirse, "bir kanarya belirli bir kuştur" yazılmalıdır, ancak bu bağlamda, günlük konuşmayı anlama mekanizması sorununun tartışıldığı yerde, bu tür ifadeleri günlük dile özgü basitleştirilmiş bir biçimde çevireceğiz. — Yaklaşık. ed.
SINIF DEĞERİNİN ETKİSİ
Semantik belleğin tüm fenomenleri arasında, muhtemelen araştırmacıların en çok ilgisini çeken, sözde sınıf büyüklüğü etkisidir. Tipik bir durumda, bu etkiyi incelemek için, şu şekle sahip bir ifadenin doğruluğunu kontrol etmek için bir problem kullanılır:
(Bazı konu) (S) (Bazı yüklem) (P)'dir.
Bağımsız değişken, R yüklemi sınıfının boyutudur. Sınıfın boyutu, üyelerinin sayısı anlamına gelir. Belirli bir sınıftaki üye sayısını tam olarak belirtmek çoğu zaman mümkün değildir (ancak bazen, örneğin dört üyeli "mevsimler" sınıfı durumunda, sayı oldukça açıktır). Bununla birlikte, bir sınıfın göreli büyüklüğünü belirlemek, yani bir sınıfın diğerinden daha büyük olduğunu söylemek her zaman mümkündür. Genellikle bir sınıfın başka bir sınıfa dahil olduğu durumlarda bundan bahsedebilirsiniz; o zaman, elbette, ikinci birinciden daha büyük olmalıdır. Örneğin, "kuşlar" sınıfı, "hayvanlar" sınıfına dahildir; bu nedenle, "hayvanlar" sınıfı tüm "kuşları" ve diğer her şeyi içerir, bu nedenle daha büyük olmalıdır. İfadelerin doğruluğunu test etmek için yapılan deneylerin ana sonucu, "doğru" yanıtını vermek için gereken VR'nin P sınıfının boyutunun artmasıyla artmasıdır. Örneğin, "kanarya hayvanı" ifadesini kontrol etmek, ifadeyi kontrol etmekten daha fazla zaman alır. "kanarya kuşu" (bkz. örneğin, Collins ve Quillian, 1969; Meyer, 1970). Yanlış iddialar için VR de genellikle P sınıfı ile artar (örneğin bkz. Landauer ve Freedman, 1968; Meyer, 1970).
Sınıf büyüklüğü etkisi, anlamsal bir bellek modeli oluşturmak için son derece önemlidir. Özü, belirli bir nesnenin (örneğin bir kanarya) belirli bir sınıfa ("kuşlar") ait olup olmadığını kontrol etmek için gereken sürenin bu sınıfın boyutuna bağlı olduğu gerçeğine dayanır. Ve bu da semantik DP'nin doğası hakkında bir şeyler söylüyor, bu nedenle herhangi bir makul model, sınıf büyüklüğünün etkisini hesaba katmalıdır. Quillian'ın modeli söz konusu olduğunda, ona oldukça makul bir açıklama yapmak zor değil. Bu modelde, verilen nesnenin hemen üzerindeki en yüksek sınıfla bir okla ilişkilendirildiği varsayılır; bu üst sınıf, bir üst sınıfla ilişkilidir ve bu böyle devam eder. Bu, bu modeldeki DP'nin iç yapısıdır. "Kanarya - kuş" ifadesinin doğruluğunu test etmek için sadece bir oktan geçmeniz ve üst sınıflardan daha uzağa gitmek için zaten bu tür iki oktan geçmeniz gerekir (bkz. Şekil 8.3). . Oku takip etmek zaman aldığı için iki oka karşılık gelen yol daha uzun sürecektir. Sonuç olarak, sınıfın boyutunun etkisini elde edeceğiz: bu P sınıfının hiyerarşideki konumu ne kadar yüksekse, o kadar çok ok geçmeniz gerekir ve o kadar fazla zaman alır.
SIOS modelini kullanarak, yanlış ifadeleri test ederken (örneğin, "papatya bir balıktır" gibi) neden sınıf büyüklüğünün etkisinin de gözlemlendiğini açıklamak biraz daha zordur. Gerçekten de, örneğin yukarıdaki ifadede "balık" kavramı "hayvan" ile değiştirilirse, VR daha büyük olacaktır. Collins ve Quillian (Collins ve Quillian, 1970) aşağıdaki açıklamayı yaptılar. Onların görüşüne göre, çoğu durumda sınıf büyüklüğünün etkisi görünmüyor. Yalnızca S ve P bağlandığında oluşur (örneğin, papatyalar, balıklar ve hayvanlar yaşayan organizmalardır). Ve eğer S ve P ilişkiliyse, o zaman P küçük bir sınıf yerine büyük bir sınıf olduğunda genellikle daha yakından ilişkili olacaktır. Örneğin, Şekil l'den görülebileceği gibi. 8.3, "papatya" (hiyerarşik sistemde yakınlık açısından) "hayvan"a "balık"tan daha yakın olacaktır. Ayrıca 5 ve P birbirine yakınsa arama sırasında hatalar oluşabilir. Arama, uygun olmayan bir tutumu ortaya çıkarabilir. P sınıfı ne kadar büyükse, ilişki o kadar yakındır, burada hata yapmak o kadar kolay olur ve verilen iki kavramın yakınlığına rağmen ifadenin yanlış olduğuna karar vermek o kadar uzun sürer. Bununla birlikte, böyle bir açıklama, yanlış ifadeler kontrol edilirken, sınıf mevcudunun etkisinin, söz konusu iki kavramın benzerlik derecesi aynı olsa bile ortaya çıktığı gösterildiğinden (Landauer ve Meyer, 1972) yeterli kabul edilemez. her durumda. Diğer modeller gözlemlenen etkiyi kolayca açıklayabilirse, ancak onlar da bir açıklama sağlamazsa, özellikle OSOS modeli için talihsizlik olur! Yanlış iddiaları test etmede sınıf büyüklüğünün etkisi birçok model için sorunludur. Bu nedenle, şimdilik, Collins ve Quillian tarafından ifade edilen fikrin, genel olarak VR'nin sınıf mevcuduna bağımlılığının bir açıklaması olarak hizmet edebileceği konusunda hemfikir olacağız.
SEMANTİK YAKINLIĞIN ETKİLERİ
Yukarıda yanlış ifadeleri test etmede sınıf boyutu etkilerinin olası bir nedeni olarak bahsedilen yakınlık, özellikle doğru ifade deneylerinde anlamsal bellekle ilgili önemli bir araştırma konusudur. Bu "yakınlık" ile ilgili tipik çalışmalarda, deneklere önce bir dizi kelime çifti sunulur. Her çiftte, bir sözcük bu sınıfa ait bir nesnenin adı, diğeri ise bu sınıfın adıdır; örneğin, nesne (sınıf temsilcisi) "robin" olabilir ve sınıf "kuşlar" olabilir. Denekten, belirli bir temsilcinin belirli bir sınıf için ne kadar tipik olduğunu veya karşılık gelen iki kelimenin ne kadar yakın olduğunu değerlendirmesi istenir (Rips a. o., 1973; Rosch, 1973). Belirli bir sınıf için çeşitli temsilcilerin tipikliğine ilişkin tahminler oldukça büyük farklılıklar gösterir. Örneğin, "robin", "tavuk"tan çok daha tipik bir "kuş" olarak derecelendirilir. Tipiklik tahminlerindeki bu farklılıklar, semantik bellek teorisinin açıklaması gereken gerçeklerden biridir.
Aslında, "tipiklik", OSTIA gibi bir ağ modeli için büyük bir sorun olarak ortaya çıkıyor. Bu modelde, bir sınıfın her üyesi, doğrudan üstündeki sınıftan tek bir okla ayrılır. Belirli bir sınıfın tüm üyeleri, sınıf adından aynı mesafeyle (bir oka eşit) ayrıldığından, tipiklik tahminlerinde neden farklılıklar olduğunu hayal etmek zordur. Anderson ve Bower tarafından geliştirilen AFC modeli, göreceğimiz gibi ağ modellerine pek uymayan bu ve diğer etkiler için daha iyi bir açıklama sağlar. Bu durumda, AFC modeli, DP'de gerçekleşen arama (karşılaştırma) sürecinin bir sonucu olarak tipiklik veya yakınlık olgusunu açıklayabilir. Hatırlayacağınız gibi, eşleştirme işleminin başlangıç noktası, giriş mesajında belirtilen her bir DP hücresinden başlayan bir aramadır; Bu sürecin amacı, giriş mesajıyla eşleşen bir ağaç bulmaktır. Arama aynı anda farklı hücrelerden başlar ve paralel olarak yürütülür; ancak her bir hücreden aynı anda yalnızca bir yol aranabilir. Ve genellikle DP'nin her hücresinden birçok yol olduğu için, aralarında belirli bir düzenin kurulduğu varsayılır; verilen hücreden farklı yollarda aramanın gerçekleştirildiği sırayı tanımlar. Önce en önemli yollar incelenir. Bu, AFC modelinin "tipikliğin" gerçek reaksiyon süresi üzerindeki etkisini hesaba katmasına izin verir, çünkü tipiklik ve düzen arasında belirli bir ilişki vardır. Belirli bir sınıf için belirli bir temsilci ne kadar tipikse, onları birbirine bağlayan yolların öncelik listesindeki ilk sıralardan birini işgal etme olasılığı o kadar yüksek olur. Tipiklik veya yakınlık tahminlerinin öncelik ilişkilerine dayandığını varsayarsak, bu model tahminlerdeki farklılıkların nedenlerini açıklamayı kolaylaştırır.
Şaşırtıcı olmayan bir şekilde, yakınlık, doğruluk testi görevlerinde RT'yi etkiler (Smith, 1967; Wilkins, 1971). S ve P ne kadar yakından ilişkiliyse, "bazı S'ler P'dir" gibi ifadelerin doğruluğu o kadar hızlı doğrulanabilir. Örneğin denekler, "güvercin kuştur" gerçeğini "tavuk kuştur" gerçeğinden daha hızlı test eder. Şaşırtıcı bir şekilde, yakınlık etkileri, sınıf mevcudunun etkisinin kendini göstermeyeceği durumları tahmin etmemizi sağlar. Aşağıdaki örneği ele alalım (Rips a.o., 1973). ".mammals" sınıfı, "hayvanlar" sınıfına dahildir, dolayısıyla "hayvanlar" sınıfının kapsamı daha geniştir. Bununla birlikte, deneklere göre, bazı memeliler (örneğin, "ayı" veya "kedi"), "memeliler" sınıfına göre "hayvanlar" sınıfı için daha tipiktir. Ve "ayı bir memelidir" ve "ayı bir hayvandır" ifadelerini test etmek için BP'yi karşılaştırırsak, ikinci durumda daha kısa olduğu ortaya çıkar. Bu, sınıf mevcudunun etkisi hakkındaki tahminle aynı fikirde değildir ("hayvanlar" sınıfı daha kapsamlı olduğu için, test edildiğinde VR'nin daha büyük olması gerektiği görülmektedir), ancak tipiklik tahminlerine karşılık gelir. Bu sonuç yine CAEP modeli için bir zorluk yaratmaktadır (ancak arama sırasına göre açıklanmasına izin veren AFC modeli için değil: S ve P arasındaki yakınlık ne kadar yakınsa, S ve P arasındaki yakınlık o kadar erken olur) karşılık gelen yollar başlayacak ve ifade ne kadar hızlı test edilebilir).
DP'NİN TEORİK MODELİNİ BELİRLE
Şimdiye kadar yalnızca bir tür semantik DP modelini ele aldık - ağ modelleri. Bununla birlikte, farklı türde modeller vardır ve şimdi bunlardan "küme kuramı" olarak bilinen birini ele alacağız (Meyer, 1970). Anlamsal sınıfların DP'de bilgi öğeleri kümeleri veya koleksiyonları olarak temsil edildiği varsayımına dayanır. Bunlar, bir sınıfın temsilcilerinden oluşan kümeler olabilir (örneğin, "kuşlar" sınıfı, kızılgerdanları, bülbülleri, serçeleri vb. içerir). Aynı zamanda, belirli bir sınıfın bir dizi özelliği veya özelliği olabilir (örneğin, kuşların kanatları vardır, tüyleri vardır, uçabilirler vb.). Başka bir deyişle, bu veya bu kategori, DP'de belirli bir bilgi seti olarak sunulur.
Meyer (Meyer, 1970), deneklerin "tüm S'ler P'dir" veya "bazı S'ler P'dir" (örneğin, "tüm taşlar yakuttur" veya " bazı taşlar - yakutlar). VR hakkındaki verileri açıklamak için, böyle bir görevi gerçekleştirme sürecini açıklayan iki aşamalı bir model önerdi. Bu modele göre, bu tür bir ifade sunulan denek, önce P sınıfı ile kesişen (ör. örtüşen, ortak üyelere sahip) tüm kümelerin adlarını sıralar. "tüm S yazardır", denek "yazarlar" kümesiyle örtüşen kümeler aramaya başlayacaktır. Her biri yazar olan üyeleri olan "kadınlar", "erkekler", "insanlar", "profesörler" vb. Bu kümelerde S sınıfına ait elemanlar bulunursa (bu kümelerin S sınıfı ile kesiştiği gerçeği ortaya çıkacaktır), o zaman ilk aşama bir yazışmanın kurulmasıyla sona erecektir. Arama, S sınıfı ile bir eşleşme bulamazsa, ilk aşamanın sonucu olumsuz bir cevap olacaktır.
Kontrolün ilk aşamasında bir eşleşme bulunursa, bu, S ve P sınıflarının bazı ortak üyeleri olduğu anlamına gelir. Bu, "bazı S'ler P'dir" gibi bir ifadenin doğruluğunu doğrulamak için yeterli olacaktır, ancak "tüm S'ler P'dir" gibi bir ifadeyi doğrulamak için yeterli olmayacaktır. İkinci durumda, ikinci aşamayı gerçekleştirmek gerekir: P'nin tüm niteliklerini S'nin nitelikleriyle karşılaştırmak. Değilse, konu olumsuz bir cevap verir.
Belirli bir örnek alalım. P'nin "değerli taşlar" olduğunu varsayalım. Şimdi "bazı mineraller değerli taşlardır" ifadesini düşünün. Kontrolün ilk aşamasında, set "değerli taşlar" ile kesişen setler incelenir (yani, onunla ortak üyelere sahip). Bunlar, "elmas" ve ayrıca "mineraller" gibi sınıfları içerir, çünkü birçok mineral aynı zamanda değerli taşlardır. Böylece, ifadenin doğruluğu doğrulanabilir. S kelimesi "kuşlar" ("bazı kuşlar mücevherdir") olsaydı, "kuşlar" sınıfının üyelerinden hiçbiri aynı zamanda "taşlar" sınıfının bir üyesi olmadığı için ilk adım olumsuz bir cevaba yol açardı. Ancak "tüm yakutlar değerli taşlardır" ifadesinin doğruluğu kontrol edilirse, ilk aşamada bir karşılık bulunacaktır. Ancak "hepsi" kelimesinin varlığı da ikinci bir adımı gerektirecektir. Bunu yapmak için, değerli taşların tüm özelliklerini (pahalıdırlar, mücevherlerde kullanılırlar vb.) Yakutların özellikleriyle karşılaştırmanız gerekecektir. Her ikisinin de nitelikleri çakışırsa - ve bu durumda öyledirler, çünkü yakutlar da pahalıdır, mücevherlerde kullanılır, vb. - o zaman ifadenin doğruluğu belirlenir. Değilse, "tüm yazarlar kadındır" örneğinde olduğu gibi, ifade reddedilecektir. İkinci durumda, "yazarlar" kümesi "kadınlar" kümesiyle kesiştiği için ilk aşamada bir eşleşme bulunacaktır, ancak ikinci aşamada olumsuz bir cevap alınacaktır.
Meyer tipi bir küme-teorik modeli, yukarıda ele alınanlara benzer sınıf büyüklüğü etkilerini açıklamayı mümkün kılar. Bunu anlamak için, öncelikle bu modelde yapılan ve ilk aşamada gerçekleştirilen örtüşen sınıfları aramanın rastgele olmadığı varsayımına dikkat çekmeliyiz. P ile örtüşen sınıflar, örtüşme derecesine göre sırayla incelenir ve en yoğun şekilde örtüşen sınıflar önce test edilir. Bu, S ve P için ortak olmayan terimlerin sayısı ne kadar az olursa, S ve P'nin kesiştiği gerçeğinin ilk aşamada o kadar hızlı tespit edileceği anlamına gelir, çünkü tüm bu terimleri incelemenin daha erken bir aşamasında ortaya çıkacaktır. Bu, sınıf boyutunun etkisini açıklar: S'ye kıyasla P ne kadar büyükse, kesişmeleri o kadar az olur ve aramanın ilk aşamasında S'yi bulmak o kadar uzun sürer. Örneğin, S "kanaryalar" ve P "kuşlar" ise, S ve P'nin kesişimi, P'nin "hayvanlar" olduğu duruma göre daha güçlüdür (bu sınıf, "kuşlar" sınıfından daha büyüktür). Bu nedenle, P "kuşlar" ise, "kanaryalar" daha hızlı bulunacak ve P ile örtüşen sınıfları incelerken tepki süresi, P'nin "hayvanlar" olmasına göre daha hızlı olacaktır. Bu, olağan sınıf büyüklüğü etkisine yol açacaktır. Bununla birlikte, Meyer'in modeli, büyüklük yakınlığa karşılık gelmediğinde gözlemlenen büyüklük etkilerinin ihlalini açıklamaz (bkz. Rips ve diğerleri 1973), neden örneğin "kedi - kedi bir hayvandır?
SEMANTİK ÖZELLİKLERE GÖRE DP MODELİ
Küme-teorik yaklaşımın ürettiği modellerden biri de Smith, Shoben ve Riis'in anlamsal özelliklere dayalı modelidir (Rips a.o., 1973; Smith a.o., 1974). Avantajı, yukarıda tartışılan yakınlık etkilerini açıklayabilmesidir, yani, yakınlık derecesinin test sırasında gözlemlenen reaksiyon süresiyle neden sınıfın boyutundan daha iyi ilişkili olduğunu ve neden çeşitli temsilcilerin "tipikliği"nin anlaşılmasını sağlar. belirli bir sınıf için, deneklerin tepkisi ile ölçülen değişkenlik gösterebilir. Anlamsal özelliklere dayalı bir modelde, bir veya daha fazla anlamsal sınıf, DP'de bir dizi nitelik veya özellik olarak temsil edilebilir. Ek olarak, özellikler kümesinin çok kapsamlı olduğu ve hem belirli bir sınıfın tanımı için gerekli olan hem de görece önemsiz özellikleri içerdiği varsayılır. Büyük olasılıkla, bu sınıfın özellikleri, tanımı için çok önemliden önemsize kadar sürekli bir dizi oluşturur. Örneğin, "robin" kelimesini ele alalım. DP'de şu özelliklerin bir kombinasyonu olarak temsil edilebilir: "iki ayaklı", "kanatlı", "kırmızı gölete sahip", "ağaçlara otur", "evcilleştirilmemiş". İlk üç özellik muhtemelen "robin" kavramını tanımlamada son ikisinden daha önemlidir. (Tabii ki, bu liste eksiktir, ancak prensipte "robin" kelimesinin anlamını karakterize eden ayrıntılı bir dizi özelliğe sahip olabiliriz.)
(tanımlayıcı) özellikleri daha az önemli (yalnızca karakteristik) özelliklerden ayıran keyfi bir nokta seçebilirsiniz . Özellik tabanlı bir modelde, doğruluk kontrol görevlerinde niteliksel özelliklere karakteristik özelliklerden daha fazla önem verilir. ("Robin" örneğimizde, ilk üç özellik tanımlayıcı, geri kalanı karakteristik olarak kabul edilebilir.)
Şimdi, "robins" gibi bir sınıfın adından onun üzerinde duran "kuşlar" sınıfına geçişte özellik setlerinin nasıl değişebileceğini ele alalım. "Kuş" kavramı daha soyut, daha genel olduğu için daha az tanımlayıcı özelliğe sahip olacaktır. Nitekim, tüm kızılgerdanlar kuş olduğu için, "kuş" kavramının tüm tanımlayıcı özellikleri, "robin" kavramı için de geçerli olmalı ve buna ek olarak, ardıç kuşunun kendine ait birçok ek özelliği olmalıdır. Genel olarak, belirli bir kategori ne kadar soyutsa, o kadar az tanımlayıcı özelliğe sahip olacaktır.
Özellik tabanlı modelde kabul edilen D11'in yapısı ile ilgili temel varsayımlar yukarıda belirtilmiştir. Ana fikri - birbirleriyle kombinasyon halinde kavramların anlamını iletebilen semantik özelliklerin varlığı - ne dilbilimciler ne de psikologlar için yeni değildir (bkz. örneğin, Katz ve Fodor, 1963; Miller, 1972; Osgood, 1952) . Smith, Schoben ve Rips modelinde yeni olan, anlamsal özelliklerin önerilen doğası ve anlamsal bellek çalışmasından elde edilen verileri yorumlamanın ilişkili yolu. Ek olarak, modelin yazarları, özelliklerin rolü fikrini doğrulayarak deneysel sonuçlar elde etmeye çalıştılar. Rips ve diğerleri (1973) kavram grupları için "yakınlık puanları" toplamıştır, yani bir sınıfın farklı üyelerinin (ör. tavuk, ördek, serçe vb.) bu sınıfın adıyla (kuşlar) ne kadar yakından ilişkili olduğuna dair veriler ve kendi aralarında Bu tahminler mesafeler olarak temsil edilebilir. Örneğin, iki kavram arasındaki yüksek yakınlık puanları, aralarındaki küçük mesafeler olarak gösterilebilir. Bu tür benzerlik puanlarını mesafelere dönüştürmek için makine yöntemleri bile vardır. Bu yöntemler izin verir varsayımsal çok boyutlu bir uzayda çeşitli kavramları nokta nokta bükmek. Bu uzayda noktalar arasındaki mesafeler, karşılık gelen kavramlar arasındaki "psikolojik" mesafeler olarak yorumlanabilir. Aslında, bu mesafeler ilk benzerlik tahminlerini (tersine) yansıtır: iki kavramın noktaları ne kadar yakınsa, bu kavramlar bize o kadar benzer görünür. Ek olarak, ortaya çıkan alanın boyutu, yakınlık tahminlerinin psikolojik temelini yargılamayı mümkün kılar.
Şek. Şekil 8.5, "kuş" ve "memeli" kavramlarının yakınlık tahminlerine dayalı olarak oluşturulmuş iki boyutlu uzayları göstermektedir. Riis ve işbirlikçileri bu planı şu şekilde yorumluyor. Yakınlığın ilk değerlendirmelerinde, deneklerin D11'de saklanan anlamsal özelliklere güvendiklerini öne sürüyorlar: iki kavramın yakınlığını ortak özelliklerin varlığına göre değerlendirdiler. Ve bu da, ortaya çıkan iki boyutlu alanların koordinatlarının, denekler tarafından yakınlığı değerlendirirken kullanılan anlamsal özellikleri gösterebileceği anlamına gelir. Örneğin, Şekil 2'deki yatay eksen görünüyor. 8.5, nesnenin boyutuna karşılık gelir. Kuş uzayında, büyük kuşlar olan atmaca ve kartal sol tarafta, ardıç kuşu gibi küçük kuşlar sağ taraftadır. Memelilerin uzayında, büyük hayvanlar - bir geyik ve bir ayı - da kendilerini bir tarafta, diğer tarafta bir fare bulurlar. Her iki alandaki dikey eksen, "yırtıcı" gibi bir şeyle ilişkilendirilebilir, yani bununla, bu hayvanların başkalarını yiyecek olarak kullanma derecesi anlamına gelir. Memeli uzayında, vahşi ve evcil hayvanlar bu eksenin zıt uçlarındadır; kuşların uzayında yırtıcı türler evcil olanlardan ayrılır. Bu iki mekan birbirinden bağımsız olarak elde edildiğinden tekdüzelik çok dikkat çekici bir gerçektir; karşılık gelen koordinatların yakınlık tahminleri için değişmez bir temel olarak hizmet ettiği gerçeğini savunuyor. Bu durumda, bu tahminler açıkça boyut ve avlanma ile ilişkili semantik özelliklere dayanıyordu.
Phç, 8.5, Deneklerin kuş (A) ve memeli (B) sınıfları (Rips a.o., JS73) üyeleri arasındaki yakınlık değerlendirmelerinden oluşturduğu iki boyutlu uzaylar ,
Özellik tabanlı model, anlamsal bellek hakkında bahsettiğimiz birçok veriyi açıklar. Bunu anlamak için, bu modelde varsayılan, ifadelerin doğruluğunun kontrol edildiği süreçleri dikkate almamız gerekir. Ancak ilk olarak, DP'de varsayılan bilgi yapısını hatırlamalıyız . Model, her kavramın bir özellikler listesiyle temsil edildiğini varsayar. Bu işaretler en önemliden en önemsize doğru sürekli bir dizi oluşturur. Özniteliğin bu dizideki konumuna ağırlığı diyeceğiz (böylece ağırlık, belirli bir kavramı tanımlamak için şu veya bu özelliğin ne kadar önemli olduğunu gösterir; değeri daha büyük, ağırlık ne kadar yüksek olursa). Ağırlık ölçeğinde, keyfi olarak bir nokta seçilebilir ve büyük bir ağırlığa sahip tüm işaretler "belirleyici" ve daha küçük olan - "karakteristik" olarak kabul edilebilir. Modele göre "tüm S'ler P'dir" gibi bir önermenin doğruluğunun doğrulaması şu şekilde gerçekleşir. Sürecin ilk aşaması üç alt aşamaya ayrılmıştır. İlk olarak, S ve P sınıflarına karşılık gelen özellik listeleri DP'den çıkarılır, ancak bu listelerin eksiksiz olması gerekmez, hem tanımlayıcı hem de karakteristik özellikleri içerirler. Daha sonra bu iki listede yer alan özellikler - biri S için, diğeri P için - birbiriyle karşılaştırılır; Eşleşen özelliklerin sayısı, genel benzerliğin bir ölçüsünü elde etmek için temel oluşturur - buna x diyelim. Son olarak, bu ilk adımın sonucunun ne olduğuna karar vermek için x kullanılır. x'in değeri çok büyükse -belirli bir eşik değerinden büyükse- S ve P o kadar benzerdir ki sistem hemen "ifade doğrudur" yanıtını verir. Eğer x'in değeri çok küçükse (yani S ve P arasında benzerlik yok demektir), model "yanlış" cevabını verir. X'in bir ara değeri varsa - düşük veya yüksek değil - işlemin ikinci aşaması gerçekleştirilir.
İkinci aşamada S ve P kavramlarının sadece tanımlayıcı özellikleri kullanılır, bu adeta ikinci testtir; S ve P arasında kısmi bir benzerlik varsayımına dayanır ve amacı bu benzerliğin doğasını aydınlatmaktır. P öznitelikleri S öznitelikleriyle eşleşirse, olumlu bir yanıt verilebilir; aksi halde cevap olumsuz olacaktır. Tüm bunlardan, ifadelerin doğruluğunu kontrol etme görevlerindeki yanıtların ortalama tepki sürelerinin aslında küçük (S ve P çok benzer veya çok farklı olduğunda) ve büyük (ikinci bir aşama olduğunda) karışımından oluştuğu sonucu çıkar. gerekli) değerler.
Özellik tabanlı bir modelin avantajlarından biri, VR'nin tipikliğe veya yakınlığa bağımlılığını açıklayabilmesidir. Bu modele göre, belirli bir temsilci, belirli bir sınıf için ne kadar tipikse, o kadar ortak özelliklere sahiptir. Bu nedenle, S ve P'nin ortak özelliklerinin sayısına dayanan bir benzerlik ölçüsü olan x'in değeri, tipiklik arttıkça artar. X'in yüksek değerlerinde, karşılaştırmanın ilk aşamasında olumlu bir yanıt alma olasılığı artar. Bu, tipiklik arttıkça VR'nin azalacağı anlamına gelir.
Bu model aynı zamanda sınıfın büyüklüğünün etkilerini de açıklar, sadece bunların yakınlığın etkilerine göre ikincil olduğunu varsaymak gerekir. Çoğu durumda, P sınıfının boyutunu artırmak, S ve P arasındaki yakınlığın azalmasına ve reaksiyon süresinin (RT) uzamasına yol açar. Örneğin, S bir "serçe" ise, o zaman P-"kuş" değerinden "hayvan" değerine geçerken, S ve P arasındaki benzerlik azalacak ve buna bağlı olarak BP artacaktır. Diğer durumlarda, örneğin, "memeli" anlamından "hayvan" değerine geçişle birlikte P arttığında, sınıfın değerindeki aynı değişiklik, tersine, S ve P'nin yakınsamasına yol açacaktır; bu durumda, VR azaltılacaktır. Bu bağlamda, Smith, Shoben ve Riis, sınıf mevcudunun etkisinin sanıldığı kadar güçlü olmadığı sonucuna varırlar. Oldukça önemli ölçüde değişir ve sınıf mevcudundaki değişikliklere eşlik eden S ve P'nin yakınlığındaki değişikliklere atfedilebilir.
Bu nedenle, üç tür semantik bellek modelini ele aldık: ağ modelleri, küme-teorik modeller ve anlamsal özelliklere dayalı bir model. Her tür, yoğun bir şekilde incelenen iki fenomenle bağlantılı olarak değerlendirildi - sınıf mevcudunun etkisi ve yakınlığın etkisi. Görüldüğü gibi, bu modeller birçok açıdan benzerdir. Örneğin, tüm bu modellerde, herhangi bir kavram, ister çağrışım olsun, ister bazı kavramları diğerlerinde alt küme olarak içermek veya özellik olarak kullanmak olsun, diğer kavramlarla olan ilişkileri sonucunda belirli bir anlam kazanır. Her birinin kendine özgü yetenekleri olmasına rağmen, bu modellerin tümü burada sunulan semantik bellekle ilgili verilerin çoğunu açıklar. Ağ ve küme-teorik modeller arasında bir dizi önemli fark olduğu da açık olmalıdır; en önemli farklılıklardan biri, bu modellerin neyi açıklamaya çalıştığıyla ilgilidir. Meyer'in teorik çoklu modeli ve Smith, Schoben ve Riis'in modeli, semantik hafıza çalışması üzerine belirli türde deneylerde elde edilen verileri yorumlamak için tasarlanmıştır. Ağ modelleri ise çok daha geniş bir veri yelpazesiyle ilişkilendirilebilir. Örneğin, AFC modeli, dil yeteneği, unutma, algılama, örüntü tanıma, öğrenme ve diğerleri gibi çok çeşitli alanlarla ilgili sonuçları açıklamaya çalışır. Bu kadar geniş bir sorun kapsamı göz önüne alındığında, ağ modelleri yalnızca anlamsal değil, aynı zamanda epizodik bellekle ilgili birçok olguyu incelemede yararlı olabilir; bu nedenle, bu tür modeller sonraki üç bölümde birçok sorunun tartışılmasında kullanılacaktır.
Küme-teorik modeller şu anda epizodik bellek olgusunu açıklamaya izin vermiyor. "Şu anda" ifadesi çok önemlidir. Mesele şu ki, anlamsal bellek alanındaki araştırmalar alışılmadık derecede hızlı gelişiyor.
Bu bölümde açıklananlar gibi çalışmaları veya modelleri tartışırken, sürekli olarak meydana gelen tüm değişiklikleri hesaba katmak imkansızdır. Ek olarak, sonuçları modeller yardımıyla açıklanması gereken yeni deneyler her zaman geliştirilmekte ve gerçekleştirilmektedir. Tüm bunlar, anlamsal bellek sorununu psikolojik araştırmanın en dinamik ve heyecan verici alanlarından biri haline getiriyor.
Bölüm 9
Uzun süreli bellek: unutmak
DP'de saklanan herhangi bir bilgiyi unutmaktan bahsederken ne demek istiyorlar? Bu sorunun cevabı o kadar kolay değil çünkü unutmanın pek çok farklı biçimi olabilir. Örneğin, bir yaşına bastığınız gün ne olduğunu hatırlayamazsınız, ancak doğum gününüz kutlanmış olabilir. Bir kişi genellikle bebeklik döneminde ve erken çocukluk döneminde başına gelen her şeyi hatırlamaz. Bu yaşta bir kişi henüz konuşmayı geliştirmediğinden, DP'de saklanabilecek sözel kodları yoktur; bu nedenle, yaşamın erken döneminde meydana gelen olayların unutulması, yetişkinlikte gözlenen unutmadan temelde farklı olabilir. Ancak bir yetişkinde bile unutmanın doğası çok farklı olabilir. Örneğin, bir kişinin bir mağazadan bir şey almayı unuttuğu, bir randevuya gelmediği veya bir test sırasında öğelerden birini tamamlayamadığı sözde "sıradan" unutma vardır. Fiziksel travmanın bir sonucu olarak unutma vardır - amnezi. Bastırma olgusu da bilinir - hatırlaması zihinsel acıya neden olan olayların kasıtlı olarak unutulması.
Bu kadar çeşitli anlamlar karşısında, unutma konusuna geçmeden önce ona bir tanım vermeye çalışacağız. Bir zamanlar kodlanmış olan ve sonra geri alınması gereken materyalin bellekten geri alınamaması durumuna unutma diyelim. (Algısı örüntü tanıma aşamasına bile ulaşmamış olayları hatırlayamamayı "unutma" kavramından dışlamak için aranan malzemenin bir zamanlar kodlanmış olduğu açıklığa kavuşturulmalıdır.) Bu oldukça geniş bir tanımdır. , ancak gözlemlenebilen tüm farklı unutma türlerini dahil etmek için genişlik gereklidir. Bazen unutulan materyal kısmen bile kurtarılamaz (örneğin, bir kişinin Fransızca "kitap" kelimesini daha sonra doğrulamak için ezberledikten sonra hatırlayamadığı durumlarda olduğu gibi); unutma da kısmi olabilir (unutulan kelimelerin "dilin ucunda döndüğü" durumlarda olduğu gibi); bazen unutmak çarpıtma biçimini bile alır (kişi gerçekte olandan farklı bir şey hatırladığında; örneğin, bir trafik kazasına karışan sürücülerden biri bir kazadan sonra başka bir sürücünün ağır bir ihlalde bulunduğunu "hatırlayabilir", ancak tanıklar doğrulayabilir. onunla aynı fikirde değilim). Bu tür vakalar, genel unutma tanımımıza da uyar, çünkü burada da DP'den çıkarılabilecekler, hatırlanması gerekenlerle örtüşmez.
PROAKTİF VE GERİ DÖNEMLİ FRENLEME
Uzun süreli bellekten unutma genellikle Bölüm 1'de açıklanan iki yöntem kullanılarak incelenmiştir. 6, - PT ve RT yöntemleri. Bu yöntemler burada daha ayrıntılı olarak tartışılacaktır. Önceden ezberlenmiş başka bir materyalin müdahalesi sonucu bazı materyalin unutulması durumunda proaktif engellemeden (PT) söz edildiğini hatırlayın. Geriye dönük engelleme (RT), daha sonra öğrenilen materyalin neden olduğu unutmadır. Bu iki girişim türü, esas olarak çift ilişkileri kullanan deneylerde incelenmiştir.
Tartışmamıza devam etmeden önce, bazı gösterimler üzerinde anlaşmak gerekiyor. Uyaranların A kümesinden ve yanıtların B kümesinden alındığı eşleştirilmiş çağrışımların bir listesini, A-B listesi olarak adlandıralım. Örneğin, A - bileşenleri üç harfli heceler (ünsüz - sesli - ünsüz) ve B - basamaklı bileşenler ise, A - B listesi örneğin DAK-7 veya SEV-3 gibi öğelerden oluşacaktır. . Benzer şekilde, A-C, uyaranların A-B listesindekilerle aynı bileşenler (A) olduğu ve reaksiyonların C kümesinden alınan diğerleri olduğu bir çift çağrışımlar listesi anlamına gelir. Örneğin, eğer C ise, bileşenler şu harflerdir: alfabe, ardından A listesinde DAK-B veya SEV-X gibi öğeler mümkündür. Bu gösterimleri kullanarak, PT ve RT yöntemlerini Şekil 1'de yapıldığı gibi temsil edebiliriz. 9.1.
Aktif frenleme
Zaman: inci >
Geriye dönük frenleme
Bpcüfi — >-
Pirinç. 9.1. Anahtar membran ve geriye dönük frenleme için çift ilişkilendirme listeleri içeren xxier ctode'a bakın^
Hem PT hem de RT olmak üzere her iki yöntemde de, deneysel bir denek grubu, belirli bir ezberleme düzeyine ulaşılana kadar A - B ikili ilişkilendirmelerinin bir listesini ezberler (genellikle listenin birkaç hatasız kopyası bir ölçüt görevi görür). Sonra A - C listesini ezberlerler; içinde, uyaranlar ilk listedeki ile aynı bileşenlerle ve yanıtlar diğer bileşenlerle temsil edilir. Tutma aralığından sonra, denekler tekrar listelerden birini yeniden üretir. Proaktif inhibisyon (PT) çalışırken, kontrol reprodüksiyonu A - C listesine göre gerçekleştirilir. Deneklerin kontrol grubu yalnızca A - C listesini ezberler (veya bazen A - C listesinden önce farklı bir X - Y listesini ezberler) , ve ardından aynı aralık tutmadan sonra A - C listesini yeniden üretir. PT, A - B listesini ezberlemenin bir sonucu olarak deney grubunun deneklerinde ortaya çıkan girişim olarak tanımlanır. Bu durumda, PT şu şekilde nicelendirilebilir: deney grubundaki üremenin kontrol grubundan ne kadar kötü olduğunun belirlenmesi. Buna göre PT, kontrol grubundaki A - C listesindeki ortalama/doğru çoğaltma yüzdesi ile deney grubundaki ortalama doğru çoğaltma yüzdesi arasındaki farkın doğru çoğaltma yüzdesine bölümü olarak tanımlanır. kontrol grubu (bölüm, bu A - C listesini yeniden oluşturmanın zorluğunu hesaba katmanızı sağlar; bu sayede PT'nin değerlendirmesi, diğer hatalar için yapılan değerlendirmelerle karşılaştırılabilir hale gelir). Örneğin, kontrol grubundaki doğru üreme ortalama% 75 ve deney grubunda -% 50 ise, o zaman
PT=(75-50)/75= 1/3=%33.
Geriye dönük inhibisyonu ölçme yöntemi, PT için açıklanandan yalnızca, kontrol yeniden üretimi sırasında, deney grubunun ikinci liste yerine ilk ezberlenmiş listeyi hatırlaması gerektiğinden farklıdır, çünkü biz birinci listenin yeniden üretimindeki bozulmayla ilgileniyoruz. ikinci listenin ezberlenmesinin etkisi. Bu nedenle, deney grubu A-B listesini ve ardından A-C listesini ezberler, ardından A-B listesinin çoğaltılmasını kontrol etmeye geçerler. Kontrol grubu A-B listesini ezberler ve sonra hiçbir şey yapmaz (veya bazı deneylerde tamamen farklı bir liste öğrenir) X - Y), ardından A - B listesinin kontrol yeniden üretimine geçer. Bu durumda, A - B listesini yeniden üreten deney grubunun denekleri de kontrol grubunun deneklerinden daha fazla hata yapacaktır. ; buna göre RT, kontrol ve deney gruplarındaki doğru çoğaltmaların ortalama yüzdeleri arasındaki farkın kontrol grubundaki doğru çoğaltmaların yüzdesine bölünmesiyle ölçülür.
PT ve RT ile yapılan deneylerin en önemli özelliği, her iki durumda da deney grubu deneklerinde üreme etkinliğinin azalmasıdır. Bu nedenle, her iki prosedürü de unutmaya yol açan araçlar olarak düşünebiliriz: hatta birçok teorisyen laboratuvardaki unutmanın temelde günlük hayatta şu veya bu bilgiyi unutmaktan hiçbir farkı olmadığına inanır. AT ve RT'nin bir diğer önemli özelliği, girişim derecesinin, bir girişim listesinde gerçekleştirilen deneme sayısına bağlı olmasıdır (Briggs, 1957; Underwood ve Ekstrand, 1966) (bir girişim listesi, bir deney grubuna sunulan, ancak bir kontrol grubuna değil). Başka bir deyişle, AT veya RT derecesi, müdahale listesindeki deney grubu ile yapılan deneme sayısına bağlı olarak değişir. PT durumunda A-B listesidir ve RT durumunda A-C listesidir.
MÜDAHALE VE UNUTMA
Proaktif ve geriye dönük inhibisyon mekanizmasına ilişkin hipotezlerin genellikle her tür unutma için geçerli olduğu kabul edilir. Unutmanın müdahale teorisinin genel adı altında birleştirilirler. Bu tür birkaç hipotez vardır ve bu bölümde bunlardan bazılarını ele alacağız. Ancak bunu yapmadan önce akılda tutulması gereken iki nokta vardır. İlk olarak, bu hipotezler çoğunlukla geleneksel uyaran-tepki yaklaşımına dayanmaktadır ve bazıları unutmayı "beceri gücü" açısından yorumlamaya çalışmaktadır. Bu nedenle, bazen anlayışımıza yabancı görünecekler. Ancak bu, müdahale kavramının DP'den unutma süreçlerini açıklamak için hiçbir şey sağlamadığı anlamına gelmez. Bu sadece müdahale teorilerinde kullanılan terminolojinin bazen uygunsuz görünebileceği anlamına gelir; Karışıklığın mümkün olduğu durumlarda, bu terminolojiyi bilgilendirme yaklaşımımızla uyumlu hale getirmeye çalışacağız. İkincisi, inceleyeceğimiz deneylerin çoğunun olaysal bellekten unutmayla ilgili olduğunu hatırlamak önemlidir. Tulving (1972), semantik bilginin kolayca unutulmadığını ileri sürmüştür. Bu nedenle, DAC uyaranına yanıt olarak "kurbağa" kelimesini unutmanın muhtemelen kurbağanın ne olduğunu unutmaktan oldukça farklı bir şey olduğu akılda tutulmalıdır.
TEPKİ YARIŞMASI
LTP'de saklanan bilgilerin unutulmasıyla ilgili ilk hipotezlerden biri, McGoch'un reaksiyon rekabeti hipoteziydi (McGeoch, 1942). İçinde, proaktif ve geriye dönük ketleme ile ilişkili unutma, uyaran-tepki kavramı açısından oldukça basit bir şekilde yorumlanmıştır. Aslında, bu hipotez, A listesinin A - Vee listesini ezberlediğimizde, her bir uyaran bileşeni için farklı güçte ilişkiler oluşturduğumuz, biri diğerinden daha güçlü olan iki dernek oluştuğu gerçeğine indirgenmiştir. Kontrol reprodüksiyonu sırasında test deneğine bir uyaran bileşeni sunulduğunda, iki reaksiyon rekabete girer ve daha güçlü olan çağrışım kazanır, daha zayıf olanın tezahür etmesi engellenir. Örneğin, A - B listesinin DAK-7 eşleştirilmiş bir ilişkisi varsa ve A - C listesinin bir DAK-8 ilişkisi varsa, bu tür bir iç yapı ortaya çıkabilir:
Bu durumda oynatma sırasında özne DAK-? ile sunulduğunda "8" yanıtını verecektir. Proaktif veya geriye dönük inhibisyon içeren deneylerde, kontrol listesinden ziyade müdahale edene ait bir reaksiyon daha kararlı olabilir.
McGoch'un hipotezine yönelik ana itiraz, deneklerin hatalarının bir müdahale listesinden "izinsiz girişler" şeklinde ifade edilmesi gerektiği öngörüsüne ilişkindir; eğer konu yanlışsa, DAC uyaranına "8" yanıtını verecektir (gerçi doğru yanıt "7" olacaktır), çünkü araya giren kayma DAC-8 öğesini içermektedir. "2" veya "16" cevabını vermeyecek veya başka herhangi bir rastgele sayı vermeyecektir. Ancak gerçekte hatalar farklı niteliktedir (Melton ve Irwin, 1940). Bunu doğrulamak için, Şek. 9.2. Müdahale listesindeki deneme sayısı arttıkça geriye dönük engellemenin (RT) (ve dolayısıyla kontrol listesi hatalarının sayısının) arttığını ve ardından biraz azaldığını göreceksiniz. Bununla birlikte, "izinsiz giriş hataları" kademeli olarak değişir: izinsiz girişlere atfedilebilecek TA, müdahale eden listedeki artan örnek sayısıyla azalırken, toplam TA artmaya devam eder.

Arayüze göre örnek sayısı)
Şekil 9.2. Toplam RT'nin (geriye dönük toryum) eksenleri* (P ve RT. kishroi: girişim listesine göre örnek sayısından izinsiz giriş hatalarına (I) atfedilebilir (Mellon a. igivil, 191 D),
SÖNMEK
Proaktif ve geriye dönük inhibisyonu açıklamak için önerilen bir başka hipotez de yok olma hipotezidir (Melton ve Irwin, 1940; Underwood, 1948a, b).
Bu hipoteze göre, müdahale sonucu çağrışımların parçalanması unutmada önemli bir rol oynar. Bazen bu bozulma, sıradan şartlandırılmış reflekslerle yapılan deneylerde gözlemlenen sönme ile karşılaştırılır. Sönmenin ne olduğu hakkında bir fikir edinmek için, koşullu reflekslerin gelişimi ile ilgili klasik deneyleri kısaca açıklayalım.
Standart yöntemi kullanarak, belirli bir ses sinyaline yanıt olarak bir köpekte koşullu bir refleks salivasyon geliştirmek mümkündür. Bir köpek koşulsuz bir uyarana maruz kaldığında, hayvanı önceden eğitmeden istenen tepkiyi üretir (salivasyon için uyaran yiyecek olabilir). Böyle bir koşulsuz uyaran, koşullu bir uyaranla birlikte kullanılır - bu durumda bir ses sinyali ile: önce bir sinyal ve ardından koşulsuz bir uyaran, ardından köpeğin bir tepkisi vardır (koşulsuz bir uyaran vererek, ardından ona bir tepki verir. pekiştirme denir). Birkaç kez tekrarlanan böyle bir prosedür, koşullu bir refleks oluşumuna yol açar: sonuç olarak, reaksiyon yalnızca bir koşullu uyarana yanıt olarak gerçekleşir - herhangi bir yiyecek sunumu olmadan hemen onu takip eder. Böyle bir reaksiyona şartlandırılmış denir. Ancak bu durum sonsuza kadar sürer mi? Koşullu bir uyaranı koşulsuz bir uyaranla pekiştirmeden tekrar tekrar sunduğumuzu varsayalım. Başlangıçta, bu yine de tükürüğün salınmasına yol açar, ancak yavaş yavaş reaksiyon zayıflar ve sonunda kaybolur. Bu gibi durumlarda pekiştirme yapılmaması sonucu sönme meydana geldiği söylenmektedir. Bundan sonra üçüncü aşama başlayabilir - şartlandırılmış refleksin kendiliğinden restorasyonu. Köpeğe koşullu veya koşulsuz bir uyaran sunmadan dinlenmesi için biraz zaman verirseniz ve ardından ses sinyalini tekrar uygularsanız, köpeğin buna yine tükürük salgılayarak tepki vereceği ortaya çıkacaktır. Görünüşe göre , solma gerçekten nihai değildi. Bu gibi durumlarda, bir ses sinyaline yanıt olarak yeniden ortaya çıkmasının bir sonucu olarak, sönmüş şartlandırılmış bir refleksin kendiliğinden restorasyonundan söz edilir. Bununla birlikte, ses sinyalinin sunumu takviye olmadan devam ederse refleks tekrar kaybolabilir veya sinyale takviye eşlik ederse geri yüklenebilir.
Bu üç aşama - refleks gelişimi, yok olma ve kendiliğinden iyileşme - eşleştirilmiş çağrışımlar öğrenildiğinde unutmayı açıklamak için kullanılır. Nasıl kullanıldıklarını anlamak için, Şek. 9.3, proaktif veya geriye dönük inhibisyona sahip bir deneyde zaman içinde meydana gelen değişikliklerin teorik eğrisini gösterir. İlk olarak, konu bir listeyi değil, A - B'nin bir listesini ezberler; bu durumda, bir köpeğin bir ses sinyaline salya salgılaması tepkisi geliştirmesine benzer şekilde, bu listedeki uyaran bileşenlerine tepkiler geliştirdiğine inanılıyor. Daha sonra denek A - C listesini ezberler; şimdi C-reaksiyonları onun için şartlı hale geldi ve daha önce öğrenilen B-reaksiyonları pekiştirilmedikleri için kayboldu. Bununla birlikte, tutma aralığı sırasında, A-B reaksiyonlarının kendiliğinden iyileşmesi meydana gelecektir. Sonuç olarak, A-Cy listesine göre testler yapılırken, hasta proaktif inhibisyon yaşayacaktır: A-B listesine reaksiyonların etkinliğinde göreli bir artış Alıkonma aralığı sırasında, A-C listesine göre örneklerde etkinlikte nispi bir düşüşe yol açacaktır. Bu düşüş, B ve C'nin A uyaranlarına verdiği yanıtlar arasındaki rekabetten kaynaklanıyor gibi görünmektedir . Ancak, testler A-B listesinde gerçekleştirilirse , o zaman şüphesiz A-C listesinin öğrenilmesinden kaynaklanan bir verim düşüşü olacak ve bu da A - B'nin yok olmasına yol açacaktır. Dolayısıyla bu durumda geriye dönük inhibisyon gözlemlenecektir.

proaktif ve geriye dönük engellemelerle i zhperimsitlh doğru cevapların düşük yüzdesi bekleniyor . l. A - II listesini ezberlerken, bu listedeki pasajlardaki doğru cevapların yüzdesi artar. G. L - C listesi ezberlenmediğinde, bu listeye göre örneklerde doğru cevapların yüzdesi artar ve A - B listesine göre örneklerde A ve I arasındaki ilişkilerin yok olması nedeniyle azalır . . Akılda tutma aralığı sırasında , A - B çağrışımlarında kendiliğinden bir iyileşme olur, bu da A - C listesi için doğru cevapların ve testlerin yüzdesinde bir azalmaya (proaktif engelleme) ve aşağıdakilere göre testlerde bir artışa yol açar: A - B listesi, iyon ns başlangıç seviyesine ( geriye dönük engelleme } - d. Testin gerçekleştirildiği listenin ikincil ezberlenmesi, içerdiği öğeler için doğru cevapların yüzdesinde bir artışa yol açar , ez, diğer unsurların hatırlanmasındaki farkın etkisi.
Özetle, yok olma hipotezine göre A listelerini öğrenirken şunu söyleyebiliriz.
B ve A - C bu listelerdeki müteakip testler A - B ilişkileri, A - C listesinin ezberlenmesi sırasında kaybolur. Bunun, A - bileşenlerinin A - listesinin ezberlenmesi sırasında sunumundan kaynaklandığına inanılmaktadır - C, takviye almayan B reaksiyonlarının hatırlanmasına neden olur. Bununla birlikte, alıkonma aralığı sırasında B reaksiyonlarında bir miktar kendiliğinden iyileşme olacaktır. Test denemeleri sırasında, A uyarıcısı sunulduğunda, B ve C reaksiyonları birbirleriyle rekabet edecek (yaklaşık olarak McGoch hipotezinin tahmin ettiği gibi) ve hem rekabetin kendisi hem de sonucu, her iki ilişkinin göreli gücüne bağlıdır. (Yanıtlar arasındaki rekabet, unutmaya neden olan yok olma ile birlikte ikinci bir faktör olarak kabul edilir ve bu nedenle bu hipotez bazen iki faktörlü hipotez olarak adlandırılır.)
İki faktör hipotezi, o kadar büyük miktarda deneysel çalışmaya yol açtı ki, bunların tam bir incelemesini yapmak ezici bir görev olurdu. Tüm bu araştırma alanını bir bütün olarak ele almaya çalışmadan, burada sadece "klasik" hale gelen bazı deneyleri ve teorik yapıları ele alacağız. (Modern incelemelerden biri olarak, Postman ve Underwood'un, 1973'ün bu konuda bir bibliyografya da sağlayan çalışmasını önerebiliriz.)
İki faktörlü hipotezden, denemeler sırasında gözlemlenen proaktif ve retroaktif inhibisyon derecesinin tutma aralığına bağlı olması gerektiği açıkça anlaşılmaktadır. Akılda tutma sırasında A-B çağrışımlarının gücü arttıkça, bu, A listesindeki örneklerdeki yanıtların etkinliğinde artan bir düşüşe yol açacaktır.
C. Ek olarak, A-B çağrışımlarının geri kazanılması için ne kadar fazla zaman tanınırsa, A-B listesindeki sonraki denemelerde verimlilik o kadar yüksek olur.Bu, uzun tutma aralıklarında, proaktif inhibisyon derecesinin daha yüksek olacağı ve geriye dönük inhibisyonun daha düşük (Underwood, 1948a, b).
MOS ile yapılan deneylerde yok olma hipotezi lehine güçlü veriler de elde edildi.
değiştirilmiş ücretsiz hatırlama (Briggs, 1954) ve DMSP ile - "iki kez değiştirilmiş ücretsiz hatırlama" (Barnes ve Underwood, 1959). Her iki türden deneylerde, A-C listesinin ezberlenmesi sırasında A-B ilişkilerinin bozulmasını doğrudan ortaya çıkarmak, yani yok olma sürecinin özüne nüfuz etmek için bir girişimde bulunuldu. Her iki durumda da A-B ve A-C listesi öğrenme yöntemi kullanılmış ancak deneklerin aldığı yönergeler farklı olmuştur. MSP deneylerinde denekler önce A-B listesini, ardından A-C listesini ezberlediler, ardından kendilerine A bileşenlerinin her biri sunuldu ve akıllarına gelen cevapları vermeleri istendi; başka bir deyişle, belirli bir listeden tepkileri tekrarlamaları değil, ilk hatırladıklarını cevaplamaları istendi. Belirli bir uyaranla en güçlü şekilde ilişkilendirilen yanıtların önce hatırlanacağı varsayılmıştır; bu nedenle, belirli bir listeyle ilgili yanıtların yüzdesi, o listedeki uyaranlar ve yanıtlar arasındaki ilişkinin gücünün bir ölçüsü olarak hizmet edecektir. Briggs deneylerinin sonuçları Şekil 1 ve 2'de sunulmuştur. 9.4 yok olma hipotezini kuvvetle destekler. A listesini ezberlerken
(veya A - C)'de, A - B (veya A - C) listesinde yer alan reaksiyonların yüzdesi arttı. Kısa bir tutma aralığından sonraki son çalışmada, C listesinden B listesine göre daha fazla tepki geldi. Ancak tutma aralığı uzadıkça C listesinin avantajı azaldı ve 24 saati aşan aralıklarla listeye kaydı. B.

Şekil 9.4. Kodlanmış boş alan belleği (MCIG) ile yapılan deneyin sonuçları (Briggs, 1954). a, Depodaki listeyi ezberlerken A-B listesindeki reaksiyonların yüzdesi, A. L - C listesini ezberlerken her bir listenin ke reaksiyonlarının yüzdesi a. A-C listesinin sunumundan sonra tutma aralığının bir fonksiyonu olarak MSP testindeki her bir listeden yanıtların yüzdesi daireler } deney öncesi yanıtların oranı, yani, dersin başında en önemli uyaranla ilişkilendirilen tepkiler deney .
Briggs deneyleriyle ilgili sorunlardan biri, bozunma hipotezini destekleseler de, A-C'lerin bir listesini öğrenmenin aslında B reaksiyonlarının bozunmasına neden olduğunu göstermemiş olmalarıdır. B reaksiyonlarının hala hafızasında saklanmış olması muhtemeldir, ancak denek onları daha önce aklına C reaksiyonları geldiği için tekrarlamadı. Barnes ve Underwood (Barnes ve Underwood, 1959) bu sorunu çözmek için, yani B-reaksiyonlarının hafızada saklanmaya devam edip etmediğini öğrenmek için DMSP yöntemini kullandılar: deneklere A uyaranlarının her biri sunuldu ve soruldu. B ve C reaksiyonlarının nasıl olduğunu hatırlamaya çalışın. Bu deneyin sonuçları, Şek. 9.5, yanıtların gerçekten de ortadan kalktığını gösteriyor. A-C listesi ezberlendikçe, deneklerden onları yeniden üretmelerinin istenmesine rağmen B-reaksiyonları giderek daha az hatırlandı: görünüşe göre bu reaksiyonlar hafızadan kayboldu.
Pirinç. 9.5. Her ikisi için de DMSP ("çift değiştirilmiş geri çağırma belleği *)" türündeki doğru oj ekleme prn test örneklerinin ortalama sayısı ? A - C listesindeki örnek sayısının bir fonksiyonu olarak listeler (Barnes; j. Un. Jerwood " 1959),
Az önce açıklanan deneylerin sonuçları, LTP'nin iki faktörlü unutma hipotezini doğruluyor gibi görünüyor, ancak diğer çalışmaların verileri o kadar ikna edici değildi. Bu hipotezin deneysel olarak test edilmemiş iki yönünü ele alalım. İlk olarak, bu hipotez, A-C listesinin öğrenilmesi sırasında B yanıtlarının hatırlandığı ancak pekiştirilmediği için A-B çağrışımlarının azaldığı varsayımını içerir. Bu varsayım henüz net bir onay almadı. İkinci olarak, alıkonma aralığı sırasında B-reaksiyonlarının kendiliğinden geri dönüşü hakkında şüpheler vardı.
İlk önce pekiştirmeme hipotezini ele alalım. Değişkenlerinden biri, denek A - C listesini ezberlerken B cevaplarını yüksek sesle söylerse ve bu cevaplar daha sonra pekiştirilmezse, o zaman kaybolurlar. Bununla birlikte, A-C listesindeki A-B listesindeki açık (sesli) yanıtlar nispeten nadirdir, bu nedenle çağrışımların dağılması yalnızca bununla ilgili olamaz: B'nin gizli veya dahili yanıtlarının ve bunların müteakip takviye edilmemesinin etkisini varsaymalıyız. Ancak bu konuda bile mevcut veriler çelişkilidir. Genel olarak, A-C listesinin öğrenilmesi sırasında A-B listesinden açık veya gizli müdahalelere herhangi bir şey neden olduğunda, önemli bir geriye dönük engelleme olması beklenir, çünkü ne kadar fazla izinsiz giriş olursa, o kadar büyük olacaktır. reaksiyonlar B ve dolayısıyla yok olma. Bu nedenle, B ve C reaksiyonları arasındaki benzerlik ne kadar büyükse, A - C listesinin ezberlenmesi sırasında B listesinden daha gizli (açık değilse) izinsiz girişlerin meydana geldiği ortaya çıktığında, geriye dönük engelleme o kadar büyük olur, o zaman tüm bunlar bizim doğrular. hipotez. Görünüşe göre benzerlik, A-C listesinin ezberlenmesiyle yaratılan daha büyük yok olmalarına ve daha güçlü geriye dönük engellemeye yol açan B-reaksiyonlarının çağrılmasına katkıda bulunur (Friedman ve Reynolds, 1957; Postman a.o., 1965). Bununla birlikte, tersi etki de mümkündür: A - C listesindeki tepkiler büyük bir güçlük çekmeden ezberlenirse, o zaman A - B listesinin yok olması (ve geriye dönük engelleme) önemsiz olmalıdır, çünkü çağrıştırmak için daha az fırsat olacaktır. A - C öğrenme listesi sırasında B-yanıtları ve dolayısıyla bu yanıtların pekiştirilmemesi için daha az fırsat. Bu fikir, takviye edilmeme hipotezini zayıflatan ikna edici deneysel onay almadı (Postman ve Underwood, 1973).
Kendiliğinden iyileşmeye atıfta bulunan yok olma hipotezinin bu kısmı, olgusal verilerle daha da az desteklenmektedir. Kendiliğinden iyileşmeyi incelemenin bariz yollarından biri, DMSP yöntemi olarak düşünülmelidir. Deneklere bir A-B listesi, ardından bir A-C listesi sunulabilir ve birkaç farklı tutma aralığından sonra, DMSP yöntemi kullanılarak bir kontrol reprodüksiyonu gerçekleştirilebilir. A-B ilişkilerinin zamanla eski haline getirilmesi gerektiğinden, daha uzun tutma aralıklarıyla B reaksiyonlarının sıklığının daha yüksek olmasını bekleyebiliriz. Bu arada kendiliğinden iyileşme sürecini belirlemek için yapılan deneylerde (Ceraso ve Henderson, 1965; Houston, 1966; Koppenal, 1963), A-B listesinin sonuçlarında zaman içinde herhangi bir iyileşme bulunmadı. Muhtemelen en başarılı olanı (en azından iyileşme lehine bazı veriler elde etmek açısından) Postman ve meslektaşlarının deneyleriydi (Postman a. o., 1968, 1969). Bu araştırmacılar, oldukça kısa bir tutma aralığı olan yaklaşık 25 dakika sonra B yanıtlarında bir miktar iyileşme gözlemlediler. Bu, 20 dakikalık aralıklarla proaktif inhibisyonun (spontan iyileşme ile ilişkili olduğuna inanılan) nispeten zayıf olduğu gerçeğiyle karşılaştırıldığında özellikle garip görünüyor (örneğin bkz. Underwood, 1949). Ele alınan teoriye göre, proaktif inhibisyon (PT), B-reaksiyonlarının kendiliğinden düzelmesinden kaynaklanır; O halde, AT minimum olduğunda, kurtarmanın olmadığı aralıklarla ve kısa aralıklarla kurtarma yapılan kontrol oynatmaları sırasında nasıl güçlü bir AT oluşabilir?
Postman ve Stark tarafından yürütülen bir deneyin sonuçları, iki faktör hipotezinin en temel varsayımına -girişim tarafından bastırılan çağrışımların fiilen ortadan kalktığı varsayımına- oldukça ciddi bir darbe indirir (Postman ve Stark, 1969). Bu deneyin bir versiyonunda, A - B ve A - C listelerini ezberledikten sonra bir tanıma testi kullanıldı: özneye bir dizi B bileşeni sunuldu ve aralarında belirli bir A bileşenine karşılık gelen birini bulması istendi. . Denekten uygun B-bileşenlerini hatırlaması beklenmiyordu; onları tanıması yeterliydi. Sonuçlar tamamen beklenmedikti: geriye dönük frenleme önemsizdi.
A-B listesindeki cevapların hiç bozulmadığı, ancak tanıma yöntemiyle doğrulama için hazır olduğu izlenimi yaratıldı. Bu nedenle, A-B ve A-C listelerini öğrendikten sonra, B bileşenlerini yeniden oluşturmak ve bunları uyaranlarla (A) ilişkilendirmemek zordu. Diğer bir deyişle, deneklerin DAK-7'nin A-B listesinden eşleştirilmiş bir çağrışım olduğunu hatırlamaları hiç de zor olmadı; DAV bileşeni sunulduktan sonra bileşen 7'yi hatırlamakta zorlandılar.
Eşli çağrışımları öğrenirken, öznenin özellikle reaksiyon bileşenlerini yeniden üretmeyi öğrendiği fikri kendi içinde yeni değildi. Bununla birlikte, Postman ve Stark'ın proaktif ve geriye dönük ketlemenin çağrışımsal bağlantıların kaybından ziyade yanıtları hatırlayamamaya bağlı olduğu deneyinden türetilen fikir, nispeten yeni bir şeydir. Görünüşe göre reaksiyon bileşenlerinin kendileri de kaybolmamış. Sadece geri çağırma gerçekleştiğinde, müsait değiller. Gerçekten hafızadan kayboldularsa, tanıma testlerinin bu kadar şaşırtıcı sonuçlar vermesi pek olası değildir.
REAKSİYON SETLERİNİN GİRİŞİMİ
Burada ele aldığımız son hipotez olan tepki kümeleri girişim hipotezi (Postman a.o., 1968), Postman ve Stark tarafından elde edilen sonuçlarla uyumludur. Bu hipoteze göre müdahale, tepkiler arasında bir tür rekabettir, ancak bireysel tepkiler arasında değil, tüm grupları arasında; örneğin, A-B listesinin tüm B-bileşenleri seti, A-C listesinin tüm C-bileşenleri seti ile rekabet eder.
A-B ve A-C ile yapılan deneylerde olayların aşağıdaki gibi ilerlediği varsayılmıştır. İlk olarak, bir A-B listesi öğrenmek, bir dizi B-tepkisini etkinleştirir; bu durumda, diğer reaksiyonlar nedeniyle daha fazla kullanılabilirliklerini sağlayan bir tür seçici mekanizma etkinleştirilir. Daha sonra, A-C listesinin ezberlenmesi sırasında bu mekanizma, B-reaksiyonlarını bastırırken C-reaksiyonlarını değiştirir ve etkinleştirir. Ek olarak, seçici mekanizmanın bir miktar ataleti vardır, bu nedenle bir setten diğerine geçiş biraz zaman alır. Bu nedenle, A-B listesine göre kontrol testleri yapılırken, A-C listesinin öğrenilmesinden kısa bir süre sonra geriye dönük inhibisyon gözlemlenir: seçici, C-reaksiyon setini etkinleştirmeye devam eder.
Tepki kümelerinin müdahalesine ilişkin hipotezin özü, girişimin bireysel ilişkiler düzeyinde değil, tüm reaksiyon sistemleri düzeyinde meydana gelmesidir. Hipotez bu ana ifadenin yanı sıra diğer varsayımları da içermektedir. İlk olarak, seçici mekanizmayı "atlamaya" izin verenler gibi doğru koşullar altında, geriye dönük inhibisyonun gözlenmeyeceği varsayılır. Belki de bir tanıma denemesinin kullanılması (Postman ve Stark, 1969'da olduğu gibi) tam da bunu yapar - yanıtlar deneme sırasında sunulduğu ve bu nedenle doğrudan erişilebilir olduğu için seçiciyi atlamayı mümkün kılar. İkincisi, bu hipoteze göre, tutma aralığı sırasında, seçici mekanizmanın ataleti A-C listesini öğrendikten hemen sonra en yüksek olacağından, geriye dönük engelleme derecesi azalmalıdır. Ancak bir süre sonra bu mekanizmanın A-B sistemine geri dönmesi daha kolay olacaktır (spontan iyileşme bununla ilişkilendirilir). Üçüncüsü, bu hipotez, yanıt grupları arasındaki benzerlik arttıkça geriye dönük inhibisyondaki artışı açıklar (yani, C-bileşenleri ve B-bileşenleri arasında daha fazla benzerlik ile daha güçlü etkileşim). Bu gerçek, seçici mekanizmanın liste içindeki benzerliklere duyarlılığını varsayarak açıklanır. Özellikle, reaksiyonları seçen bir mekanizmanın, ancak uygulanabileceği iyi tanımlanmış bir dizi reaksiyon varsa, yani seçim için net kriterler varsa etkili olacağı varsayılır. Anahtarlama mekanizması, reaksiyonların belirli bir kümeye ait olup olmadığını belirleyen bazı yeni kriterler tarafından yönlendirilmelidir. Bu nedenle, iki reaksiyon seti çok fazla farklılık göstermiyorsa, seçici mevcut sette her iki reaksiyonu da içerebilir.
Tepki kümesi hipotezi, iki faktörlü hipotezle keskin bir tezat oluşturmamalıdır, çünkü her ikisi de reaksiyon rekabeti fikri gibi (bu rekabetin farklı seviyelerde gerçekleştiği varsayılsa da) bir dizi ortak fikir içerir. Şu soruyu sormanın zamanı geldi: Girişim teorisi, A-B ve A-C listeleriyle yapılan deneyler dışında, uzun süreli hafıza unutmasını genel olarak ne ölçüde açıklıyor? Bu sorunun cevabı pek cesaret verici değil ama aynı zamanda çok da cesaret kırıcı olarak değerlendirilemez.
Bu konuya açıklık getirmek için yapılan bazı çalışmalarda laboratuvarda edinilen bilgilerin laboratuvar dışında nasıl unutulduğu araştırılmaya çalışılmıştır. Örneğin, deneklere sık tekrarlanan kelimelerin listelerini ezberlemeleri verildi.
(günlük yaşamda yaygın) ve nadir sözcükler (Underwood ve Postman, 1960). Olağan sözcük listelerini unutmanın daha belirgin olacağı varsayılmıştır, çünkü deneklerin bu sözcükleri günlük olarak kullanma olasılıkları daha yüksektir. Sıklıkla tekrarlanan bu kelimelerin alışılmış kullanımına karşılık gelen laboratuvar dışı çağrışımlar, girişim yaratmalı ve laboratuvarda ezberlenen listelerin unutulmasına yol açmalıdır. Elde edilen sonuçlar, hiçbir şekilde belirleyici olarak kabul edilemese de, bu varsayımı bir dereceye kadar doğruladı.
Diğer deneylerde (Slamecka, 1966), deneklerin laboratuvar dışında geliştirilen çağrışımları parçalamalarını sağlamak için tam tersi bir görev belirlendi. İlk olarak, serbest çağrışım testlerinde uyaranlara tepkiler ortaya çıkarıldı (bu testlerde, deneğe bir öğe, örneğin COPTKA sunulur ve akla gelen ilk kelimeyi, örneğin "köpek") söylemesi istenir. . Çağrışımları uyandırmak için kullanılan uyaranlar daha sonra yeni yanıtlarla birlikte eşleştirilmiş çağrışımlar listesine eklendi (örneğin, COPT - KÖPEK yerine KEDİ - BE SURE); bu durumda, neredeyse hiç girişim gözlenmedi. Serbest çağrışımlar için yapılan kontrol testlerinde deneklerin hiçbir şey unutmadığı ortaya çıktı. Laboratuvara bir kedi-köpek ilişkisi ile gelirlerse, o zaman bir kedi-emin olun ilişkisi ile birkaç deneme, köpeklerin ve kedilerin birbiriyle akraba olduğunu unutturmaz.
Denekler kendilerini gerçek bir dünya ortamında bulduklarında laboratuvar malzemesini unutturmaya çalışırken elde edilen sonuçların bir kısmının, reaksiyon seti girişim hipotezine atıfta bulunularak açıklanması mümkündür. Günlük yaşama özgü tepkilerin, laboratuvar tepkimelerinden farklı bir dizi tepkimede depolanabileceği ve denek laboratuvardan çıkar çıkmaz kolayca geri kazanılabileceği varsayılabilir. Bu nedenle, gerçek hayatta unutma olgusunu açıklamada müdahalenin rolü hakkında bir fikir edinmek için, laboratuvarda gerçek dünyanın koşullarını simüle etmek gerekir. Gerçekleştirilen prosedürleri kontrol etmek için laboratuvar tarafından sağlanan tüm olasılıkları (ne olursa olsun) kullanmalıyız, ancak aynı zamanda unutmayı deneyin çerçevesi dışında meydana geldiği biçimde simüle etmek istiyoruz. Ayrıca, deneyimizi kısmen laboratuvar ortamında kısmen laboratuvar dışında yaparak parçalara ayıramayız, çünkü bu, farklı reaksiyon dizileri nedeniyle komplikasyonlara yol açacaktır.
UNUTMAK VE DOĞAL DİL
Literatürde, bizi ilgilendiren ana soruna ışık tutan bir dizi deneysel çalışma bulmak mümkündür: gerçek dünyada unutmanın doğası nedir? Genellikle bu tür deneyler, çift ilişkilendirme yönteminin ötesine geçer: doğal dil materyali üzerinde gerçekleştirilirler. Doğal dil ile, özneye özgü dilde doğal konuşmanın bir parçası elde edilecek şekilde birbirine bağlanan sözcükleri kastediyoruz. Bu tür bir materyali kullanarak, unutma çalışmasına daha doğal bir şekilde yaklaşmanın - gerçeği gerçekten taklit eden koşullar yaratmak için - mümkün olacağı varsayılmaktadır. Bu türden bazı tipik araştırmalara bakalım.
Bu çalışmaları incelerken, her şeyden önce, bir İngilizce metnin unutulmasının çoğunlukla A-B, A-C tipi hafif gizlenmiş bir deney çerçevesinde, yani listeleri ezberleme yöntemine yakın bir yöntem kullanılarak incelendiğini göreceğiz. Örneğin, deneklere bir dizi ardışık nesir pasajı okunur ve ardından bu pasajların genel anlamının bir ezberleme testi kullanılarak hafıza test edilir (Slamecka, 1960a, b); ancak neredeyse hiç unutma tespit edilemez. Böyle bir sonuç, A-B, A-C listelerini ezberlerken gözlemlenenden çok uzaktır. Bununla birlikte, İngilizce bir metnin parçaları A-B, A-C ezberleme listelerine yakın koşullar altında uyarıcı materyal olarak kullanıldığında, girişim fenomeni gözlemlenebilir. Örneğin, Kraus (Grouse, 1971) deneklere kurgusal bir karakterin biyografisinden bir pasajı ezberlemeleri için verdi; bu pasaj, bu karakterin doğum yeri ve zamanı, babasının mesleği, ebeveynlerinin ölümü hakkında bilgi vb. Daha sonra deneklere içerik olarak birinciye yakın iki pasaj daha okundu. Ayrıca doğası gereği biyografiktiler - aslında, ayrıntılardaki bazı farklılıklar dışında, ilk iki pasajla yaklaşık olarak aynı kelimelerle ifade edilmişlerdi: farklı isimler ve doğum tarihleri, ebeveynlerin ölümüyle ilgili biraz farklı koşullar, vb. Daha sonra ilk pasajın ezberlenmesi, deneklere ilkine kıyasla sonraki iki metinde değişen belirli gerçekler hakkında sorular sorarak test edildi. Bu deneylerde denekler, ilk pasajın sunumu ile onun hatırlanması arasında ondan tamamen farklı iki pasaj okunan kontrol grubuna göre çok daha az bilgi hatırladılar. Böylece, bu durumda, doğal bir dil ortamında (İngilizce nesir) geriye dönük engelleme ortaya çıktı. Görünüşe göre, bu tür bir yöntem etkili kabul edilebilir, çünkü hatırlanacak pasaj ve değiştirilen pasajlar genel olarak aynı kelimelerle ifade edilir (A-B listesindeki A-bileşenleri gibi) ve sadece birkaç belirli kelimede farklılık gösterir ( A-C listesine geçişe çok benzer). Bu nedenle, girişim etkileri, yalnızca proaktif ve retroaktif inhibisyon üzerindeki tipik deneylere benzer durumlarda ortaya çıkar, ancak diğer koşullarda ortaya çıkmaz.
Gerçek dil materyali ile yapılan deneylerde girişimi göstermek için, bu materyali A-B ve A-C listeleriyle aynı şekilde kullanmak gerektiği gerçeğinden nasıl bir sonuç çıkarılabilir? Laboratuvar dışı koşullarda unutmanın, geleneksel girişim deneylerinde gözlemlenen unutmadan farklı olması mümkün mü? Böyle kesin bir sonuca varma özgürlüğüne sahip değiliz. Bunun yerine, gerçek dünyada unutmanın ne olduğuna daha yakından bakalım.
En yaygın bilinen doğal dil unutma deneylerinden biri Bartlett (1932) tarafından gerçekleştirilmiştir. (Bartlet'in kendisi, çalışmasını özellikle unutma çalışmasına yönelik olarak düşünmemiştir, ancak bu, onu burada tartışılan konuyla bağlantılı olarak ele alamayacağımız anlamına gelmez.) Bartlet, deneklerden daha önce okudukları hikayeyi yeniden üretmelerini istedi. . Bu, Kuzey Amerika Kızılderililerinin kabilelerinden birinin "Ruhların Savaşı" adlı bir efsanesiydi (bu efsane ve deneklerden biri tarafından yeniden anlatılması, Şekil 9.6'da gösterilmektedir (aşağıda italik olarak)).
Pirinç. 9.6. "Ruhların Savaşı" efsanesi ve denek tarafından yeniden anlatımı. Aşağıda her iki metnin çevirisi bulunmaktadır.
Sunulan metin
Hayaletlerin Savaşı
Bir gece Egulae'den iki genç adam nehre huni fokları için gittiler ve onlar oradayken hava sisli ve sakin oldu. Sonra savaş naraları duydular ve "Belki bu bir savaş partisidir" diye düşündüler. Kıyıya kaçtılar ve bir kütüğün arkasına saklandılar. Şimdi kanolar geldi ve küreklerin sesini duydular ve onlara doğru gelen bir kano gördüler. Kanoda beş adam vardı ve şöyle dediler:
"Ne düşünüyorsun? Seni de götürmek istiyoruz. İnsanlara karşı savaşmak için nehrin yukarısına gidiyoruz."
Genç adamlardan biri: "Okum yok" dedi.
"Oklar kanoda" dediler.
"Gitmeyeceğim. Ölebilirim. Akrabalarım nereye gittiğimi bilmiyor. Ama sen" dedi diğerine dönerek "onlarla gidebilirsin".
Bunun üzerine gençlerden biri gitti, diğeri ise evine döndü.
Ve savaşçılar nehrin yukarısındaki Kalanna'nın diğer tarafındaki bir kasabaya gittiler. İnsanlar suya indi ve savaşmaya başladılar ve birçoğu öldürüldü. Ama kısa süre sonra genç adam, savaşçılardan birinin "Çabuk, hadi eve gidelim: Indeam vuruldu" dediğini duydu. Şimdi şöyle düşündü: "Ah, bunlar hayalet." Kendini hasta hissetmiyordu ama vurulduğunu söylediler.
Böylece kanolar Egulac'a geri döndü ve genç adam karaya çıkıp evine gitti ve ateş yaktı. Ve herkese anlattı ve şöyle dedi:
"İşte hayaletlere eşlik ettim ve savaşmaya gittik. Birçok arkadaşımız öldü ve bize saldıranların çoğu öldürüldü. Vuruldum dediler,
ve hasta hissetmedim".
Hepsini anlattı ve sonra sustu. Güneş doğunca yere düştü. Ağzından siyah bir şey çıktı. Aşaması çarpık hale geldi. İnsanlar ayağa fırladı ve ağladı.
Ölmüştü.
Konuyu yeniden anlatmak
İki genç, fok avlamaya başlamak üzere bir nehrin kıyısında duruyorlardı ki, içinde beş adam olan bir tekne göründü. Hepsi savaş için silahlanmıştı.
Gençler ilk başta korkmuşlardı, ancak adamlar gelip diğer yakadaki bazı düşmanlarla savaşmalarına yardım etmelerini istediler. Bir genç, akrabaları onun için endişeleneceği için gelemeyeceğini söyledi; diğeri gideceğini söyledi ve tekneye girdi.
Akşam kulübesine döndü ve arkadaşlarına bir savaşta olduğunu söyledi. Pek çok kişi öldürülmüş ve o bir okla yaralanmıştı; herhangi bir ağrı hissetmediğini söyledi. Ona bir hayalet savaşında savaşmış olması gerektiğini söylediler. Sonra tuhaf biri olduğunu hatırladı ve çok heyecanlandı.
Ancak sabah hastalandı ve arkadaşları etrafına toplandı; yere düştü ve yüzü çok solgunlaştı. Sonra kıvrandı ve çığlık attı ve arkadaşları dehşetle doldu. Sonunda sakinleşti. Ağzından sert ve siyah bir şey çıktı ve buruşmuş ve ölü yatıyordu.
Ruh Savaşı
Bir gece Egulac'tan iki genç fok avlamak için nehre gitti; nehir üzerindeyken bir sis çöktü ve ortalık çok sessizleşti. Aniden savaş naraları duydular ve "Bu bir savaşçı çetesi olmalı" diye düşündüler. Karaya koştular ve bir kütüğün arkasına saklandılar. Suyun üzerinde birkaç kano belirdi; avcılar küreklerin sesini duydular ve bir kanonun kendilerine yaklaştığını gördüler. Şöyle
Kanoda beş adam vardı ve onlara şu sözlerle hitap ettiler:
Bizimle gelmeyecek misin? Sizi yanımıza almak isteriz. Oradaki insanlarla savaşmak için nehrin yukarısına gidiyoruz.
Genç avcılardan biri dedi ki:
Oklarım yok.
Kanoda oklar var, diye yanıtladı yeni gelenler.
seninle gelmeyeceğim öldürülebilirim. ailem bilmiyor
nereye gittim. Ama sen,” arkadaşına döndü, “onlarla gidebilirsin.
Ve genç adamlardan biri askerlerle birlikte yelken açtı ve diğeri eve döndü.
Savaşçılar nehrin yukarısına, Kalama'nın diğer tarafındaki bir köye doğru yelken açtılar. İnsanlar suya indi ve bir savaş başladı; birçok kişi öldü. Aniden, genç avcı askerlerden birinin şöyle dediğini duydu: "Eve gidin, bu Kızılderili yaralandı." Sonra evet diye düşündü.
bu ruhlar. Hiç acı hissetmedi ama okla vurulduğunu söylediler. Kanolar Egulac'a geri döndü ve genç Kızılderili karaya çıktı, eve gitti ve ateş yaktı. Ve herkese anlattı;
İşte böyleydi. Ruhlarla ilgilendim ve savaşa girdik.
Birçoğumuz öldürüldü ve bize saldıranların birçoğu öldürüldü. Ruhlar yaralandığımı söylediler ama acı hissetmedim.
Bütün bunları anlattı ve sustu. Güneş doğunca yere düştü. Ağzından siyah bir şey çıktı. Yüzü buruştu. İnsanlar ayağa fırladı ve bağırmaya başladı.
Ölmüştü.
Konuyu yeniden anlatmak
İki genç adam nehir kenarında fok avlamak üzere dururken, aniden içinde beş kişinin oturduğu bir tekne belirdi. Hepsi silahlıydı. Gençler ilk başta korkmuşlardı, ancak yeni gelenler onlardan yanlarında gitmelerini ve diğer taraftaki bazı düşmanlarla savaşmalarına yardım etmelerini istedi. Gençlerden biri, ailesinin endişeleneceği için gidemeyeceğini söyledi; diğeri gideceğini söyleyip kayığa bindi.
Akşam kulübesine döndü ve arkadaşlarına savaşa katıldığını söyledi. Çok sayıda kişi öldü ve o bir okla yaralandı; herhangi bir ağrı hissetmediğini söyledi. Arkadaşları ona görünüşe göre ruhların savaşına katıldığını söylediler. Sonra her şeyin bir şekilde garip olduğunu hatırladı ve çok heyecanlandı.
Sabah kendini hasta hissetti ve arkadaşları onun etrafında toplandı; düştü ve yüzü çok solgunlaştı. Sonra kıvranmaya ve çığlık atmaya başladı ve arkadaşları dehşete kapıldı. Sonunda sakinleşti. Ağzından sert ve siyah bir şey çıktı ve çömelmiş, ölü yatıyordu.
Alıntılanan metinlerden de anlaşılacağı gibi, Bartlet'in Kızılderili olmayan tebaası efsaneyi yeniden anlatmaya çalıştıklarında oldukça tipik hatalar yaptılar. Orijinal anlatı, olası olaylar ve bunların mantıksal gelişimi hakkındaki olağan fikirlerine uymadığından, efsaneyi yeniden anlatırken ve çarpıtırken yaptıkları hatalar, efsaneyi yeniden yapma ve kendi açılarından “normal” bir forma getirme arzularından kaynaklanıyordu. görüş açısı. Bartlet'e göre deneklerin bu tür yanılgıları, efsaneyi ilk okuduklarında kendilerine efsanenin genel temasına ilişkin belirli bir zihinsel şema veya soyut fikir oluşturmalarından kaynaklanmaktadır. Böyle bir şema kaçınılmaz olarak bireysel inançlar, duygular vb. sistemine "uymak" zorundaydı. bu da onun yeniden anlatımında gözlemlenen karakteristik değişikliklere yol açtı. Kısacası deneklerin efsaneyi mevcut DP yapılarına uydurmaya çalıştıkları sonucuna varabiliriz. Efsanenin bu yapıya uymayan, uyum sağlamayan, hatta müdahale eden bazı yönlerini “unuttular”.
Bartlet'in gösterdiği gibi, öğrenilen materyalin gerçek bilgi yüküne göre çarpıtılması bu türden tek örnek değildir. Son çalışmaların sonuçları, metin materyalini ezberlerken, deneklerin genel bir "konu" hakkında zihinsel bir fikir oluşturduklarını ve ardından herhangi bir kelimeyi hatırlamaları, soruları yanıtlamaları, hafızadaki gerçekleri geri yüklemeleri istendiğinde bu fikri kullandıklarını göstermektedir.
Sachs (1967), bu ortak tema hafıza etkisinin klasik bir örneğini tanımlamıştır. Deneklere manyetik bir kasete kaydedilen alıntıları dinlemelerini sağladı. Denekler böyle bir pasajda yer alan cümlelerden birini dinledikten sonra bir noktada buna benzer bir cümle kendilerine sunuldu. Bu yeni cümle, pasajdaki ile aynı veya biraz değiştirilmiş olabilir. Değişiklikler ya sözdizimseldi, anlamı etkilemedi ya da anlamsal, yani anlamsaldı. Örneğin, orijinal cümle "Oğlan kızı dövdü" ise, o zaman sözdizimsel bir değişiklikten sonra "Kız oğlan tarafından dövüldü" olabilir ve anlamsal değişiklik "Kız çocuğu dövdü" cümlesine yol açardı. oğlan." Sachs, değiştirilen cümle orijinal cümleden hemen sonra sunulursa, deneklerin hemen hemen her değişikliği kolayca tespit ettiğini buldu ( görünüşe göre bunun nedeni, bu durumda CP'de bulunan ve orijinal cümleyi içermesi gereken bilgilerin kullanılmasıydı. tamamı). Bununla birlikte, belirli bir cümlenin orijinal ve değiştirilmiş biçiminde sunumu arasında, konu diğer sözlü materyalleri dinlediyse, anlamsal değişiklikleri tamamen sözdizimsel olanlardan çok daha kolay fark etti; cümleyi biçim olarak çarpıtmak mümkündü ve konu anlam değişikliklerine hemen dikkat etmesine rağmen bunu fark etmedi.
Sachs'ın deneyleri bize "doğal" konuşma malzemesinin unutulmasına bir başka örnek daha veriyor. Bu durumda (Bartlet'in deneyinin aksine) unutulan anlam değil, tam olarak ifade edildiği kelimelerdir. Yine de, Sacks'in unutması, Bartlet'in deneylerinde gözlemlenene benzer, çünkü burada da orijinal girdi mesajında bir miktar bozulma vardır. Sacks'te, DP'de konulan deneklerin dinledikleri pasajın anlamı hakkında bir fikir edindikleri ve ifade edildiği kelimeleri unuttukları izlenimi ediniliyor. Tam biçimi değil, anlamı hatırlama gerçeği, tam kelimeleri hatırlama zamanı geldiğinde gün ışığına çıktı. Ancak bu durumda (Bartlet'in deneklerinin yaptığı gibi) anlamı çarpıtmaya gerek yoktu çünkü bu DP'nin yapısıyla çelişmiyordu. Bu, kabul edilen anlamda müdahale olarak kabul edilebilir mi? Zorlu. Belki de bu tür bir unutmayı bir müdahale olarak değerlendirebiliriz, ancak yalnızca konunun dilbilimsel bilgisinin onun hafızasındaki kesin formülasyonların korunmasına "müdahale edebileceği" (engelleyebileceği) ölçüde. Başka bir deyişle, denekler, genel olarak, anlam korunduğu sürece belirli bir cümlenin ifadesinin o kadar önemli olmadığını bilebilir. Bu durumu bilmek, onları kesin formülasyonları değil, anlamı akıllarında tutmaya teşvik eder. Bu fikrin lehine bazı kanıtlar vardır, çünkü deneklerin ihtiyaç duymaları halinde bir cümlenin tam olarak ifadesini hafızalarında saklayabildiklerini göstermek zor değildir (Anderson ve Bower, 1973; Wanner, 1968).
Şimdiye kadar ele aldığımız sonuçların gösterdiği gibi, "doğal" metin unutmanın, proaktif ve geriye dönük engelleme deneylerinde gözlemlenen müdahale kaynaklı unutmayla çok az ilgisi var gibi görünüyor. Burada açıklanan cümlelerin ve pasajların unutulması, müdahaleye yakın bazı fenomenlere atfedilebilir, ancak yalnızca bu kavram önemli ölçüde genişletilirse. Burada vardığımız şeyin, yok olma, tepkilerin rekabeti ve tepki kümelerinin rekabeti hipotezleriyle çok az ortak noktası var. Unutmanın müdahale teorisine, bazı durumlarda, bir şeyi "unutan" deneklerin, başlangıçta sunulan malzemeye kıyasla görünüşe göre daha fazla ve daha az değil, gerçekten hatırladıkları gerçeğiyle de karşı çıkıyor. Bu tür bir "unutma", doğal konuşma materyali üzerinde bellek çalışmasına yönelik yapıcı bir yaklaşımın temelini oluşturur - Bransford, Barclay, Franks ve onların işbirlikçileri tarafından benimsenen bir yaklaşım.
Daha önce bahsedildiği gibi (Bölüm 4), Franks ve Bransford (Franks.a.Bransford, 1971), deneklere bir dizi karmaşık figür görsel olarak sunulduğunda, görünüşe göre bu figürleri kullandıkları bir tür soyut prototipe zihinsel olarak indirgediklerini gösterdiler. sonra tanıma için. Böylece, kontrol figürlerini, bu rakamların daha önce sunulup sunulmadığına bakılmaksızın, prototipe olan yakınlıklarından tanıdılar. Cümle belleği için de benzer bir etki bulundu (Bransford ve Franks, 1971). Bu deneylerdeki ilk malzeme, dört basit cümleden oluşan bir gruptu, örneğin: 1) "Mutfakta karıncalar vardı"; 2) "Masada jöle vardı"; 3) "Jöle tatlıydı"; 4) "Karıncalar jöleyi yedi." İkisini, üçünü veya dördünü bir araya getirerek yeni teklifler alabilirsiniz. Örneğin, 1. ve 4. kombinasyonu şunu verir: "Mutfaktaki karıncalar jöleyi yedi." 3. ve 4. kombinasyonu - "Karıncalar tatlı jöleyi yediler." 2., 3. ve 4.'den şunları alabilirsiniz: "Karıncalar masanın üzerindeki tatlı jöleyi yediler." Ve dördü de verecek: "Mutfaktaki karıncalar masanın üzerindeki tatlı jöleyi yediler." Son cümle, orijinal dört cümlede yer alan tüm bilgileri içerdiğinden, Franks ve Bransford'un görsel hafıza deneylerindeki prototip figürlere karşılık gelir.
Daha sonra Bransford ve Franks, deneklere dört basit başlangıç cümlesinden oluşturulabilecek cümlelerin bir kısmını sundu. Bu bölüm şunları içeriyordu: ilk dört tekliften iki teklif; her biri iki orijinal cümleden oluşan iki cümle; iki, üç orijinal olandan oluşur. Bu cümleler, dört orijinal basit cümlenin tümü burada şu veya bu kombinasyonla sunulacak şekilde seçildi ve karıncalar, mutfaklar ve jöle ile hiçbir ilgisi olmayan, ancak başka kümelerden cümleler serpiştirilerek sunuldu. aynı şekilde. Daha sonra bir tanıma testi yapıldı ve deneklerden yargılarının doğruluğuna ne ölçüde güvendiklerini belirtmeleri istendi. Elde edilen sonuçlar, şekillerin görsel sunumuyla yapılan deneyin sonuçlarına benzerdi: en büyük güvene sahip denekler, daha önce görüldüğü varsayılan, dört basit cümlenin hepsinin birleştirildiği prototip cümle olarak "tanıdı". Bu arada, onlara asla sunulmadı! Ayrıca denekler, kendi değerlendirmelerine göre, üç temel formun bir araya getirildiği cümleleri, ikisinin bir arada kullanıldığı cümlelere ve ikinin bir arada kullanıldığı cümlelerin her bir orijinal cümlenin ayrı ayrı kullanılmasına göre daha güvenli bir şekilde tanımışlardır. Kısacası cümlenin "tanınması" için deneklerin cümleyi gerçekten görüp görmemesi önemli değildi. Önemli olan, sunulan cümlenin parçası olan orijinal cümlelerin sayısıydı: bu sayı ne kadar büyükse, "tanınma" olasılığı o kadar yüksek.
Bransford ve Franks'a göre bu sonuçlar, deneklerin kendilerine sunulan cümlelerin birleşik içeriğini soyutlamaları ve hafızalarında saklamalarından kaynaklanıyordu. Kendilerine sunulan hammaddelerden kendilerine zihinsel bir temsil "yarattılar" ve bu temsil, başlangıçta sunulan bilgiler üzerine inşa edildi, ancak bununla sınırlı değildi. Burada yine sunulan bilgilerin belirli özelliklerini hatırlayamama ile karşılaşıyoruz. Ve yine bu bilginin bozulmasını görebilirsiniz; bu durumda, daha izole gerçeklerden "prototipik" bir semantik temsilin yaratılmasına yol açar.
Diğer benzer deneylerde (Barclay, 1973; Bransford a.o., 1972), deneklerin bir cümlede kendilerine verilen bilgilerin ötesine geçebildiklerini ve sadece cümlenin kendisi hakkında değil, sonuçları hakkında da bilgi sahibi olabildiklerini gösteren veriler elde edilmiştir. Örneğin, Bransford ve ekibi konuyu "Üç kaplumbağa yüzen bir kütüğün üzerinde dinleniyordu ve altlarında bir balık yüzdü" cümlesiyle sunmuş ve bunu "Üç kaplumbağa yüzen bir kütüğün üzerinde dinleniyordu ve bir balık yüzdü" şeklinde tanıdı. altında", "Altlarında" "altında" ile değiştirmek, orijinal cümleden şu sonuçtur: kaplumbağalar bir kütüğün üzerine oturursa, kaplumbağaların (onların) altında yüzen balıkların kütüğün (o) altında yüzdüğünü biliyoruz. . Orijinal cümlede "Üç kaplumbağa yüzen bir kütüğün yanında dinleniyordu ve altlarında bir balık yüzüyordu" ifadesini verirsek ve kontrolde "onları" "onu" ile değiştirirsek, o zaman benzer bir tanıma hatası gözlenmez: kelime "yakın" böyle bir yoruma izin vermez. Balık, kütüğün yakınında bulunan kaplumbağaların altından yüzdüyse, balığın kütüğün altında yüzdüğünün garantisi yoktur. Bu sonuçlar, deneklerin belirli bir cümleyi dinlerken, onu oluşturan kelimelerden daha fazlasını hafızalarına kaydettiklerini bir kez daha göstermektedir. Hafızalarında, görünüşe göre , cümlenin içeriği (ancak tam olarak ifade edilemeyen) ve hatta bu içerikten çıkarılabilecek sonuçlar saklanmaktadır. Bartlet'in terminolojisini kullanırsak, cümlenin "şemasını" belleklerinde sakladıklarını söyleyebiliriz. Bu nedenle, bir cümle söz konusu olduğunda unutmak, PT ve RT'ye pek benzemez. "Unutmak" burada basitçe bir bilgi parçasının kaybı olarak ifade edilmemiştir; aksine cümle bir miktar ilave ile hafızada saklanır.
GİRİŞİM: BAZI SONUÇLAR
Şimdi unutmanın müdahale teorisi hakkında bildiklerimizi bir kez daha gözden geçirmenin zamanı geldi. Her şeyden önce, bu teorinin şu ya da bu biçimde, A-B ve A-C listeleriyle yapılan deneylerde gözlemlenen tipik fenomenlerin çoğunu açıklayabildiğini biliyoruz. Ayrıca, bu teorinin "müdahale" terimini çok genel bir anlamda kullanarak biraz genişletilirse, o zaman tutarlı sözel materyalin unutulmasını bir dereceye kadar anlamaya izin vereceğini biliyoruz, ancak deneylerde en uygun olduğu durumlarda. bu tür malzemelerle A-B, A-C yöntemi biraz gizlenmiş bir biçimde kullanılır. Son olarak, bu tür materyallerin ezberlenmesi ve yeniden üretilmesiyle ilgili bazı fenomenlerin girişim teorisi için zorluklar yarattığını biliyoruz. Yani. örneğin müdahale, deneklerin cümleleri dinleyerek, formüle edildikleri kelimeleri değil de bu cümlelerden kaynaklanan sonuçları neden hatırladıklarını açıklamaya izin vermez. Kısacası, girişim kuramının bir takım özel unutma biçimlerini açıkladığı gösterilmiş olmasına rağmen, doğal konuşma malzemesiyle yapılan deneylerde elde edilen sonuçların çoğuyla baş edemediği söylenebilir.
Her zamanki biçimleriyle unutmanın müdahale teorisinin, "uyarıcı-tepki" teorisi çerçevesine uyan verileri açıklamak için en uygun olduğu söylenebilir. Örneğin, çift çağrışımlarının başlangıçta doğrudan uyaran ve tepki arasındaki ilişkiyi incelemek için bir araç olarak kullanılması amaçlanmıştı. Bu nedenle, çift ilişkilerini kullanan çalışmaların, bu tür bağlantılar hakkında geleneksel fikirler tarafından üretilen girişim teorilerinin temelinin büyük bir bölümünü oluşturması şaşırtıcı değildir. Bununla birlikte, bu teoriler, cümlelerin ve metin bölümlerinin hafızasını açıklamak için çok daha az uygundur. Bu tür bir bellek, örneğin üzerinde durduğumuz anlamsal bellek kuramları gibi dilbilimsel temele sahip kuramların yardımıyla açıklamaya daha uygundur.
Özellikle, çağrışımsal ağ yapısına sahip AFC gibi bir model, girişim teorisi türlerinden birinin temelini oluşturabilir (Anderson ve Bower, 1973). AFC modelinde geriye dönük engelleme, eşleştirme sürecinin doğasından kaynaklanır (Bölüm 8'de ele alınmıştır). Bu işlemin yardımıyla, DP'de bazı girdi bilgilerine karşılık gelen ifadenin yapısı aranır - bu, DP'den bilgi çıkarma sürecinin ana bileşenidir. DP taraması, giriş ağacının terminal düğümlerine karşılık gelen hücrelerden başlar; bu hücrelerden çıkan yollar inceleme sırasına (öncelik) göre farklılık gösterir. Her hücreden arama işlemi, en yüksek önceliğe sahip olan yollar boyunca başlar ve öncelik sırasına göre DP'de eşleşen bir cümle bulunana kadar veya belirli bir süre geçene kadar devam eder ve ardından arama durur. . Çok uzun süreceği için tüm yolları aramak mümkün değildir. Sıranın, belirli yolların kullanımının göreceli yaşına bağlı olduğunu varsayarsak, geriye dönük bir engelleme mekanizması elde ederiz. Son bilgilerle eşleşen yollar en yüksek önceliğe sahip olacak ve bu tür yollar için yapılan aramalar, daha yakın zamanlarda kullanılmış olan yollara göre daha iyi eşleşmelerle sonuçlanacaktır (bu yollar, daha yeni yollar altında "gömülüdür"). Bu, yeni bilgilerin edinilmesinin daha önce edinilen bilgiler için hafızayı bozduğu ve böylece geriye dönük inhibisyon yarattığı anlamına gelir. Bu ve benzeri girişim mekanizmalarının eklenmesiyle AFC modeli, geleneksel girişim deneylerinin sonuçlarıyla uyumlu hale gelir. Ek olarak, bu model, doğal konuşma materyalinin kodlanmasını ve akılda tutulmasını daha iyi açıklayabilir, çünkü cümle benzeri formlar onda önemli bir rol oynar.
Dolayısıyla, yürütülen deneylerin doğasındaki değişikliklere paralel olarak (ikili çağrışımların ezberlenmesinden cümle grupları için hafıza çalışmasına kadar), unutma teorilerinde değişiklikler oldu. Bu değişikliklerin çoğu, teorileri doğası gereği daha "bilişsel" kılma eğilimindedir ve bu kitabın yazıldığı perspektiften bakıldığında, bu teoriler bilişsel süreçlerin birçok yönünü açıklamada daha yararlı hale gelir.
10. Bölüm
Ezberleme. Kodlama süreçleri
Uzun süreli bellekle ilgili önceki bölümlerde, ifadelerin doğruluğunun test edildiği ve daha önce edinilen bilgilerin unutulduğu temel olarak, onun yapısının ve bu yapı içinde meydana gelen süreçlerin modellerini ele aldık. Bu ve sonraki bölümlerde, DP ile ilgili bir dizi başka süreci tartışacağız.
Bölümde daha önce bahsedildiği gibi. 1, belleğin rolünü yerine getirmesi için üç işlem gereklidir: kodlama, depolama ve geri alma. Her şeyden önce, bilgi kodlanmalıdır. Genel olarak kodlamak", dahili depolamaya uygun bir forma getirmek anlamına gelir. Örneğin, harfler, görsel olarak algılanan özellikleri izole eden ve figürleri arka plandan ayıran işlemler sonucunda ikonik görüntülere kodlanır. Sözlü bilgileri girerken kodlamak bir CP'ye bir "etiket" atamaktan oluşabilir (örneğin, I harfi "ya" sesine dönüştüğünde), bu aynı zamanda yapılandırma sürecini de kullanabilir. Bu nedenle, kodlama bazen çok karmaşık bir işlemdir.
Malzeme bir kez kodlandıktan sonra depolandığı belleğe girer ve malzeme depolanırken başına çeşitli şeyler gelebilir ve bunun sonucunda bazen daha sonra geri çağırmak mümkün olmaz. Genellikle "depolama" kelimesi, depoya yerleştirme süreci de dahil olmak üzere daha geniş bir anlamda kullanılır, yani bununla yalnızca depolamanın kendisini değil, aynı zamanda kodlamayı da anlar. Depolamanın kendisi oldukça pasif bir fenomen olarak görülebileceğinden - kışlık şeyleri yazın bir dolaba depolamak gibi - kodlamayı da bu terime dahil etmek mantıklı görünüyor; burada bazen bu anlamda kullanılıyorsa, bağlamdan ne kastedildiği açıktır.
Son olarak, hafızanın işlevinin üçüncü bir yönü vardır - bilgi alma. Çoğu zaman, bir kişinin bazı bilgileri kodlayıp "depoya koymasına" rağmen, daha sonra bu bilgileri hatırlayamayacağı görülür. Bilgi hala bellekte olabilir, ancak ulaşılamaz. Bu durumda, bilgi çıkarma süreci basitçe çalışmaz. Alma, bellekte saklanan bilgilere erişmek anlamına gelir.
"Kodlama" genellikle duyusal kayıtlarda veya kısa süreli bellekte meydana gelen işlemler olarak adlandırılırken, "depolama" ve "geri alma" çoğunlukla uzun süreli bellek olarak adlandırılır. Bunun nedeni muhtemelen ne duyusal kayıtların ne de CP'nin bilgileri uzun süre saklamamasıdır ve bu nedenle bu depolardan onu çıkarmak ya çok kolay ya da imkansızdır: malzeme ya bunların içinde bulunur ve sonra ona ulaşmak zor değil ya da çoktan kaybetti. DP ile ilgili olarak, hem "kodlama" hem de "depolama" ve "çıkarma" oldukça anlamlı terimlerdir. Bu bölümde, kodlama süreçlerine - DP'de bilgilerin depolanmasına eşlik eden işlemlere - odaklanılacaktır. Burada doğal dilin yardımıyla arabuluculuk ve organizasyon süreçlerini ele alacağız ve Bölüm 1'de. 11 bilgi çıkarma sürecinin teorisini ele alır.
DOĞAL DİL İLE ARABULUCULUK
Kodlamanın önemli rol oynadığı olgulardan biri de doğal dil aracılığıyla aracılık sürecidir. Genel olarak arabuluculuk, bir uyaranın sunumu ile ona verilen dış tepkiler arasındaki ara bağlantıların rolünü oynayan belirli süreçler olarak adlandırılır; bu süreçler uyaranın kendisinden tahmin edilemez (Hebb, 1958). Uyaran-tepki teorisinde, belirli bir uyaranın neden geçmişte doğrudan ilişkili olmadığı yanıtları ortaya çıkardığını açıklamaya gelince, arabuluculuk kavramı esastır. Örneğin, serbest çağrışım görevinde, YEDİ uyaran bileşeni öznede bir "alan" tepkisi uyandırabilir. Uyaran ile tepki arasında başka bir ara bağlantı olduğunu öğrenirsek, böyle bir tepki netleşecektir. "Yedi" kelimesi, "tohum" içsel bir tepkiye neden oldu ve bu da, açık bir tepki haline gelen "tarla" kelimesine yol açtı. Kısacası, içsel tepki aracılık ediyordu: uyaranın, yan çağrışımları uyandırma yeteneği kazanacak şekilde dönüştürülmesine izin veriyordu.
Arabuluculuk sürecinin başka bir örneğini ele alalım. "Uyaran tepkisi" teorisine bağlı olduğunuzu ve deneklerin belirli unsurları hatırlarken nasıl çağrışımlar oluşturduğunu bulmaya çalıştığınızı hayal edin. Ebbinghaus'un ayak izlerini takip ederek, öznenin daha önce hiç görmediği unsurları (anlamsız heceler (ünsüz-ünlü ünsüz veya S-V-S gibi)) seçerek öznenin eski çağrışımları kullanma olasılığını ortadan kaldırabilirsiniz. yeniden biçimlendirmek zorundadır. Bu durumda, S-G-S olarak konu, diğerleriyle birlikte KOSH hecesiyle sunulabilir. Denekten kendisine sunulan heceleri tekrar etmesini ve hatırlamaya çalışmasını istersiniz. Kontrol ederken, KOSH hecesini S-G-S'nin geri kalanından daha iyi hatırladığı ortaya çıktı. Deneğin KOŞ hecesi sunulduğunda "kedi"yi düşündüğünü ve böylece kendisine sunulan kalem sürçmesini değiştirdiğini nasıl bilebilirsiniz?
Bu örnekte denek, S-G-S'yi ezberlemek için arabuluculuk kullandı. Bu, sunulan bilgileri kodlama sürecinde, kendisine sunulan uyaranı değiştirmek için DP'de depolanan bilgileri (yani, KOSH hecesinin "kedi" kelimesinin ilk üç harfiyle çakıştığı bilgisi) kullandığı anlamına gelir. o. Bu tür arabuluculuk çok yaygındır. Örneğin, deneklerden basit tekrarlama yoluyla tamamen mekanik bir şekilde öğe listelerini ezberlemeleri istendiğinde, bunun yerine genellikle arabuluculuğa başvururlar. Daha sonra, uyaranı aracılı biçiminde ve onu değiştirmek için kullandıkları şekilde yeniden üretirler ve sonra bu aracılı biçimin orijinal biçimine kodunu çözerler. Bu, temelde KP'de yapılanmayı tartışırken tartıştığımız sürecin aynısıdır. Özellikle, az önce verilen örnek, doğal dilden (NL) ödünç alınan sözel aracıların kullanımını göstermektedir. NLU'nun adı, DP'den alınan bilgilerin doğal dille ilgili olduğu gerçeğini yansıtır - yazım özellikleri, kelime anlamları, vb. (örneğin, 5. Bölümde tartışılan ve doğal dille ilgili olmayan sayıları yeniden kodlamanın aksine).
Deneklerinin materyali ezbere tekrarlayarak ezberlemesini isteyen bir deneyci için sözlü arabulucuların kullanımı sorunlu olabilse de, bu tür arabulucular kendi başlarına ilginçtir. Arabuluculuk nasıl gerçekleşir? Hafızaya yardımcı olur mu? Hangi durumlarda en etkilidir? Olağan arabuluculuk mekanizmaları nelerdir? Bunlar ve diğer bazı sorular aşağıda tartışılacaktır.
Sözlü aracıların bazen hafızaya gerçekten yardımcı olduğu gerçeğiyle başlayalım. KOSH hecesini ezberlemek için "kedi" kelimesini kullanan denek doğru olanı yaptı, çünkü "kedi" kelimesini KOSH basit hecesinden daha iyi hatırlıyordu. Bununla birlikte, bir uyarı, bu tekniği kullandığınızı unutursanız, kodlama sürecinde aracıların kullanılmasının size pek bir faydası olmayacağıdır. Dolaylı öğeler, yalnızca hem değiştirilmiş biçimleri hem de kullanılan değiştirme yöntemi bellekte korunursa doğru bir şekilde yeniden üretilebilir. "Kedi" kelimesini ezberlemenin ve hecemizi CAT olarak çoğaltmanın ne faydası var? Bu konuya bir dizi deney yapılmıştır.
DERNEKLERİ ÖĞRENİRKEN SÖZEL ARABULUCULUKLARIN KULLANIMI
Montague, Adams ve Kiess (Montague, Adams ve Kiess, 1966), ikili ilişkilendirmelere sahip görevlerde LEI'nin kullanımını inceledi. Eşleştirilmiş öğelerden oluşan bir listeyi ezberlerken denekler, bu tür öğeleri oluşturmaları gerekmese de karşılaştıkları tüm bu tür ara öğeleri yazmak zorunda kaldılar. Örneğin, bir çift RAB-LOM gördüğünde, kişi yazabilir. Test sırasında, deneğe uyaran bileşenleri sunulduğunda, her uyaran için, yalnızca tepkiyi değil, aynı zamanda bu uyaranla bağlantılı olarak sahip olduğu aracı unsuru da (eğer ortaya çıktıysa) hatırlaması gerekiyordu. Daha sonra yazarlar, eşleştirilmiş çağrışımları bu çift için bir arabulucu oluşturulup oluşturulmadığına ve deneğin hatırlayıp hatırlamadığına göre gruplara ayırarak doğru üreme sıklığını belirlediler. Arabulucuların ortaya çıkmadığı durumlarda, deneklerin ortalama olarak "reaksiyon bileşenlerinin yalnızca% 6'sını doğru şekilde yeniden ürettikleri ortaya çıktı. Aracıların oluşumu bildirildiğinde, doğru çoğaltma sıklığı belirgin şekilde arttı" (ortalama olarak, %73'e kadar), ancak yalnızca öznenin hangi aracılar olduğunu hatırlayabildiği durumlarda; hatırlamıyorsa, cevaplarının sadece %2'si doğruydu.
Üremedeki farklılıklara ek olarak, Montagu ve işbirlikçileri, bazı vakaların diğerlerinden daha fazla sözel aracı kullandığını keşfettiler. İlk olarak, eşleştirilmiş çağrışımlar hızlı bir şekilde (çift başına 15 s) ziyade yavaş yavaş (çift başına 30 s) ezbere sunulduğunda aracılar daha sık ortaya çıktı. İkincisi, heceler (С-Г-С) nispeten daha "anlamlı" olduğunda daha sık oluşurlar. Hecelerin anlamlılığı (Noble, 1961), belirli bir özne grubunda sınırlı bir süre içinde belirli bir hece için ortalama olarak oluşan çağrışımların sayısı anlamına gelir. Yüksek SD değerleri (anlamlılık dereceleri), çok sayıda ilişkiye karşılık gelir. Örneğin, WIS gibi bir hece viski, Wisconsin, fısıltı, ıslık vb. ile ilişkilendirilebilir. yüksek bir anlayış düzeyine sahiptir. Düşük CO hecesine bir örnek, GOQ gibi bir şey olabilir. Bu nedenle, belirli bir hece bazı kelimelerle ne kadar kolay ilişkilendirilirse, ikili çağrışım görevlerinde sözel arabulucular oluşturma olasılığı o kadar yüksektir. Arabuluculuk için ne kadar çok zaman tanınırsa, aracı kullanma olasılığı o kadar artar. Bu sonuçlar, esas olarak, aracıların oluşumunun belirli bir süre ve belirli bir "iş" gerektirdiği anlamına gelir; otomatik olarak ve zahmetsizce gerçekleşemez. Özne, belirli bir hece için bir tür arabuluculuk bulmalıdır ve hecenin birçok çağrışımı varsa bunu yapmak daha kolay olsa da (dolayısıyla aracı rolü için birçok aday vardır), tüm bunlar zaman alır.
PRITOOLAK TARAFINDAN OLUŞTURULAN SÖZLÜ ARACILARIN KULLANIMININ "T-STACK" MODELİ
Az önce anlatılan deneyin bir eksikliği var: aracının nasıl oluştuğunu ortaya koymuyor. Aracıların doğru yeniden üretim sıklığını artırdığını ve yaratmak için biraz çaba gerektirdiğini biliyoruz, ancak oluşum mekanizmaları hakkında kesinlikle hiçbir şey bilmiyoruz. Prytulak (1971), bu amaçla kapsamlı araştırmalar yaparak bu soruları açıklığa kavuşturmaya çalıştı. Sözel arabulucular yaratma sürecini, kodlama aşamasına (arabulucunun birincil oluşumu ve uygulaması) ve kod çözme aşamasına (arabulucunun yeniden üretildiğinde orijinal olarak sunulan uyarana dönüşmesi) ayırmaya karar verdi. Bunu yapmak için, deneklerin S-G-S gibi hecelerden oluşturdukları çeşitli aracı türlerini sınıflandırmak için çok ayrıntılı bir sistem geliştirdi.
Prytulak, deneklere bu hecelerden birkaçını göstererek başladı ve onlardan "akla gelen herhangi bir anlamlı şey" için bir kelime, bir deyim, bir kısaltma veya herhangi bir anlamı varsa hecenin kendisi için yazmalarını istedi. Prytulak daha sonra denekler tarafından oluşturulan çeşitli aracı unsurları, aracı yapmak için hece üzerinde yapılması gereken "işlemlerin" türüne göre sınıflandırdı. Bu işlemlerden biri ikamedir: örneğin FET hecesi "G" yerine "p" getirilerek "pet" hecesine dönüştürülebilir. Diğer bir işlem ise hecenin ortasına bir harf eklenerek yapılan dahili ekleme işlemidir. FEL'de "ve", " yakıt" elde edebilirsiniz. Heceden bir harf çıkarmak da mümkündür; bu durumda GOH "go" olur. Prytulak, tebaası tarafından aracı oluşumunun yediye indirilebileceğini buldu. farklı işlemler Bu yedi işlem tek başına veya birbiriyle kombinasyon halinde kullanılabilir. Örneğin, bir önekle (bir kelimenin sonuna bir harf eklenmesi) ikame kombinasyonu kombinasyonu HOZ hecesini "hortum" a çevirebilir. veya Prytulak, denekleri tarafından kullanılan 272 farklı dönüşüm (272 işlem kombinasyonu) buldu.
Aracıların oluşumundan sonra, Pritulak'ın tebaasının her birine tekrar sunuldu ve kodunu çözmeleri, yani onları oluşturduğu heceleri (С-Г-С) geri yüklemeleri istendi. Pritulak, denekler tarafından kurtarılan bu heceleri, onların yardımıyla oluşturulan ara kelimelerin kodunun çözülebildiği durumların yüzdesine bağlı olarak, dönüşümleri belirli bir sırayla düzenlemek için kullandı. Örneğin, eklemeden kaynaklanan aracıların, ortaya çıkan harflerden daha kolay orijinal hecelere dönüştürüldüğü ortaya çıkarsa, bir sonun eklenmesi, bir harfin çıkarılmasından daha yüksek bir sıralamaya sahip olacaktır. Böylece, tüm dönüşümler, tabiri caizse "yararlılık" sırasına göre düzenlendi. Prytulak, derlenmiş listeyi bir T yığını olarak adlandırdı (T, "dönüşüm" anlamına gelir).
Son olarak Prytulak, doğal dili kullanarak bir arabuluculuk modeli oluşturmak için T yığını kavramını kullandı. Bu modele göre, bir heceyi öğrenen bir özne, heceyi T-yığınından en kullanışlı dönüşümden başlayarak kodlar ve uygun tipte bir dönüşüm bulana kadar devam eder - oluşturmak için kullanılabilecek bir belirli bir heceyi ne veya anlamlı bir kelimeye dönüştürür. Bulunan dönüşüm listenin ne kadar aşağısındaysa, ortaya çıkan aracı o kadar az başarılı olacaktır çünkü en az yararlı dönüşümler listenin sonundadır. Orijinal heceyi yeniden üretme zamanı geldiğinde, özne ara kelimenin kodunu çözer. Bunu yapabilmek için hem kelimeyi hem de onun alındığı dönüşümü hatırlaması gerekir. Bu unsurlardan herhangi biri veya her ikisi unutulabilir ve öznenin uygun bir dönüşüm arayışında ne kadar ileri gitmesi gerekiyorsa, orijinal heceyi yeniden üretmede o kadar fazla başarısızlık olacağı varsayılabilir.
Prytulak, seçilen dönüşümü hatırlamanın, onu oluşturan işlemlerin sayısıyla ölçülen karmaşıklığına bağlı olması gerektiğini öne sürdü. Yalnızca bir işlem gerektiren bir dönüşümün hatırlanması, birkaç işlemden oluşan bir dönüşümden muhtemelen daha kolaydır. Ayrıca, bazı işlemler diğerlerine göre daha kolay unutulur gibi görünmektedir . Özellikle, alınan aracı nasıl alındığına dair bir ipucu içeriyorsa, belirli bir işlemin hatırlanması daha olasıdır. Yani, örneğin, denek "lokomosyon" ara kelimesini hatırlamışsa, bu kelimenin büyük bir uzunluğudur ve ilk hecesinin S-G-S olması, S-G-C sonuna eklenerek elde edildiğini gösterebilir ve ardından denek orijinal hecenin "Ioc" olduğunu tahmin edebilir ve rapor edebilir.
Prytulak, T yığını modelini başka birçok şekilde test etti. Çok sayıda S-G-S hecesini, onlar için bir aracı oluşturmak üzere ("yığın derinliği") T yığını boyunca kat edilmesi gereken mesafeye göre karakterize etti. Yığının üst seviyelerinde yer alan heceleri, yani bir aracı elde etmenin çok kolay olduğu heceleri ve daha derin seviyelerde bulunan heceleri buldu. T yığını ve yığın derinliği kavramlarının, eşleştirilmiş çağrışımların öğrenilme hızı, kısa süreli bellekte tutulmaları ve S-G-S'den aracılar elde etmek için gereken süre kadar çeşitli verilerin iyi tahmin edicileri olduğunu buldu.
ARACI OLARAK TEKLİFLER VE GÖRSELLER
Burada dolayımı S-G-S tipi hecelerle ilişkili olarak tartıştık; ancak, anlamsız hecelerden kelime oluşumu hiçbir şekilde tek aracılık örneği değildir, aracı cümlelerin kullanımı ikili çağrışımların öğrenilmesini önemli ölçüde etkileyebilir (Bobrow ve Bower, 1969; Rohwer, 1966). Aracı cümle, eşleştirilmiş çağrışımları cümlelere dönüştürür. Örneğin, BOY-DOOR kelimeleri "oğlan kapıyı kapatır" -ifadesiyle ilişkilendirilebilir. Bunu yaparsanız, daha sonra BOY kelimesi sunulduğunda, "kapıyı" hatırlamak, aracı bir varsayım olmadan çok daha kolay olacaktır. Arabuluculuğun başka bir örneği, Schwartz (Schwartz, 1969) tarafından yürütülen bir deneyde bulunabilir. Deneklere K-DOG, C-KRAN gibi ezberleme listeleri verdi. Deneklere, bileşen reaksiyonları için alışılmış çağrışımlar kullanılarak bu çiftlere aracılık edilebileceği söylendikten sonra, listeleri eskisinden daha hızlı ezberlemeye başladılar. Aynı zamanda, K-DOG bir "kedi-köpeğe", C-KRAN bir "durdurma vincine" vb. dönüştürülebilir. Daha sonra K-? denek şunu hatırladı: "C-cat", "cat-dog" ve cevap verdi: "köpek".
Burada biraz farklı türden başka bir arabuluculuk biçiminden bahsedeceğiz. Göz önünde bulundurduğumuz tüm dolayımlayıcı faktörler sözeldi - bunlar kelimeler, cümleler veya deyimlerdi. Bununla birlikte, zihinsel resimler veya imgeler de arabulucu görevi görebilir. Bölüm 12'de, DP'de zihinsel imgelerin rolü çok daha ayrıntılı olarak ele alınıyor, bu nedenle burada kendimizi bu tür bir arabuluculuk kullanan deneysel bir yöntemin kısa bir açıklamasıyla sınırlayacağız. Bower (1972b), isim çiftlerini ezberleyen deneklerden, her bir çifti oluşturan nesnelerin birbirleriyle etkileşime gireceği zihinsel resimler yaratmalarını istedi. Örneğin, bir KÖPEK-BİSİKLET çifti sunulduğunda, denekler bisiklete binen bir köpeği hayal edebilirler. Deneklerden oluşan kontrol grubuna böyle özel bir talimat verilmedi, sadece bir uyaran verildiğinde tepkiyi yeniden üretmeyi öğrenmeleri istendi. Bu deney çok net sonuçlar verdi: Zihinsel resimler oluşturan grup, kontrol grubundan hatırlamada bir buçuk kat daha etkiliydi. Bu nedenle, özel talimat, görünüşe göre, eşleştirilmiş çağrışımların ezberlenmesini büyük ölçüde kolaylaştırdı. Bir hipoteze göre, zihinsel görüntülerin etkinliği, bir resmin oluşumunun bir sonucu olarak, sunulan iki ismin bir etkileşimin unsurları olarak hafızada birlikte saklanmasıyla açıklanır. Uyarıcı kelimenin daha sonra sunulması üzerine, tüm resim hatırlanır ve bu resim sadece bir uyarıcı bileşeni değil, aynı zamanda bir reaksiyon bileşenini de içerdiğinden, ikincisi kolayca yeniden üretilebilir. Örneğin, DOG kelimesi bisiklete binen bir köpek imajını çağrıştırır, bu da "bisiklet" yanıt kelimesinin hatırlanmasına yol açar. Zihinsel görüntülerin etkisinin bu yorumuna "kavramsal askı" hipotezi denir (Paivio, 1963), çünkü uyaranların zihinsel bir resim oluştururken reaksiyonların asıldığı kancalar gibi davrandığı varsayılır.
Birkaç kodlama sürecini ele aldık: yapılandırma, doğal dil öğeleri aracılığıyla arabuluculuk (S-G-S ile ilgili olarak ve diğer ikili çağrışımların oluşumu durumlarında) ve figüratif aracılık. Tartışacağımız bir sonraki kodlama süreci, serbest hatırlama görevlerinde incelenen organizasyondur .
ÜCRETSİZ HATIRLAMALI ORGANİZASYON
Öncelikle belirtmek gerekir ki "organizasyon" terimi esasen yukarıdaki tüm kodlama süreçlerini kapsamaktadır. Denek, sistematik olarak değiştirmek için girdi bilgileri üzerinde bir tür etki uyguladığında, bu bilgileri düzenlediğini söyleyebiliriz. Bu anlamda örgütlenme algı düzeyinde de gerçekleşebilir. Özne, F harfini onu çevreleyen metin sayfasından ayırdığında, böylece görsel alanı düzenler: FRG harflerini "FRG" ve "UN" olarak ayırdığında ("yapılandırma" başlığı altında tartışılan süreç) , materyali düzenler: "Wisconsin" kelimesini WIS için aracı olarak kullandığında yine bir organizasyondur vb. Bununla birlikte, serbest hatırlama yöntemi, organizasyon süreçlerini incelemek için en doğal durumlardan birini yaratır. Serbest hatırlama şu şekilde karakterize edilir: 1) gerekli tüm bilgilerin tek bir yerde bulunması - DP'de (kelime listelerini hatırlamak, duyusal seviyelerin dışındaki hafıza izlerini kullanırız); 2) konunun örgütsel eğilimlerine göre listedeki kelimeleri yeniden dağıtma özgürlüğü (çünkü bu ücretsiz bir hatırlamadır; 3) genellikle listede yeterli sayıda kelime, yani organize edilebilecek oldukça kapsamlı bir materyal . Tüm bu koşullar, örgütsel süreçlerin incelenmesi için çok elverişlidir. Olağan tanıma göre, serbest hatırlamada organizasyon , sunulan bir listedeki öğelerin sırası ile geri çağrıldıklarındaki sıraları arasında sistematik farklılıklar olduğunda gerçekleşir . Bu tür farklılıkların, özne tarafından üretilen girdi malzemesinin dahili modifikasyonu (organizasyonu) tarafından belirlendiğine inanılmaktadır.
DENEYLE BELİRLENEN ORGANİZASYON THOR
Çoğu zaman, bir organizasyonu serbest hatırlama yoluyla incelerken, deneyi yapan kişinin listeye dahil ettiği kelimelerin seçiminden etkilenir. Böylece bir takım deneylerde (Jenkins a.o., 1958; Jenkins a. Russell, 1952) kelime çiftleri arasındaki ilişki derecesi dikkate alınarak listeler oluşturulmuştur. (İki kelime arasındaki çağrışım derecesi, deneğin serbest çağrışım görevinde bir kelimenin sunumuna yanıt olarak başka bir kelimeyi yeniden üretme sıklığı ile ölçülür. Örneğin, KELEBEK ve GÜVE yüksek oranda ilişkilidir, KELEBEK ve BAHÇE daha az ilişkilidir ve KELEBEK ve KİTAP hiç ilişkili değildir.) Deneylerden birinde Jenkins ve Russell, ERKEK-KADIN, MASA-SANDALYE vb. Daha sonra çiftleri ayırdılar, tüm kelimeleri karıştırdılar ve onları 48 serbest hatırlama kelimesinden oluşan bir liste olarak rastgele sundular. Yeniden üretim sırasında, eşleştirilmiş kelimelerin yeniden birleştirme eğilimi gösterdiği ortaya çıktı: yüksek oranda ilişkili kelimeler daha sık birlikte yeniden üretildi. Listedeki masa ve sandalye kelimeleri 17 başka kelime ile ayrılabilirdi, ancak denekler bunları sıklıkla arka arkaya adlandırdı. Ek olarak, Jenkins, Mink ve Russell, böyle bir listedeki kelime çiftleri arasındaki ilişki derecesi ne kadar yüksekse, genel olarak doğru çoğaltma yüzdesinin o kadar yüksek olduğunu ve ilişkili kelimelerin o kadar sık birlikte hatırlandığını buldular. Böylece, kelimeler arasındaki ilişkinin hem hatırlamanın etkinliğini hem de modunu etkilediğini görüyoruz. Görünüşe göre özne listeyi "düzenledi" - onu kelimeler arasındaki ilişkileri kullanacak şekilde değiştirdi. Tıpkı sunulan S-G-S'nin orijinal haliyle değil, bir ara kelime şeklinde hafızada saklanabilmesi gibi, listenin sunulduğu biçimde kodlanmadığına dair güçlü kanıtlarımız var.
Şimdi şu soru sorulabilir: Ücretsiz geri çağırma için bir listenin düzenlenmesinden bir kodlama süreci olarak bahsetmek doğru mudur? Konu sunumu sırasında listeyi hiçbir şekilde değiştirmemiş olabilir: DP'nin yapısı, kodlamanın yanı sıra başka bir şekilde geri çağrılmasını etkileyebilir. Örneğin, DP'de birlikte saklandıkları için yüksek derece ile ilişkili kelimelerin birlikte yeniden üretilmesi mümkündür , böylece alındığında özne onları aynı anda bulur. Bu soru, organizasyon teorisinin savunucularının ilgisini çekmiştir ve daha sonra göreceğimiz gibi, kodlama sırasında bilinen bir organizasyonun ortaya çıkması muhtemeldir.
Ücretsiz hatırlama listesinde dağılmış eşleşen kelimeler arasındaki ilişkilerin, listedeki kelimelerin "düzenli" hatırlanmasına yol açabileceğini gördük. Ancak daha da ileri gidebiliriz - listemize çiftleri değil, ilişkili kelime gruplarını dahil etmek . Bu fikrin başarılı bir şekilde kullanılmasına bir örnek, aynı sınıftaki nesneler anlamına gelen kelimeler listesine dahil edilmesidir - listede sunulan sınıfların her biri için bu tür birkaç kelime. Örneğin, "hayvanlar" sınıfının birkaç üyesini dahil edebilirsiniz: KÖPEK, KEDİ, KUŞ, BALIK vb. veya bu sınıfın alt sınıflarından birinin birkaç temsilcisi, örneğin balık: ALABALIK, TUNA, SASAN, KOKU, SARDALYA vb., listeyi derlerken diğer sınıfların temsilcileriyle karıştırarak. Deneyler, ücretsiz hatırlama için böyle bir liste bileşiminin, ikili çağrışımların etkisine çok benzer bir etkiye sahip olduğunu göstermiştir.
Bousfıld (1951, 1953) serbest hatırlama deneylerinde sınıflandırılabilir listeleri şu şekilde kullanmıştır. Bir deneyde, her sınıftan 15 olmak üzere toplam 60 kelime olmak üzere dört sınıfa ait kelimeler listesine dahil etti. Kelimeler ücretsiz hatırlama için rastgele sırayla sunuldu. Aynı zamanda Bousfield, "sınıf gruplaması" adını verdiği bir fenomen keşfetti; denekler, liste boyunca dağılmış olsalar bile, belirli bir sınıfın üyelerini birlikte hatırlama eğilimindeydiler. Bu, Jenkins ve Russell'ın verilerine çok benzer, kelime çiftleri arasında yüksek derecede bir ilişki ile birlikte hatırlanırlar, yani gruplaşmalar oluştururlar.
Belirli bir sınıfa ait olan tüm kelimelerin birbirleriyle çağrışım yapma eğilimi göstermesi gerektiği düşünülebilir. Bu nedenle şu soruyu sorabiliriz: Sınıf gruplandırması, Jenkins, Russell ve Mink'in deneylerinde gözlemlenen çağrışım gruplamalarından farklı mıdır? Cevap, görünüşe göre, olumlu olmalıdır: Aynı sınıfa ait olmaktan kaynaklanan etkiler, çağrışımsal yakınlığın etkilerinden ayırt edilebilir. Bu, aynı sınıfa ait ancak birbiriyle ilişkili olmayan kelimeler listeye alındığında, yine de sınıfa göre gruplamanın meydana gelmesiyle kanıtlanmaktadır (Bousfield ve Puff, 1964; Wood ve Underwood, 1967). Örneğin, MAKARA, NAMLU ve TOP, "yuvarlak nesneler" sınıfındadır. Serbest çağrışım yöntemiyle ortaya çıkarılabilecek şekilde birbirleriyle ilişkilendirilmezler, ancak belirli koşullar altında birlikte hatırlanırlar. Aynı sınıfa ait olmanın, gruplamaların oluşumuna bağımsız bir katkı sağladığı yönünde başka veriler de vardır: Listede yer alan kelimeler çağrışımsal olarak ilişkilendirildiğinde ve ayrıca aynı sınıfa ait olduklarında, gruplama etkisi azalır. aralarındaki bağlantıların sadece çağrışımsal olduğu zamandan daha belirgindir (Cofer, 1965). Örneğin, BED ve CHAIR aynı sınıfa aittir ve oldukça ilişkilidir, BED ve DREAM ilişkilidir ancak farklı sınıflara aittir. Birinci türden çiftlerden oluşan listeleri çalarken, sözcükler ikinci türden çiftlerden oluşan listeleri çalarken olduğundan daha çok çiftler halinde hatırlanır.
Bousfeld (Bousfield ve Cohen, 1953) sınıf gruplandırmasının etkisini şu şekilde açıklamaktadır. Sınıflara bölünebilen bir liste öğrenirken, bir sınıfın tüm üyeleri, bu sınıfa karşılık gelen daha üst düzey bir yapıda ilişkilendirilecektir. Daha sonra, yalnızca bir temsilcinin geri çağrılması tüm yapıyı harekete geçirecek ve bu da aynı sınıfın diğer temsilcilerinin geri çağrılmasını kolaylaştıracaktır; böylece hep birlikte oynayacaklar ve bir grup oluşturacaklar. Örneğin, liste birkaç hayvan adı içeriyorsa, ASLAN kelimesini hatırlamak, "hayvanlar" sınıfını etkinleştirebilir, bu da KÖPEK, ZEBRA vb.
Bowsfield'ın sınıfa göre gruplaşma olgusunu keşfetmesinden sonra yapılan çalışmalar, bu tür bir örgütlenmenin aydınlatılmasına katkıda bulunmuştur. Sınıflandırılabilir bir listenin ezberlenmesi ve geri çağrılması en az üç ana süreci içeriyor gibi görünmektedir (Bower, 1972a): 1) listedeki kelimelerin hangi sınıfları temsil ettiğini bulmak; 2) sınıfın adı ile listede yer alan temsilcilerinin adı arasında özel çağrışımların geliştirilmesiyle, 3) sınıf adlarının hatırlanmasıyla.
Her şeyden önce, denek bu listede hangi sınıfların temsil edildiğini belirlemelidir. Bu görev, önce bir sınıfın, sonra diğerinin tüm temsilcilerini rastgele bir karışım biçiminde değil, bloklar biçiminde sunarak onun için daha kolay hale getirilebilir. Gerçekten de, bu tür bir sunum, gruplandırmanın etkisini artırdı ve hatırlamayı geliştirdi (Cofer a.o., 1966).
Daha sonra özne, listede hangi üyelerin temsil edildiğini her sınıf için belirlemelidir. Listede her sınıfın belirli temsilcileri olduğu gerçeğini bir şekilde hafızasında tutmalı ve bunları sınıfın adıyla ilişkilendirmeli, böylece daha sonra sınıfın adını hatırlayarak temsilcilerinin temsilcilerini hatırlayabilecektir. listede bulunanlar. Belirli bir sınıfın bazı üyeleri ile adı arasındaki daha yüksek derecede bir ilişkinin bu ikinci aşamayı kolaylaştırması ve dolayısıyla ezberlemeyi ve hatırlamayı kolaylaştırması beklenebilir. Ve gerçekten de öyle. Örneğin, deneklerin bu sınıftaki bir nesneyi adlandırmaları istendiğinde çeşitli örnekler verme sıklığını incelerken, "metaller" sınıfı için en çok demirin çağrıldığı ve sınıf için kurşunun nispeten nadir olduğu ortaya çıktı. "dört ayaklı hayvanlar" en yaygın örneği bir köpektir ve fare nadirdir, vb (Battig ve Montegue, 1969). Ve eğer ücretsiz hatırlama listesi karşılık gelen sınıfların sık sık adlandırılan örneklerinden oluşuyorsa, o zaman hatırlama, listenin nadiren çağrılan örneklerden oluşmasından daha etkilidir (Bousfield a.o., 1958; Cofer a.o., 1966).
Son olarak, hatırlamanın sınıf adlarının bellekten alınmasıyla başladığını ve bu adların da listede yer alan temsilcilerinin geri getirilmesi için bir anahtar görevi gördüğünü varsayıyoruz. Bu nedenle, sınıf adlarını çıkarmanın etkinliğini artıran faktörlerin liste hatırlamayı iyileştirmesi beklenebilir. Örneğin, hatırlama sırasında deneklere hangi sınıfların listede olduğu söylendiğinde, hatırlama performansı önemli ölçüde arttı (Tulving ve Pearlstone, .1966; Lewis, 1972).
Sınıflandırılabilir listelerle deney yapmak, malzeme organizasyonunun nasıl çalıştığını anlamanıza yardımcı olur. Görünüşe göre, bu tür listelerin öğrenilmesi, daha karmaşık birimlerin öğelerden organize edildiği karmaşık bir süreçtir ve bu sonuncular daha sonra orijinal girdi mesajlarına dönüştürülebilir. "Örgütsel süreçler" genel başlığı altında ele aldığımız her şey bu şemaya uyar. Organizasyondan kaynaklanan daha büyük birimlerin spesifik özellikleri farklı durumlarda farklı olabilse de (örneğin, sınıf organizasyonu, basitçe yakın sözcükleri birleştirenlerden farklı yapılarla sonuçlanabilir), daha yüksek dereceli birimlerin inşası, ardından ayıklama süreci - önce bu birimlerin ve daha sonra bileşenlerinin, genel olarak "organizasyonun" özü gibi görünüyor. Dolayısıyla örgütlenme, yapılanmayı, sözlü aracıların kullanımını, çağrışımsal yakınlığa göre gruplandırmayı ve aynı sınıfa ait olmayı ve aşağıda göreceğimiz gibi "öznel örgütlenmeyi" içerir.
SUBJEKTİF ORGANİZASYON
Öznel düzenleme, az önce tartışılan, deneyi yapanın listeye belirli bir yapı verdiği düzenleme türünün tam tersidir. Öznel organizasyonda, deneycinin bakış açısından herhangi bir organizasyondan yoksun olan listeye öznenin kendisi yapı verir. Bu, bir KOSH uyaranı deneğin "kedi"yi düşünmesine yol açtığında olana benzer. Sübjektif organizasyon, sınıflandırılabilir bir listenin organizasyonundan farklı olabilse de, her iki durumda da benzer süreçler meydana gelir.
Öznel organizasyonun (Tulving tarafından türetilen bir terim, 1962) tespit edilmesi, yukarıda tartışılan listelerde yaratılanlar gibi kasıtlı olarak teşvik edilen organizasyondan daha zordur. Öznenin ücretsiz hatırlama için sunulan listede belirli bir organizasyon oluşturduğu nasıl tespit edilebilir? Bunun bir yolu, kelimelerin hatırlanma sırasını gözlemlemektir. Bir liste yakından ilişkili kelimeler içeriyorsa, bunların genellikle birlikte çağrıldığını ve ayrıştırılmış listelerde yer alan aynı sınıfın üyelerinin de birlikte çağrıldığını zaten biliyoruz. Bu nedenle, sübjektif düzenlemenin aynı etkiye sahip olması gerektiği, yani aynı tür yapılarda düzenlenen sözcüklerin - sunuldukları sıraya bakılmaksızın - birlikte hatırlanması veya gruplandırmalar oluşturması gerektiği düşünülebilir; bu nedenle, aynı listeyle yapılan birkaç deneme hakkında veri toplarsanız, büyük olasılıkla şu veya bu yapıda düzenlenmiş kelimelerin her seferinde birlikte hatırlandığı ortaya çıkacaktır. Kısacası, sözcükler farklı denemelerde farklı sıralarda sunulsa da, deneklerin belirli bir sabit sıradaki sözcükleri hatırlamalarında organizasyonun tezahür etmesi beklenebilir. Öznel organizasyonun ölçüsü bu tür düşüncelerden türetilebilir.
Bahsetmeye değer iki sübjektif organizasyon ölçüsü, CO ölçüsü (öznel organizasyon; Tulving, 1962) ve 111111 ölçüsüdür (denemeden denemeye sabitlik; Bousfield ve Bousfield, 1966). Her ikisi de hatırlama sırasının sabitliğine dayanır: bu sıra, deneğin denemeden denemeye ne kadar sabit olursa, aynı sırayla farklı denemelerde ne kadar çok kelime çifti hatırlarsa, SD veya 111111 ölçüsü o kadar yüksek olur. Bu ölçümlerin, deneklerin ürettiği organizasyonun derecesini yansıttığı varsayılmaktadır. Bu nedenle, yarattığı daha belirgin organizasyon, yeniden üretim sırasında kelime dizisinin o kadar sabit olması gerektiğine ve buna bağlı olarak öznel organizasyonun ölçüsünün o kadar yüksek olduğuna inanıyoruz.
Bu önlemleri bir şekilde kullanmak mümkün mü? Ve eğer öyleyse, nasıl? Deneyi yapan kişi tarafından belirlenen düzenlemenin etkisi hakkında bildiklerimize dayanarak, sübjektif liste düzenlemenin de hatırlama performansını artırmasını bekleriz. Bu nedenle, SD'nin hatırlama ile ilişkili olması beklenebilir, yani SD'nin ölçüsü ne kadar yüksekse, hatırlama etkinliği o kadar yüksek olacaktır. Deneysel sonuçlar genellikle bunu desteklemektedir (örneğin bkz. Tulving, 1962, 1964). Ancak bazı teorisyenlere göre böyle bir korelasyon yeterince sabit değildir. Korelasyoncular, organizasyonun hatırlamaya yol açtığı fikrinin yanlış olmadığını öne sürerek yanıt verdiler: basitçe daha doğru bir organizasyon ölçüsü kullanmalıyız (Postman, 1972; Wood, 1972).
Öznel organizasyonun varlığına ve bunun hatırlama üzerindeki etkisine dair diğer kanıtlar, hem materyal organizasyonunun hem de yeniden üretiminin aynı anda etkilenebileceğinin bulunduğu deneylerden gelmektedir. Örneğin, bir ücretsiz hatırlama görevindeki deneklere, belirli öğeleri bir arada gruplandırmaları gerektiği talimatı verilir. Bu talimat; hem organizasyon hem de hatırlama ölçümlerinin artmasına yol açar (Mayhew, 1967). Tersine, her öğeyi ayrı ayrı kodlama ihtiyacını vurgulayan yönergeler her ikisini de azaltır (Alien, 1968). Bu sonuçlar öznel organizasyonun rolü kavramını doğrulamaktadır.
Serbest hatırlamanın yarattığı sübjektif organizasyon, birçok yönden deneyi yapan kişi tarafından belirlenen organizasyona benzer. SD puanı, sübjektif düzeyde, sınıfa göre gruplamaya neyin karşılık geldiğinin bir göstergesi olarak hizmet eder; Böylece, SD değerlerine ilişkin veriler, deneklerin öznel olarak belirlenmiş gruplamalar oluşturduğunu gösterir. Sübjektif organizasyon ile deneyci tarafından belirlenen organizasyonun diğer bir ortak özelliği, hatırlama üzerindeki olumlu etkisidir. Hem sınıf gruplaması hem de SD puanları, hatırlama ile pozitif olarak ilişkilidir. Bütün bunlar, her iki örgütlenme türünün de özünde aynı şekilde işlediğini gösteriyor.
Mandler ve Pearlstone (Mandler ve Pearlstone, 1966). Deneylerinde deneklere, her birinin üzerinde bir kelime yazılı olan 52 kartlık bir deste verildi. Denekler bu kartları sınıflara (iki ila yedi sınıf) bölmek zorunda kaldı. Kartlar karıştırıldı ve ardından denek onları tekrar tekrar sınıflara ayırdı ve aynı şekilde arka arkaya iki kez dağıtana kadar buna devam etti. Deneyin önemli bir özelliği, bir grup deneğin kartları istedikleri gibi bölmekte özgür olması, diğerinin ise kartları bölme sırası ile ilgili belirli talimatları takip etmesiydi. (Farklı sınıflandırma yöntemleri arasındaki farklılıkların kontrolünü sağlamak için, ikinci gruptaki her deneğin, birinci “serbest” gruptaki deneklerden birinin yaptığı gibi, aynı şekilde parçalaması istendi.) Dağılım görevini tamamladıktan sonra, her denek mümkün olduğu kadar çok kelimeyi hatırlamak zorundaydı.
Tahmin edilebileceği gibi, Mandler ve Pearlstone, "özgür olmayan" ikinci gruptaki deneklerin, kartları aynı şekilde arka arkaya iki kez sınıflara bölmek için çok daha fazla denemeye ihtiyaç duyduklarını buldular. Ancak, hatırlama etkinliği her iki grupta da yaklaşık olarak aynıydı. Bu, ana rolü oynayanın kelimelere aşinalık derecesi olmadığı anlamına gelir ("özgür olmayan" grubun daha fazla denemesi olduğundan): hatırlama, elde edilen organizasyon düzeyi tarafından belirlendi. Diğer bir önemli sonuç, deneklerin kartları böldükleri sınıf sayısı ile hatırlama verimliliği arasında güçlü bir pozitif korelasyonun keşfedilmesiydi. Denekler, oluşturdukları her sınıftan ortalama beş kelimeyi yeniden ürettiler; yani ne kadar çok sınıf oluştururlarsa o kadar çok kelimeyi hatırladılar. Bu, sınıflara bölünebilen öğrenme listelerinde not edilenlere çok benzer (Cohen, 1966; Tulving ve Pearlstone, 1966): denekler belirli bir sınıfın herhangi bir temsilcisini hatırlamayı başarırsa, o zaman genellikle diğer ilgili olanları hatırlarlar. oldukça iyi. bu kelime sınıfına. Bu nedenle, bu tür listelerle yapılan deneylerde, toplam hatırlama puanı, en azından bazı öğelerin geri çağrıldığı sınıf sayısı arttıkça daha yüksektir. Sübjektif organizasyon ile deneyci tarafından belirlenen organizasyon arasındaki bu genel benzerlik, her iki organizasyon türünün de aynı şekilde işlediğini gösterir.
Öznel organizasyon, sınıf gruplaması, çağrışımsal gruplama, ara kelime seçimi ve yapılandırmanın benzer şekilde işlediğini bir dereceye kadar saptadıktan sonra, kısa süreli bellekte yapılanma arasındaki ilişki konusunda açıklığa kavuşturulması gereken bir nokta vardır (Bölüm 5). ve organizasyon burada uzun süreli bellekle bağlantılı olarak ele alınmıştır . Bu ilişkinin doğası açık olmalı, ancak yine de üzerinde biraz daha ayrıntılı olarak duracağız. Daha önce de belirtildiği gibi, yapılanma bir organizasyon biçimidir... Özünde, yapılanma ve organizasyon tek ve aynı süreçtir. Sadece bazı durumlarda, bu süreci incelemenin farklı yöntemlerine karşılık gelen farklı terimler kullanılır. Örneğin, özne, kısa bir öğe listesini doğrudan hatırlama görevini yerine getirerek "evcil hayvanlar" sınıfına bir dizi KOPTKA, KÖPEK, BALIK düzenlerse, o zaman yapılandırmayı incelediğimizi varsayabiliriz, çünkü hakkında konuşuyoruz. CP'nin işlevi ve yapılanma, CP'de yer alan organizasyon süreçlerinin adıdır. Öğe listesi daha uzunsa ve sunum ile çoğaltma arasında oldukça uzun bir süre geçiyorsa, o zaman burada DP'nin katılımını varsayabiliriz. Bu durumda öznenin COPTKA, KÖPEK, BALIK kelimelerini "evcil hayvanlar" grubunda birleştirmesine organizasyon adı verilir. Organizasyon nerede gerçekleşiyor? Kodlama sırasında yapıldığından, 5-7. bölümlerde tartışıldığı gibi, CP'nin "çalışma bölümünde" yerelleştirebiliriz. Ancak CP'de yer alan kodlama, varsaydığımız gibi, hem CP'de depolananları hem de DP'ye aktarılanları etkilediğinden, aynı düzenleme süreçlerinin her iki bellek türünün özelliği olduğu düşünülebilir. "Organizasyon" ve "yapılandırma" terimlerinin esas olarak bu süreçleri incelemek için kullanılan araştırma yöntemiyle ilgili olduğu ve buna göre işlevi bize göründüğü gibi baskın olan hafızanın depolanmasına atıfta bulunulduğu vurgulanmalıdır. şu ya da bu durum.
ORGANİZASYON NE ZAMAN OLUŞUR
BİLGİLERİ NE ZAMAN KODLARKEN VEYA ÇIKARIRKEN?
Böylece, organizasyonun ne olduğu hakkında genel bir fikrimiz var: girdi öğeleri kümelerinden üst düzey birimlerin oluşturulmasıdır. Daha sonra, bu birimlerin "kodları çözülebilir" ve bu da orijinal öğelerin çıkarılmasına yol açar. Böyle bir şema, bilginin kısa bir süre (yapılandırmada olduğu gibi) tutulması veya daha uzun süre saklanması ve girdinin herhangi bir resmi yapıya (sınıflandırılabilir listelerde olduğu gibi) veya algısal bir yapıya sahip olup olmadığına bakılmaksızın uygundur. organizasyonu (öznel organizasyon) üretir. Bir kodlama süreci olarak organizasyondan bahsediyoruz ve az önce verilen organizasyon tanımı bu fikre uyuyor gibi görünüyor. Böylece organizasyon, depolama sırasında meydana gelen ve birkaç unsuru tek bir birime bağlamayı amaçlayan bir süreç olabilir. Bu görüşe göre örgüt, bilginin kodlanmasını ve saklanmasını kolaylaştırır; birlikte depolanan farklı öğelerin birbirine bağımlı olduğunu varsayar. Sonuç olarak, ücretsiz geri çağırma listelerinde yer alan öğelerin saklanması daha az yer gerektirir. Bu şekilde, organizasyon hatırlamayı kolaylaştırır. Aynı zamanda, tüm gruplardaki öğelerin geri çağrılmasına da katkıda bulunur, çünkü bu durumda, kendisiyle ilgili tüm öğeleri aynı anda çıkarmak ve yeniden üretmek için daha yüksek dereceli bir birimin kodunu çözmek yeterlidir.
Bu konsepte, öznenin bir öğe listesini ezberlerken, öncelikle sunumu sırasında listenin genel yapısına dikkat ettiği bağımsız depolama ve geri alma fikri (Slamecka, 1968, 1969) karşı çıkıyor. . Bu genel yapıyı hafızasında tutar. Aynı zamanda listede yer alan elemanları ayrı ayrı hatırlar ve birbirinden bağımsız olarak saklar. Bu görüşe göre, düzenleme etkisi çıkarma anında ortaya çıkar. Listeyi yeniden oluşturma zamanı geldiğinde, denek, listede yer alan unsurları hafızasında araması boyunca ona rehberlik eden bir geri alma planını harekete geçirir. Bu plan, öznenin ezberleme aşamasında belleğe yerleştirdiği listenin genel yapısına dayanmaktadır. Böyle planlı bir arama göz önüne alındığında, öznenin yaklaşık olarak aynı anda birbirine yakın öğeler bulması muhtemeldir. Onları birlikte hatırlayacak, bu da hafta sonu gruplarının oluşmasına yol açacaktır.
Planlı bir arama, rastgele aramadan daha verimli olduğundan, bir plan kullanmak, geri çağrılan öğelerin sayısını da artıracaktır.
Az önce özetlenen iki görüş, organizasyonun yaratıldığı aşamaya göre farklılık gösterir. Birincisine göre organizasyon kodlama sırasında, ikincisine göre ayıklama sırasında gerçekleşir (ancak listenin genel yapısının hatırlanması beklendiği için burada kodlama ve depolamanın etkileri de dikkate alınmıştır). Bu gösterimler arasında bir fark daha vardır: Birincisine göre organize öğeler bir arada, ikincisine göre ise birbirinden bağımsız olarak depolanır. Ancak, bu iki plana karşı çıkma olasılığı genellikle tartışmalıdır (Postman, 1972). Aslında, organizasyonu bilginin hem kodlanmasını hem de alınmasını içeren bir süreç olarak düşünmek için iyi nedenler vardır; bunun kanıtı "kodlama özgüllüğü" ilkesi üzerine yapılan araştırmalardan gelir (Thomson ve Tulving, 1970).
KODLAMA ÖZGÜNLÜĞÜ
Kodlama özgüllüğü ilkesi şöyle der: "Neyin depolanacağı, neyin algılandığı ve nasıl kodlandığı tarafından belirlenir ve bellekte depolananın, depolanana erişmek için hangi özelliklerin kullanılabileceğini belirler" (Tulving ve Thomson, 1973, s. 353). Başka bir deyişle, hatırlama, kodlama (veya depolama) ve geri alma arasındaki oldukça karmaşık bir etkileşimin sonucudur. Bellekte depolanan malzemeye en iyi erişim için, çıkarma işleminin kodlama sırasında mevcut olan bilgilerin aynısını kullanması gerekir. Bu, girdi bilgilerinin kodlanmasının, onu çıkarmak için kullanılan özelliklerle eşleşmesi gerektiği anlamına gelir.
Tulving ve Pearlstone'un (Tulving ve Pearlstone, 1966) çalışmalarının bir açıklamasıyla bağlantılı olarak kodlama özgüllüğünün bir örneğinden daha önce bahsetmiştik. Bu yazarlar deneklere, her sınıfın tüm temsilcilerinin bir arada gruplandırıldığı bir liste sundu ve bu tür grupların her biri? sınıf adından önce gelir. Daha sonra, kontrol reprodüksiyonu sırasında, bir grup deneğe hatırlama işareti olarak sınıfların isimleri verildi ve kontrol grubuna bu isimler söylenmedi. Bu tür işaretler alan grubun, kontrol grubundan daha fazla kelime hatırladığı ortaya çıktı. Bu sonuçlar, test sırasında deneklere ezberleme sırasında sahip oldukları bilgileri (bu durumda, sınıfların adları) sağlamanın hatırlamayı kolaylaştırdığını göstermektedir. Bu sonuçlar, kodlama özgüllüğü ilkesiyle tutarlıdır: hatırlama, kodlama sırasındaki koşullar test oynatma sırasındaki koşullarla eşleştiğinde (yani, geri alma sırasında) en etkili olmuştur.
Tulving ve Osler (Tulving ve Osier, 1968) ve Thomson ve Tulving (Thomson ve Tluving, 1970) tarafından yapılan bir dizi deneyde bu konuda ek veriler elde edildi. Deneklere ücretsiz hatırlama için bir kelime listesi verildi. Bir grup denek ile yapılan deneylerde, ezberlenecek her kelimeye başka bir ilişkili kelime eşlik ediyordu; örneğin, EAGLE kelimesini SOAR kelimesi takip edebilir (listeler, deneğin iki kelimeden hangisini hatırlaması gerektiğini bildiği şekilde derlendi ve ikinci kelimenin birinciyi hatırlamasına yardımcı olabileceği söylendi) . Diğer denek grubuna bu tür ilişkili kelimeler verilmedi. Kontrol oynatma sırasında, her gruptaki bazı deneklere listeden ilişkili kelimeler verilirken, diğerlerine bu tür kelimeler verilmedi. Sonuç olarak, denekler dört gruba ayrıldı: 1) girişte ve oynatma sırasında ilgili kelimeleri alanlar; 2) bunları yalnızca girişte aldı, 3) yalnızca oynatma sırasında aldı, 4) ilgili kelimeler olmadan aldı. Sonuçlar tamamen açıktı. Hatırlama etkinliği açısından birinci grup diğerlerinden daha iyi performans gösterirken, ikinci ve üçüncü grup dördüncü gruptan daha düşük etkinlik gösterdi. Bu sonuçlar, kodlama özgüllüğü ilkesi lehine güçlü bir argüman sağlar. Geri çağırma, bilgilerin kodlanması ve çıkarılması için koşulların en büyük benzerliği ile en etkilidir.
Kodlama özgüllüğü ilkesi, temel olarak, bireysel öğeleri hatırlamak için temel özelliklerin kullanılması açısından incelenmiştir. Bununla birlikte, bu ilke, burada çizilen serbest hatırlama ve düzenleme resmini tamamlamamıza yardımcı olacaktır, çünkü aynı ilke, organize kelime gruplarının hatırlanması için oldukça uygulanabilir görünmektedir. Artık "düzenleme"yi şöyle tarif etmeye çalışabiliriz: özneye bir sözcük listesi sunulduğunda, bunları kodlama içinde düzenleme eğilimi gösterir. Bu, birkaç öğeden daha yüksek mertebeden birimler oluşturacağı anlamına gelir. Daha sonra, tarama sırasında, listenin bir kısmının bellekten alınması, geri kalanının geri çağrılmasına neden olacaktır. Çıkarma işlemi, organizasyon sırasında oluşan yüksek dereceli birimlerin kodunun çözülmesini içerir ve bu, çıktıyı kodlarken birleştirilen öğelerin gruplandırılmasıyla sonuçlanmalıdır, bu da ayıklamayı kolaylaştıracaktır. Tüm bunlar (çıkarma koşulları, kodlama ve depolama sırasında üretilen organizasyonla uyumlu olduğu sürece olacaktır. Ek olarak, kodlamanın gerçekleştiği koşulları geri yüklemeye yardımcı olan temel özelliklerin sunumu ile çıkarma kolaylaştırılabilir. Son olarak, çıkarılmalıdır. çıkarma işleminin kendisinin çok daha ayrıntılı bir analizi hak ettiğini söyledi, bu nedenle bir sonraki bölümde özellikle uzun süreli bellekten bilgi almaya odaklanacağız.
Bölüm 11
Bilgi Çıkarma İşlemleri
Bir önceki bölümde, hatırlamayı kolaylaştırmak için girdi malzemesi üzerinde gerçekleştirilen işlemler olan kodlama süreçlerine bakıldı. Aynı zamanda, ezberlemeyi tartışırken, bu bölümün odak noktası olacak olan bilgi çıkarma süreçlerini de dikkate almanın gerekli olduğu ortaya çıktı. Bu, tanıma testi adı verilen deneysel bir prosedürü hatırlamanın yanı sıra serbest hatırlama hakkında yeni bir şeyler öğrenmeyi gerektirecektir. Bütün bunlar bizi bellekten bilgi çıkarma süreçlerini tanımlayan modellerin inşasına götürecektir.
TANIMA
Tanımanın incelendiği yöntemle başlayalım. Tipik bir deney aşağıdaki gibidir. İlk olarak, özne, öğelerin listesiyle tanışır - ona bakar veya onu dinler. Ardından bir kontrol yapılır: özneye, listede yer almayan birkaç öğenin eklenmesiyle birlikte listenin bazı öğeleri sunulur. İkincisi, çeldirici olarak adlandırılır. Denek, listede olmayanları atarak listede yer alan öğeleri seçmelidir. Genel olarak yöntem bu açıklamaya karşılık gelse de, doğrulama prosedürü biraz farklı olabilir. Örneğin, evet-hayır yöntemini veya zorunlu seçim yöntemini kullanabilirsiniz (daha fazla ayrıntı için Bölüm 1'e bakın).
TANIMA VERİMLİLİĞİ
HATIRLATICI (TEKRAR OYNATMA) İLE KARŞILAŞTIRILMIŞTIR
Tanıma testinin önemli özelliklerinden biri, deneğin kural olarak kendisine sunulan listenin öğelerini hatırlayabildiğinden çok daha iyi tanımasıdır. Denekten önce bir listenin öğelerini hatırlaması istenirse ve ardından bir tanıma testi yapılırsa, genellikle kendini hatırlayamadığı birçok öğeyi tanırken bulur.
Shepard (1967), deneklerin çok sayıda öğeyi tanıma yeteneğini çok inandırıcı bir şekilde gösterdi. Üç tür öğe kullanarak bir dizi deney yaptı: kelimeler, cümleler ve resimler. Bir deneyde, deneklere her biri ayrı bir karta basılmış 540 kelime sunuldu. Denekler tüm bu kartları tek tek incelediler. Daha sonra iki alternatifli zorunlu seçim yöntemi kullanılarak 60 kelime tanıma testi yapılmıştır. Ve Shepard, doğru cevapların yüzdesinin ortalama %88 olduğunu buldu! 612 renkli resim sunulan denekler daha da iyi bir sonuç gösterdi - doğru cevapların %97'si. 612 cümlenin sunulduğu üçüncü deneyde doğru cevaplar %89 olarak gerçekleşti. Shepard ayrıca iki arkadaşını 1224 cümleyle bir deney yapmaya ikna etmeyi başardı; tanıma testinde doğru cevapların %88'i alınmıştır.
Shepard'ın sonuçları, hatırlamaya kıyasla tanımanın son derece yüksek verimliliğini açıkça göstermektedir. Şu soruyu sormak uygundur: bu her zaman böyle midir? Her zaman olmadığı ortaya çıktı: tanıma verimliliğinin oldukça düşük olacağı bu tür doğrulama koşulları oluşturmak mümkündür. Örneğin, listedeki öğelerle güçlü bir şekilde ilişkili veya bunlara çok benzeyen öğeleri çeldirici olarak kullanabilirsiniz. CAT kelimesini listeye ekleyebilir ve DOG kelimesini çeldirici olarak kullanabiliriz. Bu tür koşullar, tanıma etkinliğini azaltır (örneğin bkz. Underwood, 1965; Underwood ve Freund, 1968). Veya çok sayıda çeldirici kullanabilirsiniz - örneğin, kontrol ederken listede bulunan kelimelerle birlikte 90 alternatif kelime sunun. Bu koşullar altında, listeden kelimeleri tanımak zordur (Davis a. o., 1961).
Tanıma işleminin bir diğer özelliği de uzun tutma aralıklarında bile etkinliğinin yüksek kalmasıdır. Yani tanıma yöntemi ile değerlendirildiğinde unsurların çok yavaş unutulduğu görülmektedir. Kısa C-Gili sözcük listeleriyle yapılan bir deneyde, iki gün sonra tanıma için test edildiğinde verimlilik %100'e yakın kaldı (Postman ve Rau, 1957). Shepard (1967), yukarıda belirtilen deneylerden birinde, sunulan resimlerin 120 gün boyunca hafızada tutulmasını test etti. Elementlerin sunumundan hemen sonra ve 2 saat, 3 gün, 7 gün ve 120 gün sonra denek gruplarını teste tabi tuttu. Şekil l'deki grafikten de görülebileceği gibi. 11.1, unutma gerçekleşti, ancak çok yavaş gerçekleşti.
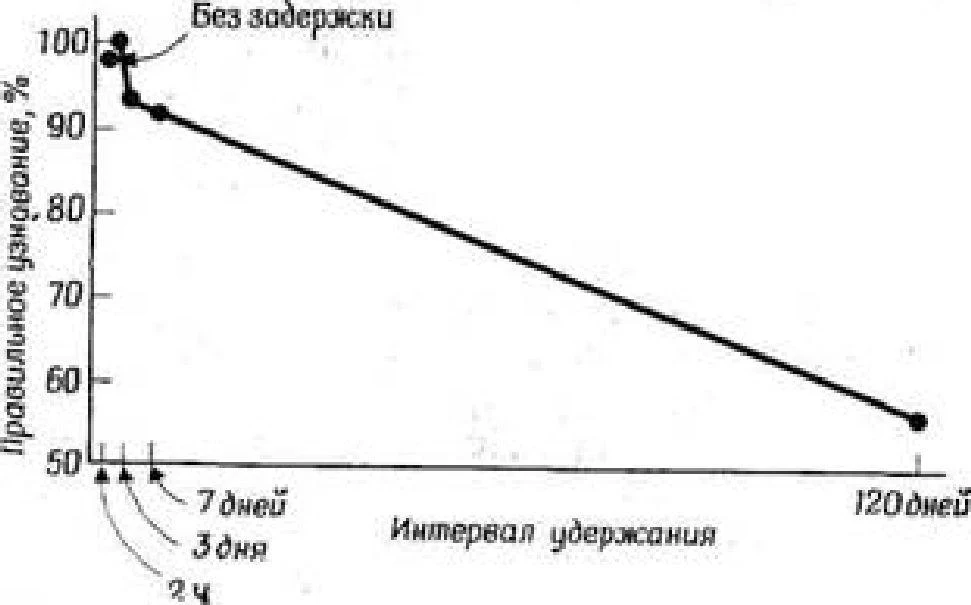
Rny. II 1. Kayıt isііімсгг, tutma aralığından (Shepard, 1967) doğru kaybolan eski (önceki) öğelerin ortalama yüzdesidir.
Kısa süreli unutmanın görünen düzeyi de doğrulama yöntemine bağlıdır. Tanıma yöntemiyle değerlendirildiğinde (hatırlama yöntemiyle karşılaştırıldığında) unutmanın belirgin şekilde daha yavaş olduğu görülmektedir. Kısa aralıklarla tanıma, Shepard ve Teghtsoonian tarafından incelenmiştir (Shepard ve Teghtsoonian, 1961). Deneklere, her birinin üzerinde üç basamaklı bir sayı yazılı olan büyük bir kart destesi verildi. Denekler, verilen sayının daha önce olup olmadığını her biri için not ederek tüm kartları gözden geçirmek zorunda kaldı. Tabii ki, ilk birkaç karttaki sayılar denek tarafından ilk kez görüldü. Ancak kartlar, ilk birkaç karttan sonra "eski" kartlar (deneğin daha önce gördüğü sayıları içeren) ve "yeni" kartlar (henüz görmediği sayıları içeren) olacak şekilde bir yığın halinde düzenlendi. rastgele düzenlenmiş ve aynı sıklıkta rastlanmıştır. Destenin en altında bulunan ve yalnızca bir kez görünen (eski ve yeni kartların eşit şansa sahip olmasını sağlamak için) birkaç kart dışında, her sayı kartlarda iki kez göründü.
Shepard ve Techtsunyan, tanıma etkinliğinin belirli bir sayının birinci ve ikinci tekrarı arasındaki farkla nasıl değiştiğiyle özellikle ilgilendiler. Örneğin, bir yerde kart dizisinde dirgen varsa: 147, 351, 362, 211, 111, 147, o zaman öznenin 147 sayısının ilk görünümünde "yeni" ve "eski" demesini bekleyebiliriz. " - ikinci görünümünde . Bu durumda, 147 sayısının iki oluşumu arasındaki kart sayısı dört olduğundan, boşluk dörttür. Eski elemanlar için doğru cevapların böyle bir boşluğun boyutuna bağımlılığının bir grafiğini oluşturursak, Şekil 1'de gösterilen eğriyi elde ederiz. 11.2. Bu eğrinin gösterdiği gibi, 60 madde gibi geniş aralıklara kadar doğru cevapların yüzdesi, şansa atfedilebilecek olandan daha yüksekti (yani, deneğin rastgele cevap vermesi durumunda olduğundan daha fazla doğru cevap vardı). Her durumda rastgele eşleşme olasılığı 0,5 olduğundan (öğe ya yeni ya da eskidir), o zaman basit bir tahminle doğru cevaplar %50 olacaktır. Bu nedenle, doğru cevapların yüzdesi% 50'nin üzerinde olduğunda, konunun sadece tahmin etmekle kalmayıp, rastgele cevaplardan daha iyi sonuçlar elde etmesine yardımcı olan hafızasındaki bilgileri kullandığından şüphelenme hakkımız vardır. Böylece böyle bir durumda unutmanın meydana geldiği aralığın yaklaşık 60 element olduğunu görüyoruz.

ben : ben _ . ' . . ben J_
0 10 20 30 GÇ 50 60
Chіkiya to otherpmmlg nx 5lemeyup<m
Pirinç. !), £. Eski etiketlerin doğru tanınmasının, belirli bir etiketin birinci ve ikinci sunumu
arasındaki aralıktaki uyaran sayısına bağlı olması
(Shepard ve Tca, hisoonîsn, 1961).
Bu sonuçlar, tanımayı değil yeniden üretimi test eden benzer bir deneyde elde edilen verilerle karşılaştırılabilir: Bölüm 1'de açıklanan Waugh ve Norman sonda şifre deneyinin (Waugh ve Norman, 1965) sonuçlarından bahsediyoruz. 6. Ayrıca, "sondanın" birinci ve ikinci görünümü arasındaki basamak sayısı olarak tanımlanan bir boşluk vardı ve ayrıca bir izin izinin bellekte saklandığına dair bir gösterge de vardı - hemen ardından gelen sayının hatırlanması " incelemek, bulmak". Waugh ve Norman bunu buldu
bu boşluk yaklaşık 12 haneye denk geldiğinde hatırlama etkinliği tahmin etme düzeyine düşmüştür. Bu nedenle, ara öğelerin sayısı arttıkça izlerin korunmasında kademeli bir azalmayı yansıtan unutma eğrilerinin benzerliğine rağmen, tam bir unutma gibi görünen şey için gerekli olan bu öğelerin sayısı tamamen farklıdır. Tanıma üzerine, belirli bir elementin bir kısmı, 60 ara elementten sonra bile hala açıklanırken, 12 ara elementten sonra yeniden üretim imkansız hale gelir. Dolayısıyla, bu deneyimlerin karşılaştırılabilir olduğu düşünüldüğünde, tanıma yöntemiyle ölçüldüğü şekliyle kısa süreler boyunca unutma, tıpkı daha uzun süreler boyunca olduğu gibi, hatırlama yöntemiyle ölçüldüğünden açıkça daha az belirgindir.
SİNYAL ALGILAMA VE TANIMA TEORİSİ
Artık tanıma ile ilgili bazı temel gerçeklere aşina olduğumuza göre, bellekte saklanan bir öğenin tanınmasına ilişkin teorik modeli ele almanın zamanı geldi. Bu aslında dikkate alacağımız ilk bilgi çıkarma modeli, sinyal algılama teorisine dayanan tanıma sürecinin bir modeli. Bu model, deneğin tanıma üzerine yargılarını dayandırdığı bellekte yer alan bilgi miktarını tahmin etmemize izin verecektir. Ayrıca tanıma testleriyle ilgili çok önemli bir sorun olan tahmine dayalı sonuçların çarpıtılması sorununa da bir yaklaşım açacaktır.
Örnek olarak, iki grup deneğe elementlerin tanımlarının sunulduğu ve ardından evet-hayır yöntemiyle tanınması için test edildiği hayali bir deney düşünün. Bu yöntem, test sırasında deneğe listede yer alan öğeler ve çeldiricilerin serpiştirilmiş olarak sunulması ve verilen öğenin listede olduğuna inanıyorsa "evet", inanıyorsa "hayır" cevabını vermesinin istenmesinden oluşur. bunun bir dikkat dağıtıcı olduğunu düşünüyor. Şimdi bir denek grubuna ("serbest" grup), tanıma performansının tüm "evet" ve "hayır" yanıtlarının doğruluğu temelinde değerlendirileceğinin ve tahmin etme girişimlerine herhangi bir ceza verilmeyeceğinin söylendiğini varsayalım. . Başka bir konu grubu ("muhafazakar") biraz farklı bir talimat alır. Tanıma performansının doğru "evet" yanıtlarıyla değerlendirileceği ve bir dikkat dağıtıcı bir liste öğesiyle karıştırıldığında ağır bir ceza verileceği söylendi. Bu tür talimatlardan sonra bu iki grubun makul stratejisinin tamamen farklı olacağı açıktır. Birinci grup denekler tahminden dolayı cezalandırılmadıkları için ona başvuracaklardır. Önlerindeki öğenin eski mi yoksa yeni mi olduğundan emin olmadıklarında, rastgele yanıt vereceklerdir. İkinci grup "evet" yanıtlarına çok dikkat etmelidir; bu nedenle, bu deneklerin verilen öğenin listede olup olmadığından veya çeldirici olup olmadığından tam olarak emin olmadıkları durumlarda, bunun çeldirici olduğu yanıtını vereceklerdir.
Stratejideki bu fark göz önünde bulundurulduğunda, bu iki gruptaki tanıma etkinliğinin farklı olması gerekir. Her şeyden önce, listenin öğelerini tanımanın doğruluğundan, yani konunun böyle bir öğe sunulduğunda "evet" yanıtını verdiği durumların yüzdesinden bahsedersek, o zaman muhtemelen bu yüzdenin olduğu ortaya çıkacaktır. "ücretsiz" grupta daha yüksek. Ne de olsa, bu grubun denekleri "evet" i güvenle tahmin edebilir ve bu tahminlerin belirli bir oranı doğru çıkabilir. "Muhafazakar" grubun deneklerine gelince, "evet" yanıtını seçerken büyük özen gösterdiler. Vakaların önemli bir kısmında "evet" yanıtı doğru olsa da, listedeki birçok maddeye "hayır" yanıtı vermek zorunda kaldılar. Sonuç olarak, listedeki öğelerin tanınmasını kontrol ederken daha düşük puanlar alırlar. Ek olarak, "tahmin etmelerine" izin verildiği için "serbest" gruptaki deneklerin doğru yanıt yüzdesi genellikle daha yüksek olabilir. Ve çoğu durumda "muhafazakar" grubun konuları, sunulan öğenin listeye dahil edildiğini düşündüklerinde, risk almamak için "hayır" cevabını vermek zorunda kaldıklarından, istemeden hatalar yaptılar.
Açıklanan deneyin anlamı açıktır. Bu iki denek grubunun, öğe listesi hakkında farklı miktarda bilgiyi belleklerinde tuttuklarına inanmak için hiçbir neden olmamasına rağmen, tanıma testindeki puanları farklıdır. Bu tahminlere dayanarak listenin unsurları için konuların hafızası hakkında sonuçlar çıkarmayı kafamıza almış olsaydık, o zaman bir hataya düşerdik. Çünkü iki denek grubu arasındaki öğe tanıma verimliliğindeki farklılıklar, sırayla talimatlardan kaynaklanan yanıtlarındaki belirli bir eğilimden kaynaklanmaktadır. Dolayısıyla, liste öğelerinin ezberlenmesini değerlendirmek için tanıma yöntemini kullanmak istiyorsak, bu tür eğilimlerin ve tahminlerin etkisini dikkate almanın bir yolunu bulmalıyız.
Bellek verimliliğine ilişkin oldukça doğru tahminler elde etmek için "tahmin düzeltmeleri" yapmanın birkaç yolu vardır. Bunlardan biri, iki alternatifli zorunlu seçim ("evet - hayır") yöntemini kullanmaları ve doğru cevapların sayısından yanlış cevapların sayısını çıkararak konunun cevaplarının düzeltilmiş bir değerlendirmesini vermeleridir. Tahmin sonuçlarının rastgele dağıldığı (yani tahmin yaparken doğru cevapların sayısının yanlış cevapların sayısına eşit olduğu) ve deneğin yanlış cevap verdiğinde rastgele cevap verdiği varsayılır. Böyle bir durumda, yanlış cevapların sayısının , rastgele cevap verdiği tüm zamanların sadece yarısını yansıtması beklenir , çünkü tahminlerinin diğer yarısının şans yasasına göre doğru çıkması gerekir. Bu, belirli bir konudaki doğru cevapların sayısından, doğru olduğu ortaya çıkan tahminlerin sayısını çıkarmak gerektiği anlamına gelir. İki seçenekli bir seçimde, doğru tahminlerin sayısı yanlış tahminlerin sayısına eşit olmalıdır, bu nedenle düzeltilmiş puan, toplam doğru cevap sayısından yanlışların sayısına eşit olacaktır. Örneğin, 100 soruyu yanıtlayan denek 10 kez tahmin etmeye başvurduysa, o zaman ortalama olarak 5 kez doğru ve 5 kez yanlış tahmin edecektir. Bu nedenle, verdiği toplam 95 doğru cevap sayısından 5 çıkarılmalıdır, çünkü doğru cevaplarının beşinde hatırlamadı, tahmin etti.
Bununla birlikte, bu düzeltme yöntemi bazı psikologlar tarafından yanlış olarak kabul edilir. Gerçek şu ki, tahmin yaparken eşit sayıda doğru ve yanlış cevap varsayarsak, deneğin belirli bir türde daha sık cevap verme olası eğilimini veya eski unsurları dikkat dağıtıcılardan daha iyi tanıma yeteneğini hesaba katmıyoruz. Göreceğimiz gibi, sinyal algılama teorisi, varsayımları düzeltmek için daha makul bir temel sağlar. Başka birçok amaç için de kullanıldığı için bu yaklaşımı biraz ayrıntılı olarak ele alacağız. Tanıma teorilerinden biri olarak da kabul edilebilir.
Sinyal tespiti teorisi, ses sinyallerini tespit etme problemleriyle bağlantılı olarak geliştirilmiştir (Green ve Swets, 1966). Tipik bir durumda, böyle bir görev aşağıdaki gibidir. Denek, beyaz gürültü (örneğin, tıslama veya atmosferik gürültü) arka planına karşı bazı sinyalleri (örneğin, bir ton) dinler. Bu sinyal belirli bir süre içinde ortaya çıkarsa, konu düğmeye basar. Bu koşullar altında, belirli bir aralıkta dört farklı durum mümkündür: 1) sinyal oluşursa ve özne düğmeye basarsa, ardından bir vuruş kaydedilir, 2) sinyal oluşur, ancak özne bunu fark etmez ve yapmazsa düğmeye basın, ardından bir kayıp kaydedilir', 3 ) sinyal yoksa ve özne düğmeye basmazsa, gerekçeli bir ret kaydedilir, 4) sinyal yoksa, ancak özne yine de düğmeye basarsa, a yanlış alarm kaydedilir. Böylece, bir isabet veya haklı bir başarısızlık durumunda, öznenin tepkileri doğrudur ve bir ıskalama veya yanlış alarm durumunda, o bir hata yapar.
Bir ses sinyalini algılama görevi, evet-hayır tanıma testiyle doğrudan karşılaştırılabilir. Özneye önce bir öğe listesinin gösterildiği ve ardından tanınması için test edildiği bir deney düşünün; test, kendisine art arda farklı öğeler sunulması ve her seferinde bu öğenin orijinal listede olduğunu düşünüyorsa "evet" (veya "eski") ve "hayır" (veya "yeni") demesi gerektiğidir. bunun bir dikkat dağıtıcı olduğunu düşünüyorsa. Bu durumda, eski öğenin (aslında listede bulunan) sunumu, bir ses sinyalini algılama görevinde bir tonun görünümüne benzer ve yeni bir öğenin (çeldirici) sunumu sinyal yokluğuna benzer. Diğer bir benzerlik de, tanımayı test etmek için bir özneye bir öğe sunulduğunda, dört durumdan birinin mümkün olmasıdır (Şekil 11.3). Birincisi, öğe eski olabilir (yani, zaten listede olan) ve konu onun hakkında şöyle diyebilir: "eski"; bu durumda doğru cevabı verir ve tıpkı ses sinyali probleminde olduğu gibi buna isabet denir. İkincisi, öğe eski olabilir, ancak özne yanlışlıkla onu "yeni" olarak adlandırabilir - bu bir eksiklik olacaktır. Üçüncüsü, öğe gerçekten yeni olabilir ve özne bunun "yeni" olduğunu söyleyecektir; ve bu, bir ses sinyali probleminde olduğu gibi, haklı bir ret olacaktır. Ve son olarak, dördüncü olarak, öğe gerçekten yeniyken özne "eski" diyebilir; yanlış alarm olurdu . Bu nedenle, sinyal algılama ve tanıma testi benzer görevlerdir ve bu nedenle, ilki için orijinal olarak oluşturulan teori, ikincisini analiz etmek için kullanıldı.
Lütfen şek. 11.3 olası sonuçlara karşılık gelen dört hücre bağımsız değildir. Bu nedenle, yalnızca bazı sonuçların sıklığını bilerek geri kalanının sıklığını türetebiliriz. Örneğin, bir deneğin evet-hayır yöntemi kullanılarak 20 öğelik bir listeye karşı test edildiğini varsayalım. Kontrol ederken, kendisine 20 eski ve 20 yeni olmak üzere 40 öğe sunulur. Bilelim ki, 15 eski elementle ilgili olarak denek doğru cevapları verdi, yani kendisine eski elementler sunulduğunda 20 seferin 15'inde "eski" cevabını verdi. Bu, isabet oranının %75 olduğu anlamına gelir. Şimdi "özledim" etiketli kutuyu doldurabiliriz çünkü onun 20 eski öğeden 5'inde hata yaptığını biliyoruz - onları "yeni" olarak adlandırdı; yani kaçırma oranı %25'tir. (Genel olarak isabet oranı ve isabet oranı %100'e eşit olmalıdır.) Benzer şekilde tartışarak, öznenin haklı başarısızlık oranının %40 olduğunu bilirsek, sunulduğunda "yeni" yanıtını verdiği sonucuna varabiliriz. sekiz yeni öğeyle. Bu durumda, kalan 12 yeni öğe sunulduğunda "eski" yanıtını vermesi gerekirdi ve bu nedenle yanlış alarmların sıklığı 20'de 12 veya %60 olacaktır. Böylece, her sütundaki hücrelerden birinin frekansları biliniyorsa, tüm hücrelerin frekansları bilinir hale gelir. Bu nedenle, değerler genellikle yalnızca iki hücre için verilir - her sütundan bir tane. Genellikle bunlar isabet sıklığına ve yanlış alarm sıklığına karşılık gelen hücrelerdir.
Sukma (%100) (%100)
Pirinç. 11.3, d trap testleri için olası sonuçlar <evet- hayır*,
Evet-hayır tanıma testindeki yanıtları sınıflandırma sistemi hakkında bilgi sahibi olduktan sonra (Şekil 11.3), karşılık gelen modelin ana varsayımlarını ele alacağız. İlk varsayım, DP'de bulunan herhangi bir bilginin belirli bir koruma derecesi ile karakterize edildiğidir - CP'deki izin belirli bir şekilde korunması (açıklığı) varsayımına benzer (Bölüm 6). Kolaylık olması açısından bundan böyle bellekteki bilginin "gücü" olarak anılacaktır. Şimdi "bilginin" tam olarak ne anlama geldiğini belirtmeyeceğiz, ancak dikkatimizi bir liste şeklinde sunulabilecek bireysel öğelerin DP'de depolanmasına odaklayacağız. Bellekteki belirli bir öğenin gücü, bu öğenin bulunduğu DP hücresindeki uyarım derecesi olarak düşünülebilir. Güç aynı zamanda "aşinalık" derecesine de karşılık gelebilir - bellekteki belirli bir öğenin gücü ne kadar yüksek olursa, o kadar tanıdık görünecektir.
İkinci varsayım, listede sunulan elemanların dayanım değerlerinin normal dağıldığıdır. Bu varsayımı daha ayrıntılı olarak ele alalım. Listeyi özneye sunduktan sonra, DP'sindeki her öğe belirli bir güçle karakterize edilir. Tüm elementler, sözde normal eğriye göre mukavemet açısından dağıtılır: elemanların çoğu ortalama bir kuvvete sahiptir, birkaç element çok yüksek bir mukavemete sahiptir ve diğer birkaç element çok düşük bir mukavemete sahiptir. Konuya sunulmayan ancak test sırasında yeni öğeler veya dikkat dağıtıcılar olarak kullanılacak öğeleri de ele alalım. Bu yeni elementlerin her birinin aynı zamanda bir miktar içsel güce sahip olduğunu ve elementlerin de güçlerine göre normal olarak dağıldığını varsayacağız (Şekil 11.4). Ek olarak, güç açısından eski unsurların değişkenliğinin, çeldiricilerin değişkenliği kadar büyük olduğunu varsayıyoruz. Bu nedenle, iki normal dağılım dikkate alınmalıdır - listede yer alan öğelerin kuvvetine göre dağılım ve çeldiricilerin aynı özelliğine göre dağılım.
Ryas, 11.4. Mümkün:*? güç açısından eski (önceden mevcut) elementlerin ve yeni memsgt'lerin (çeldiriciler) dağılımları arasındaki oran . L. Orta derecede lerskrgzanne, 5. Dayanıklılık, eski elemanlar lviii yenilerinden daha yüksek. B. Eski ve yeni unsurlar benzer bir canlılığa sahiptir.
Üçüncü varsayım, listedeki herhangi bir öğenin sunumunun konunun D11'indeki gücünü arttırmasıdır. Bu, bir öğenin sunumunun, onu bir başlangıç seviyesinden yeni, daha yüksek bir seviyeye aktararak, başlangıçtaki gücünü (veya "tanıdıklığını") arttırdığı anlamına gelir. Bu aynı zamanda test deneğine sunulmayan öğelerin orijinal güç seviyelerinde kalacağı anlamına gelir. Bu üçüncü varsayım çok önemlidir, çünkü bundan eski elemanlar ve çeldiriciler için dağılımların ortalama güç değerinde farklı olacağı sonucu çıkar. Tipik olarak, daha yeni sunuldukları için eski öğelerin ortalama gücü daha yüksektir. Yeni öğelerin gücü, listede sunulmadan önceki eski öğelerle aynı şekilde daha düşük olacaktır. Karşılık gelen eğrileri oluşturursak, listenin sunumunun eski öğeler için tüm dağılımın ani bir kaymasına - çeldiricilerin dağılımından uzaklaşmasına - yol açtığı ortaya çıkıyor.
Bu iki eğrinin - eski elemanlar ve çeldiriciler için - göreli konumu, başlangıç güç değerlerine bağlı olarak değişecektir (olası seçenekler, Şekil 11.4'te gösterilmektedir). Örneğin, deneklere sunulmak üzere seçilen öğelerin ilk gücü yüksekse (bu öğeler çok tanıdıktı veya daha önce defalarca sunuldu), o zaman artık güçleri büyük ölçüde artabilir ve çeldiricilerin gücünü çok geride bırakabilir. Bununla birlikte, daha sık olarak, iki dağıtım arasında bir miktar örtüşme beklenebilir. Eski elementlerin ortalama mukavemeti yenilerinin ortalama mukavemetinden daha yüksek olsa da, yine de yeni elementlerin bir kısmı eskilerinin bazılarından daha yüksek bir mukavemete sahip olacaktır.
Pirinç. 11.4 açıkça göstermektedir ki, bu iki dağılımın araçları arasındaki fark, bunların "yakınlık" veya güç ekseni boyunca aralarındaki mesafenin bir ölçüsüdür. Ortadakiler birbirinden ne kadar uzaksa, eski elemanların gücü yenilerine göre o kadar yüksek. Sinyal algılama modelinde, bu mesafe d ile gösterilen, eski ve yeni öğelerin ne kadar ayrıldığının bir ölçüsü olan bir ölçü işlevi görür. Daha kesin olarak d, standart sapma birimlerinde ifade edilen iki dağılımın araçları arasındaki mesafedir (yani, iki ortalama arasındaki farkın bu dağılımların toplam standart sapmasına bölümü). D değerine ek olarak, bir teorik değer daha - р dikkate almak gerekir. Açıklanan model çerçevesinde, p değeri denekler tarafından karar verirken kullanılır; bu, öznenin kararını dayandırdığı güç kriteridir. Bunun nasıl yapıldığını anlamak için deneyde neler olduğunu düşünün.
Deneğe eleman listesinin sunulması sonucunda her bir elemanın kuvvetinin bir öncekine göre arttığını ve sonuç olarak başlangıç değerleri ne olursa olsun tüm elemanların mukavemetlerinin aynı miktarda arttığını varsayıyoruz. Listede sunulan öğelerin dağılımı (şimdi onlara "eski" diyoruz), güç ekseni boyunca bir miktar değerli değerle yer değiştirmiştir. Bu arada, testte çeldirici olarak kullanılan ("yeni" öğeler olarak adlandırılan) öğeler eski güçlerini korur. Bu yeni elemanların ortalama mukavemetinin eski elemanların ortalamasından daha az olması beklenebilir.
Şimdi konu bu listeye göre kontrol edildiğinde ne olduğunu görelim. Kendisine, yarısı eski, diğer yarısı yeni olan bir dizi öğe sunulur. Her bir unsuru inceler ve eski mi yoksa yeni mi olduğuna karar verir. Bir karar vermek için, denek (bilinçsizce) belirli bir güç değeri () seçer ve bunu bir kriter olarak kullanır. Test sırasında her bir öğeyi sunarken, DP'deki gücünü değerlendirir (veya bunun ne kadar "tanıdık" olduğunu belirler. Örneğin, öznenin belirli bir öğenin gücünü benimsediği güç ölçeğinde 100 olarak değerlendirdiğini varsayalım. eleman, aynı zamanda p değerine de. Eğer elemanın gücü P'den büyükse, o zaman denek "eski", P'den küçükse, o zaman "yeni" olarak cevap verecektir. Yani, örneğin, P \u003d 90 ise, gücü 100 olan elementimiz "eski" olarak adlandırılacaktır.Kısacası, burada karar vermek için belirli bir kural vardır, bu da şöyle der: verilen öğenin gücünü hesaplayın ve bu ise "eski" olarak cevaplayın gücü P'den büyüktür, aksi takdirde "yeni" olarak yanıtlayın.
Şimdi güç dağılımları ve d ve P değerleri hakkındaki bu fikirleri deneyin farklı sonuçlarıyla birleştirelim: "vurmak", "ıskalamak", "yanlış alarm", "haklı başarısızlık". Bu, Şek. 11.5, her iki mukavemet dağılımının sunulduğu ve d ve p değerlerinin not edildiği. İki eğrinin altındaki tüm bölge bizi ilgilendiren dört alt bölgeye ayrılabilir. Her birinin anlamı, eski veya yeni elemanlar için eğrinin altında olup olmadığına ve p'nin solunda mı yoksa sağında mı olduğuna bağlıdır. Örneğin, eski elemanlar için eğrinin altında ve p'nin sağında yer alan alt alanı ele alalım. Bu alt bölge, test sırasında eski unsurlardan birinin sunulduğu ve öznenin "eski" dediği durumlara karşılık gelir - kısacası, bu alt bölgenin alanı isabet sıklığını yansıtır. Benzer şekilde, eski eleman eğrisinin altındaki, ancak P'nin solundaki alan, kayıp oranına karşılık gelir. Özetle, bu iki alt bölge, eski elementler için dağılım eğrisinin altında kalan bölgenin tamamını oluşturur (sırasıyla, Şekil 11.3'te, bu iki frekansın toplamı %100'e ulaşır). Yeni için dağıtım eğrisinin altında
öğelerinde, yanlış alarmların (Ş'nin sağında) ve haklı arızaların (Ş'nin solunda) alt alanları bulunabilir. Böylece, iki dağılım eğrisinin altındaki tüm alan, evet-hayır testinin dört olası sonucuna karşılık gelen dört alt alana bölünmüştür.
Pirinç. 11.Ş. Tespit teorisi kavramları , uygulamalarında ^maıta ve uane-
vainyu.
Şimdi, tanıma sürecine ilişkin kısmi modelimiz, bellek izlerinin gücü, bunların bu özelliğe göre dağılımı ve karar verme kuralları hakkında zaten fikirler içeriyor. Bunun, tanımanın etkinliğini belirlememize, tahmin etmenin etkisini ortadan kaldırmamıza nasıl izin verdiğini anlamak için, d ve Ş değerleri değiştiğinde ne olacağını düşünmeliyiz. Şek. 11.6 çeşitli olasılıklar sunar. Şek. 11.6, Ve tanıma verimliliğinin d'deki bir değişiklikle nasıl değiştiğini görebilirsiniz. d'deki bir artış, eski ve yeni elemanlar arasındaki güç farkının artması anlamına gelir. Çok büyük d için bu fark çok büyüktür ve özne eski öğeleri yenilerinden kolayca ayırt edebilir. d küçükse, bu elemanları birbirinden ayırmak zorlaşır. Bu nedenle, d'nin değeri esas olarak eski ve yeni öğeler arasındaki farka olan duyarlılığımızın bir ölçüsüdür ve hatta çoğu zaman "gerçek" duyarlılık olarak adlandırılır. Bellekte yer alan bilgileri, yani sunulan öğelerin ve çeldiricilerin modelindeki farklı güçleri yansıtır. Tahminin etkisini dışlamaya çalışmamız, d'nin saf bir tahminini elde etmek içindir. Lütfen şek. 11.6, A, p sabiti ve artan d ile (hafızadan geri alınabileceklerde gerçek bir artışa, yani eski öğelere karşı "hassasiyette" gerçek bir artışa karşılık gelir), isabet oranı, ancak yanlış alarm oranı değil, artacak. Bunun nedeni, özne daha hassas hale geldikçe eski öğeyi (göründüğünde) yeni öğeden ayırt etmesinin kolaylaşmasıdır.

Rne. 11.6. P ve sg'deki değişikliklerin uznvyshne üzerindeki etkisi. L Vdyanve değişiklikleri - d
' p'nin sabit değerinde: g veelnteincm ti' Temmuz
başı lanium ve erastast olmadan ss ? po*
yaowyu Derecelendirmeler <G artacaktır. fi. Ü değişikliklerinin etkisi pgtp-nn-
I: : inci değer d': USS ile . TIK VE YANLIŞ
H rigvogts sallanabilecek ve puanlar 4' sabit olacaktır.
Şimdi düşünün Şekil. 11.6, .B. Bu, d sabit kalırken P değiştiğinde ne olduğunu gösterir. Bu durumda, konu, hafızasındaki bilgi miktarı değişmemiş olmasına rağmen, karar verdiği temelde kriteri değiştirir - eski unsurlara karşı gerçek duyarlılığı aynı kalmıştır. Özünde, tahmin stratejisi değişir. P'nin çok düşük değerlerinde bir elementin çok küçük bir kuvvete sahip olması öznenin onu "eski" olarak adlandırması için yeterlidir. Buna göre, gerçekten eski olan hemen hemen tüm unsurları doğru bir şekilde değerlendirerek, ancak yeni unsurlarla ilgili birçok hata yaparak "eski" kelimesini çok sık telaffuz edecektir. Kısacası, daha yüksek bir isabet oranına sahip olacak, ancak aynı zamanda daha yüksek bir yanlış alarm oranına sahip olacaktır. Ş'nin yüksek değerlerinde bunun tersi gözlenir. Denek çok dikkatli davranır ve nadiren "eski" der - yalnızca cevabın doğruluğundan oldukça emin olduğu durumlarda ve bu yalnızca çok tanıdık unsurlarla ilgili olarak mümkündür. Vuruş sıklığı nispeten düşüktür, çünkü denek eski unsurları gördüğünde genellikle tedbir amaçlı olarak "yeni" yanıtını verir; ancak, yeni öğeler için nadiren "eski" yanıtını vereceğinden, nadiren yanlış alarm vakaları olacaktır. Böylece, d'nin değeri sabit kalırsa, p'deki kaymaların hem isabetlerin hem de yanlış alarmların sıklığında ve dahası aynı yönde bir değişikliğe yol açtığını görüyoruz. Ş arttıkça bu frekansların her ikisi de azalır.
d ve Ş'deki değişikliklerle isabet oranlarındaki ve yanlış alarmlardaki değişikliğin doğası, tahmin için düzeltme yapmak üzere bir sinyal algılama modelinin kullanılmasını mümkün kılar. Bu frekansların her bir değer çifti için karşılık gelen bir d değeri vardır. Tahmin etmenin etkilerini dışlamanıza izin veren şey budur. Ş'deki herhangi bir değişiklikle hem isabet hem de yanlış alarm oranları değişir, ancak yeni değerleri eskisi gibi aynı d ile ilişkilendirilir; başka bir deyişle, konu tahmin stratejisini değiştirebilir (örneğin, yanlış alarmlar için onu cezalandırmaya başlarsa) ve bu, yeni bir isabet oranı ve yeni bir yanlış alarm oranına yol açabilir, ancak bu yeni değer çifti d'nin eski değerine karşılık gelir. Aksine, eski öğelere karşı gerçek hassasiyet değiştirildiğinde (örneğin, eski öğelerin gücünde bir artışa neden olan yeniden listeleme durumunda), aynı anda yanlış alarm oranını değiştirmeden isabet oranı değişir. Bu durumda, bu frekansların yeni kombinasyonu d'nin yeni değerine karşılık gelecektir. Kısacası, bellek izleme gücü, bu frekanslardan herhangi biri tarafından ayrı ayrı değil, bir çift isabet oranı ve yanlış alarm oranı ile ölçülür. Ve bu eşleştirilmiş değerlerdeki değişimin doğası gereği, neyin değiştiği yargılanabilir - gerçek hassasiyet (d) veya Ş kriteri.
Sinyal algılama yöntemini kullanan deneyciler, her isabet ve yanlış alarm frekansı çifti için d değerlerini listeleyen özel tablolar kullanır. Böyle bir tablonun yardımıyla deneyi yapan kişi isabet ve yanlış alarm oranlarını değiştirebilen belirli bir prosedürün gerçekten değişip değişmediğini belirleyebilir d. Sadece tahmin etme stratejisi değiştiyse, o zaman bu iki frekans aynı anda değişecek ve bu frekansların yeni değerleri için d değeri eskileri ile aynı olacaktır. Böylece, d kullanılarak, doğru cevapların sayısını yüzde olarak ifade etmek yerine, teorik olarak sağlam bir şekilde tahmin yapmak için düzeltme yapılabilir.
Dahası, sinyal algılama teorisi, tanıma probleminin, özünde bir hafıza teorisi olarak değerlendirilebilecek şekilde sunulmasına izin verir. Anlamı şu şekilde özetlenebilir: Bir elementin sunumu, gücünde bir artışa veya isterseniz, "aşinalık" derecesinde bir artışa veya ilgili hücrenin hafızada uyarılmasına (seçim) yol açar. Bu ifadelerden birinin veya diğerinin çok önemi yok: hepsi o sırada veya başka zamanlarda kullanıldı). Bu teori ayrıca, öznenin kendisine sunulan herhangi bir öğenin "aşinalık" derecesini değerlendirebildiğini ve ardından bu öğenin listede yer alıp almadığına karar vermek için bu değerlendirmeyi kullanabileceğini belirtir. Öğe, listede olduğu düşünülecek kadar tanıdık görünüyorsa, konu onu "eski" olarak değerlendirecektir. Çeşitli koşullara bağlı olarak, "yeterli aşinalık" kriteri değişebilir.
Tanıma deneylerinin bazı sonuçlarını açıklamak için bu teoriyi kullanalım. Örneğin, listedeki kelimelerle ilişkili kelimeleri çeldirici olarak kullanırsak ne olacağını düşünün. Böylece listede COPTKA kelimesinin varlığında DOG kelimesinin çeldirici olarak sunulması mümkün olacaktır.Bildiğimiz gibi bu tür durumlarda tanıma sonuçları azalmaktadır. Bunu modelimizi kullanarak açıklamak oldukça kolaydır: Bir listenin sunumunun, öğelerine benzeyen veya öğelerle ilişkilendirilen sözcüklerin gücünü dolaylı olarak artırdığını varsaymak yeterlidir. Bu nedenle, test sırasında, güçleri "yeni" olarak kullanılabilecek diğer birçok öğeden daha yüksek olacak ve dağılımların örtüşmesi buna göre artacaktır. Daha fazla örtüşme, daha az d anlamına gelir; bu nedenle, benzer veya ilişkili çeldiricilerle, tanıma testlerinin sonuçları daha kötü olacaktır.
Nadiren geçen kelimelerin genellikle sık kullanılanlardan daha iyi tanındığı iyi bilinen başka bir gerçeği düşünün (Shepard, 1967; Underwood ve Freund, 1970). Bu, belirli bir kelimenin doğal bir dilde, örneğin edebiyatta kullanım sıklığını ifade eder. Farklı kelimeler için sıklık tabloları vardır (örneğin bkz. Thomdike ve Lorge, 1944) ve kelimelerin kullanıldığı deneylerde sıklıkları genellikle keyfi olarak değişir. "Frekans" kelimesinin tanıma verimliliği üzerindeki etkisi, sinyal algılama teorisi kullanılarak, ilişkili çeldiricilerin etkisinin açıklanmasıyla hemen hemen aynı şekilde açıklanabilir (Underwood ve Freund, 1970). Belirli bir kelime sunulduğunda, onunla yüksek oranda ilişkilendirilen diğer kelimelerin gücünün bu çağrışımdan dolayı bir miktar arttığını varsayabiliriz. Listede yer alan sık tekrarlanan kelimeler için, gücü artan bu tür ilişkili kelimeler oldukça fazla olacak ve bunların çoğu da çok yaygın kelimelerle ilgili olacaktır. Bu dolaylı yolla pekiştirilecek kelimelerin bir kısmı listede yer alırken, bir kısmı da dikkat dağıtıcılar arasında bulunabilir. Bu dolaylı etkinin, gücü zaten oldukça yüksek olan liste öğelerinden nispeten düşük güce sahip olan çeldirici öğeler üzerinde daha güçlü bir etkiye sahip olacağını varsayarsak, o zaman çeldiricilerin gücündeki bir artışın (buna bağlı olarak) olduğu sonucu çıkar. dağılım eğrilerini kaydırmak), listenin diğer öğeleri üzerindeki herhangi bir etkiden daha ağır basmalıdır. Sonuç olarak, bu, sık tekrarlanan sözcükleri sunarken eski ve yeni öğelerin dağılımında, bunlarla ilişkili sözcüklerin gücündeki dolaylı bir artış nedeniyle önemli bir örtüşmeye yol açacaktır.
Şimdi nadir kelimelerin bir listesini düşünün. Bu kelimeler nispeten az çağrışım uyandırır ve bu nedenle sadece nispeten az sayıda kelimenin gücünde bir artışa neden olur. Bu durumda, çeldirici unsurların gücündeki kayma çok küçük olacak ve bu nedenle eski ve yeni unsurların dağılımlarında önemli bir örtüşme olmayacaktır. Sonuç olarak, nadir kelimeler için d'nin değeri, sık kullanılan kelimelerden daha yüksek olacaktır, bu da kelimelerin oluşumunun tanınma üzerindeki etkisini açıklamayı mümkün kılar.
Sinyal algılama modeli, sunumdan kaynaklanan güç artışının zamanla kademeli olarak ortadan kalktığını ve eski öğelerin dağılımının yeni öğelerin dağılımıyla yavaş yavaş yakınsadığını ve onunla daha fazla örtüştüğünü varsayarak unutmayı yorumlamak için de kullanılabilir. Böylece d azalır ve sonunda sıfıra gidebilir.
Görüldüğü gibi bu teori tanımanın bir takım özelliklerini açıklamayı mümkün kılmakta ve aynı zamanda öznenin hafızasını (d) karar verme sürecinden (P) ayırmayı mümkün kılmaktadır. Belki bu açıklamalardan bazıları biraz gecikmiş görünebilir, ancak teoriye çok iyi uyuyorlar. Bu nedenle, genel olarak, bir çıkarma teorisi olarak sinyal algılama modeli - en azından geçici olarak - tatmin edilebilir. Bellekte depolanan bilgilerin nasıl yeniden üretildiğini açıklar; Buradaki karar verme süreci, sunulan unsurun gücünün değerlendirilmesini ve bazı standartlarla dahili olarak karşılaştırılmasını içerir. Bu nedenle, bu model, bilgi bellekten alındığında meydana gelen süreçleri tanımladığı ölçüde, bir bilgi erişim modeli olarak görülebilir.
Özünde, bir tanıma modeli oluşturmak için ayrıntılı bir bilgi çıkarma teorisi gerekli değil gibi görünebilir: aslında, eğer çıkarılacak olan özneye dışarıdan sunulursa, aslında hala neyin çıkarılması gerekiyor? Göreceğimiz gibi, bilgi gerçekten de şu veya bu unsuru tanıyarak elde edilir. Bununla birlikte, bellekte belirli bir şeyi aramak anlamında bilgi çıkarmanın önemli rolü, özellikle hatırlama (yeniden üretme) durumunda açıktır. Bu nedenle, hatırlamayı tekrar gözden geçirme ve bu süreci de içeren bir bilgi erişim teorisi yaratmaya çalışmanın zamanı geldi.
BİLGİ KURTARMA VE HATIRLAMA
Bellek hakkında zaten çok şey biliyoruz. Örneğin, hat-sıra hatırlama eğrisinin yorumlarını, modaliteyle ilgili farklılıkları, deneyi yapanın belirlediği organizasyonun ve öznel organizasyonun etkilerini ele aldık. Boş belleği incelemeye geçmeden önce, sorunun ana karakterini ana hatlarıyla açıklamaya çalışalım. Serbest hatırlama prosedürü, sezgisel olarak, "hatırlama" kelimesinden genellikle anladığımız şeyin incelenmesine en yakın deneysel bir yöntem gibi görünüyor.
Bower (1972a), bir kelime listesinin serbest olarak hatırlanması ile laboratuvar dışındaki durumlarda hatırlanması arasındaki benzerliklere dikkat çekmiştir. En genel anlamda, serbest hatırlamanın, belirli bir kümeye dahil olan tüm öğelerin yeniden üretilmesine karşılık geldiğine işaret eder. Örneğin, az önce size gösterilen bir listedeki tüm kelimeleri hatırlamanız, Amerika Birleşik Devletleri'nin tüm başkanlarını isimlendirmeniz, bir partide gördüğünüz herkesi listelemeniz veya hafızadaki tutma aralıklarının süresini hatırlamanız istenebilir. Petersons deneyi (Bölüm 6). Laboratuarda, elbette, ücretsiz hatırlama genellikle daha önce sunulan bir listedeki tüm öğelerin geri çağrılmasından oluşur.
Genel bir biçimde, hatırlama, özneye önce ezberlenmesi gereken bir dizi bilgi sunulduğu ve ardından şu veya bu "anahtar" verildiği bir prosedür olarak tanımlanabilir - gerekli bilgileri çıkarmaya ve yeniden üretmeye yardımcı olan bir işaret. Deneyci geçici bir anahtar (örneğin: "Geçen Pazartesi ezberlediğiniz listeyi hatırlayın") veya bir sıra anahtarı (örneğin, "Bu listeden önce ezberlediğiniz listeyi hatırlayın") kullanabilir. Günlük yaşamda da, hatırlama genellikle şu ya da bu "anahtar" tarafından çağrılır ve yönlendirilir. Diyelim ki bir sınavda olduğu gibi doğrudan bir soru olabilir. Ya da bazı olayları akla getiren bir koku olabilir. Geri alma ipuçları, size kahvaltı yapmayı unuttuğunuzu hatırlatmak için aç hissetmek gibi içsel olabilir. Tüm bu durumlarda geçerli olan ipuçları, deneyi yapan kişinin "Önceki listeyi hatırla" derken deneğe verdiği ipuçlarına benzer.
Hatırlamanın genellikle bu tür ipuçlarının katılımıyla gerçekleşmesi, serbest hatırlama ile çift çağrışım yöntemi arasındaki benzerliğe de işaret eder. Bir anlamda, serbest hatırlama, eşleştirilmiş bir ilişkinin ikinci bileşenini hatırlamaya benzer: uyarıcı bileşen anahtardır ve reaksiyon bileşeni, belirli bir tepkiler dizisidir: ezberlenmiş kümeye dahil olan tüm öğeler. Örneğin, öznenin her biri birkaç öğe içeren iki listeyi ezberlemesi gerekiyorsa, bunun sonuçları, BİRİNCİ LİSTE uyaranının bir öğe grubuyla ve İKİNCİ LİSTE uyaranının bir diğer.
MODELİ HATIRLA
Geri çağırma nasıl çalışır? Bu sürecin oldukça ayrıntılı bir teorisi, Anderson ve Bower (Anderson ve Bower, 1972, 1973) tarafından, çağrışımsal bir ağ olarak hafıza kavramları dahilinde geliştirildi (bu yazarlar tarafından önerilen AFC modeli dikkate alındığında Bölüm 8'de tarif edildi). modellerine göre, sonraki çoğaltma için bir kelime listesinin konusunu ezberlerken bir dizi işlemdir (Şekil 11.7). Öncelikle deneğe listede yer alan kelimelerden biri (örneğin COPTKA) sunulduğunda, bu kelimeye karşılık gelen uzun süreli bellek (LT) hücresini belirli bir “liste etiketi” ile ilişkilendirerek işaretler. (örneğin, ifadeyi şu hücreyle ilişkilendirebilir: "Bu listede "kedi" kelimesini ezberledim.) Ayrıca, bu kelimeden yola çıkan çağrışımsal yolları da izleyerek, yine bu hücrede yer aldığı olarak işaretlenen diğer kelimeleri arar. Örneğin, DP'deki "kedi" kelimesini "köpek" kelimesine bağlayan yollardan birini takip ederek (örneğin, "Kediler köpekleri kovalar" ifadesinde olduğu gibi), "köpek"in (Örneğin, "kedi" ve "köpek" kelimelerini birbirine bağlayan bir ifade, ezberlenen listeyle bağlantısını gösteren bir ifadenin parçası olabilir.) Dolayısıyla, belirli bir kelimeyi ezberlerken, bu listeye ait olduğunu ve konu hakkında yapılan kısa bir aramada konunun izlediği tüm yolları gösteren bir etiket alır. Bu kelimenin t tanesi listede başka kelimelere yönlendiriyorsa aynı etiketi alır. Özünde: bu, listeyi ezberleyen öznenin onu belirli bir şekilde düzenlediği anlamına gelir. Ayrıca listedeki diğer kelimelerle bağlantı açısından özellikle zengin olan küçük bir kelime grubu seçilmesi gerekiyor. Listedeki sözcüklerle ilişkilendirmeler yapılırken bu "orijinal kümeye" özel bir önem verilir, çünkü bu kümedeki sözcükler çıkarma işleminde başlangıç noktaları olarak kullanılacaktır.

SOIIIOINLONpbfі HAKKINDA
<O slis'in sağlığını al
■— Listenin ilişkilendirmeleri
—•-■ LÖHÎIİJU11 SHYMMSHSGGISYY )
-L- Chitany yaap ^ mi spil
Pirinç. 1 1.7. Anderson ve Bower'ın modeli pr neіom daha düşük (Vesheg . L972a
)
A. ІІрTKOY CilbtCks İLE BAĞLANIN (h В gider VE СЛІ'СОКі), Listeden sözcükleri
bağlayan yollar da bir etiket alır; listedeki
bazı kelimelerden küçük bir
“ başlangıç seti ” oluşturulur
; at atom etiketli
kelimeler bulundu * tarih Buna dikkat edin. bazılarının yediği işaretlenebilir , içinde
(Щ çoğaltılır, siii bulunamadı ama Haziran zamanında a
(bir örnek "Bahçe"}); aynı zamanda, bazı kelimeler pbkl-
ruZhemr eri [[ ' ward, ancak cosiveTst &wincei': etiketi
olmadığı için oynatılmayacak (<Dereio> bir örnektir).
Anderson-Bower modeline göre ayıklama, (kısa süreli bellekte olabilecek tüm sözcüklerin ilk kez hatırlanmasından sonra) "başlangıç kümesi"nde yer alan sözcüklerle başlar. Bu kelimelerden biri seçilir ve liste etiketi ile ilişkili diğer kelimeler aranarak, bu kelimeye karşılık gelen CI'deki hücreden ilişkilendirme yolları izlenir. Bu durumda, verilen kelimeden ayrılan tüm yollardan geçmek imkansız olduğundan, arama yalnızca daha önce listedeki kelimelere götüren olarak işaretlenmiş yollar boyunca gerçekleştirilir. Aynı zamanda listeye ait olma ile ilgili etiketler taşıyan kelimeler varsa, bu kelimeler yeniden üretilir. Böyle bir süreç sonunda tek bir işaretli yolun olmadığı bir kelimeye götürürse, konu orijinal kümeye geri döner; ondan başka bir kelime alınır ve yolların incelenmesi yeniden başlar. Orijinal sette kullanılmayan tek bir kelime kalmadığında geri çağırma işlemi sona erer.
Bu modele göre, hatırlama sürecindeki hatalar, tek tek sözcüklere ve çağrışımsal yollara karşılık gelen hücrelerin işaretlenmesinin olasılıksal doğasından kaynaklanmaktadır. Bu, bir kelimenin mutlaka listede olarak işaretlenmeyeceği ve listedeki iki kelimeyi birbirine bağlayan bir yolun da mutlaka işaretlenmeyeceği anlamına gelir. Ayrıca, ilk setin bağlantılar açısından yeterince zengin olacağına ve böylece listedeki her kelimeye kendi kelimelerinden ulaşılabileceğine kesin olarak güvenmek imkansızdır. Bütün bunlar hatırlamada hatalara yol açar.
Anderson-Bower modeli genel olarak şu şekilde açıklanabilir. İlk olarak, ezberlenen unsurlar incelenir ve bunun sonucunda organizasyona tabi tutulurlar: onlar için bazı ortak isimlerle ve birbirleriyle ilişkilendirilirler. Ardından, bazı "anahtarların" (örneğin, listeyi oynatmaya başlama talimatı) yardımıyla geri çağırma başlatılır. Anahtar, geri çağırma işleminin başlaması gereken DP hücresine bir sinyal gönderir. Bu süreç, belirli bir anahtarla ilişkili farklı sözcüklerden ilişkilendirme yollarını izlemektir. Bu, hatırlanan kümeden etiketli öğeleri aradığı için arama işlemi olarak adlandırılabilir. Bu tür unsurlar bulunduğunda yeniden üretilirler. Bulmanın ve çoğaltmanın ayrı, ek bir aşama oluşturduğu unutulmamalıdır. Çeşitli DP yolları boyunca arama yaparken, ezberlenen kümeye dahil olmayan öğeler kaçınılmaz olarak ara sıra ortaya çıkacaktır. Örneğin, denekten Amerika Birleşik Devletleri başkanlarını hatırlaması istenirse, hafızasından Eisenhower'ın ve ardından Stevenson'ın adını geri getirebilir. Ancak Stevenson, Eisenhower ile ilişkilendirilse de, bu onun başkanlardan biri olduğu anlamına gelmez. Bu nedenle, arama sürecinde bulunan unsurlarla ilgili belirli kararlar alınmalıdır. Bu eleman verilen kümeye dahil mi değil mi? (Anderson-Bower modelinde bu soru farklı bir şekilde ifade edilmiştir: "Uygun şekilde işaretlendi mi, işaretlenmedi mi?") Dolayısıyla hatırlama, öğelerin aranması ve bulunan öğeler hakkında karar verilmesinden oluşan bir süreç olarak düşünülür.
Geri çağırma sürecinin bu şekilde karakterize edilmesiyle, bir dizi sorun ortaya çıkar: bu sürece ilişkin açıklamamız göründüğü kadar eksiksiz değildir. Bununla birlikte, Anderson ve Bower'ın çağrışımsal ağ modeli, hatırlama hakkında oldukça fazla bilgi sağlar; örneğin önceki bölümde tartışılan organizasyon etkilerini açıklamaya yardımcı olur. Görünüşe göre, aşağıdaki genel kural formüle edilebilir: Ezberlenen kümenin öğeleri arasındaki ilişkileri kolaylaştıran her şey, sonraki hatırlamayı kolaylaştırır. Bunun nedeni, herhangi bir organizasyonun, en azından biraz, ancak çalışma ve arama süreçlerini kolaylaştırmasıdır - öğeleri işaretleme ve onlardan ayrılan yolları izleme. Liste ilişkisel bir yapıya sahipse, öğeleri arasındaki yollar (bağlar) daha fazla sayıda ve daha "uygun" olacaktır.
TANIMA VE ÜREME SÜREÇLERİNİN KARŞILAŞTIRILMASI
Bu aşamada iki hipotezimiz veya "hatırlama" teorimiz var. Bilgi erişim teorileri olarak düşünülebilirler çünkü hafızada bir yerde saklanan bilginin nasıl tekrar kullanılabilir hale geldiği sorusuyla ilgilenirler. Bununla birlikte, iki teori tamamen farklıdır. Tanıma teorisi, izlerin "gücü" kavramına ve oldukça karmaşık bir karar verme sürecine dayanmaktadır. Hatırlama teorisi, çağrışımsal yollar ve arama gibi kavramlara dayanır. Bilgi alma, tanıma veya hatırlama üzerine çalışmamıza bağlı olarak farklı süreçleri içeriyor gibi görünüyor. Ancak tanıma ve hatırlamada bilgi çıkarma süreçleri gerçekten farklı mı? Ve eğer farklılarsa, o zaman ne şekilde?
EŞİK HİPOTEZİ
Tanıma ile hatırlama arasındaki farkın ne olduğu sorusu yeni değil. Bu sorun, tanıma ve hatırlama kavramlarının ilk kez net bir şekilde ayırt edilmesinden ve tanıma testlerinde bellek etkinliğinin daha yüksek olduğunun fark edilmesinden (McDougall, 1904) beri psikologların ilgisini çekmemiştir. Bu farkı açıklamaya yönelik ilk girişimlerden biri "eşik hipotezi" idi. Bu hipotez çok basittir: Hem tanımanın hem de hatırlamanın etkinliğinin, bellekteki öğelerin "gücüne" (yani izlerinin etkinliğine) bağlı olduğunu belirtir. Bu hipoteze göre bir elementin tanınabilmesi için gücünün belli bir değere ulaşması gerekir ki buna tanıma eşiği denir. Bir öğenin hatırlanması için gereken belirli bir güç de vardır; bu değere hatırlama eşiği denir . Hatırlama eşiğinin tanımadan daha yüksek olduğu varsayılır; hipotezin özü budur.
Bunun ne anlama geldiğini görelim. Her şeyden önce, bundan, çok yüksek güce sahip bazı unsurların hem hatırlanacağı hem de tanınacağı sonucu çıkar. Çok düşük güce sahip diğerleri ne hatırlanabilir ne de tanınabilir. Son olarak, üçüncü - orta güçte (tanıma eşiğinin üzerinde, ancak hatırlama eşiğinin altında) - tanınacak, ancak geri çağrılmayacaktır. Bu, tanıma testinin genellikle hatırlama testinden daha iyi sonuçlar verdiği gerçeğini açıklamaya yardımcı olur.
Kintsch (1970), eşik hipotezinin lehinde ve aleyhinde olan kanıtların gözden geçirilmesine dayalı olarak tanıma ve hatırlamanın ayrıntılı bir karşılaştırmasını yaptı. Herhangi bir değişken tanımayı ve hatırlamayı aynı şekilde etkiliyorsa, bunun eşik hipotezi lehine bir argüman olarak kabul edilebileceğini belirtir. Ancak bu iki süreç üzerinde farklı etkide bulunacak en az bir değişken bulmak mümkün olursa, bu, hipotezin geçerliliği konusunda şüphe uyandıracaktır. Eşik hipotezini destekleyen argümanlardan biri, bu bölümde bahsedilen, unutmanın zaman içinde farklı şekilde ilerlemesine rağmen, hem tanıma hem de yeniden üretim sırasında sunum ve test arasındaki aralıktaki öğelerin sayısının bir fonksiyonu olduğu ve eğri unutma şekli her iki durumda da aynıdır. Listenin sunulma oranı ve sunulma sayısı gibi değişkenler de aynı etkiye sahiptir; her iki durumda da dizideki yere benzer bir bağımlılık vardır - başlangıcın etkisi ve sonun etkisi (Shiffrin, 1970; ayrıca bkz. Bölüm 2). Bahsedilen faktörlerin öğelerin gücünü artırdığını veya azalttığını varsayarsak, tüm bunlar eşik hipotezi temelinde kolayca açıklanabilir, böylece sırasıyla tanıma ve hatırlama verimliliği değişir. aynı yön.
Şimdi, tanımayı iyileştiren ancak hatırlamayı kötüleştiren bir değişkenin bulunduğunu varsayalım. Tanıma etkinliğindeki artış, yapılan değişikliğin bellekteki öğelerin gücünü artırdığı, ancak hatırlamadaki bozulmanın tam tersi etkiyi gösterdiği anlamına gelir. Ancak eşik hipotezi, her iki etkiyi de aynı fikir temelinde açıklamaya çalıştığından, bu tür gerçekler onu reddedilmeye zorlayabilir. Çünkü hem tanıma hem de hatırlamanın altında yatan yalnızca bir mekanizma varsa, o zaman her bir değişken faktör yalnızca bir yönde değişikliğe neden olabilir: tanıma ve hatırlama iyileşebilir veya her ikisi birden kötüleşebilir, ancak farklı yönlerde değişemezler.
Tanıma ve hatırlamayı farklı şekilde etkileyen değişkenler var mı? Görünüşe göre bu tür birkaç değişken var (Kintsch, 1970). Bunlardan en önemlisi kelime sıklığıdır. Belirli bir kelimenin sıklık tahmininin, onun doğal dildeki geçişine göre belirlendiğini hatırlayın. Yaygın olarak kullanılan kelimelerin, nadir bulunan kelimelerden daha iyi hatırlandığı defalarca belirtilmiştir. Ceteris paribus, eğer deneklere bir kelime listesi sunulursa ve bu kelimeleri yeniden üretmeleri istenirse, bu liste sık sık geçen kelimeleri içerdiğinde hatırlama etkinliği, nadir kelimelerden oluştuğu duruma göre çok daha yüksek olacaktır. Ancak tanıma yapıldığında tam tersi sonuçlar elde edilir. Sık tekrarlanan kelimeler listesine dahil edildiğinde tanıma testi, nadir kelimelerin dahil edilmesine göre daha kötü sonuçlar verir. Nadiren geçen kelimelerin tanınması daha kolaydır. Bu değişkenin (ve tanıma ve hatırlamayı farklı şekilde etkileyen diğer değişkenlerin) etkisi, eşik hipotezinin tanıma ve hatırlama arasındaki farkları açıklamakta başarısız olduğunu göstermektedir.
İKİ İZ HİPOTEZİ
Başka bir hipotez (Adams, 1967) iki ayak izi hipotezi olarak adlandırılabilir. Eşik hipotezinin aksine, tanıma ve hatırlamanın farklı mekanizmalara, yani bellekte bulunan farklı bilgi kümelerine bağlı olduğunu belirtir. Bu hipoteze göre, herhangi bir öğenin sunumu, bellekte iki bilgi kompleksinin oluşmasına yol açar. (Böyle bir bilgi kompleksine genellikle iz denir ; genel olarak, bir olayın hafızadaki izi, olayın kendisi geçtikten sonra içinde kalan şeydir.) Hafızanın dilsel (sözel) izleri ve mecazi (algısal) izleri vardır. İlki, şu veya bu olayı (veya nesneyi) sözlü bir biçimde ve ikincisi, duyusal algısına daha yakın bir biçimde temsil eder. Örneğin, - görsel sunumdan sonra BÜYÜK kelimesi, anlamlı bir sözel öğe veya mecazi bir biçimde saklanabilir. Bu hipoteze göre, tanıma algısal bir ize dayanırken, üreme yalnızca sözel bir ize dayanır. Ch'de. 12 hayali iz daha ayrıntılı olarak ele alınacaktır; ancak, bu İKİ iz hipotezinin bir eksikliğini, listedeki kelimelerle yüksek oranda ilişkili çeldiricilerden tanımanın nasıl etkilendiğini düşünürsek, şimdi bile görmek kolaydır. Burada semantik benzerliğin olumsuz bir etkisi vardır: Çeldirici öğeler liste öğeleriyle yakından ilişkili olduğunda tanıma bozulur. Tanımanın sözel izlerden çok algısal izlere dayandığı iki iz hipotezi, bu gözlemleri açıklamakta başarısız olur.
İKİ SÜREÇ HİPOTEZİ
Tanıma ve hatırlama arasındaki farkı açıklamak için önerilen üçüncü bir hipotez, iki süreç hipotezidir (Anderson ve Bower, 1972; Kintsch, 1970). Son yıllarda bu hipoteze çok dikkat edildi. Avantajı, sadece belirtilen farklılıkları açıklamakla kalmaz, aynı zamanda tanıma ve hatırlama teorilerini birleştirmeyi de mümkün kılar. İki süreç hipotezi, dayanıklılık anlayışımız (tanımaya uygulandığı şekliyle) ve arama süreçleri (hatırlamaya uygulandığı şekliyle) arasındaki tutarsızlıkları düzeltir. Bu, bu hipoteze göre hatırlamanın (yeniden üretmenin) bir alt süreç olarak tanımayı içermesinden kaynaklanmaktadır. Daha önce açıklanan teoriye göre, hatırlamanın arama (DP'deki yolları izleme ve gerekli öğeleri bulma) ve karar verme (bulunan öğeleri yeniden üretip üretmeme) süreçlerinden oluştuğunu hatırlayın. İki süreç hipotezinde, bu tür bir olaylar dizisi hatırlama için bir model olarak alınır ve ek olarak, tanımanın karar verme sürecine karşılık geldiği varsayımı getirilir; başka bir deyişle, hatırlama, arama ve tanımadan oluşur. Karar verme aşamasında, tanımada yer alan aynı süreçlerin - sinyal algılama teorisi tarafından açıklanan süreçlerin - gerçekleştiği varsayılmaktadır. Böylece, tanımanın özünde arama süreçlerinin hariç tutulduğu hatırlama (yeniden üretme) olduğu sonucuna varıyoruz.
Açıkçası, iki süreç hipotezinin önemli bir değeri vardır. Bellekte depolanan aynı türdeki bilgilerin tanıma ve yeniden üretim için kullanıldığını varsayarsak, (iki iz hipotezinden farklı olarak) mevcut listeye başka bir tür bellek eklemekten kaçınır. Hatırlamaya katılım ve birbirinden ayrılabilen süreçlerin tanınması, bazı faktörlerin neden bu iki hafıza tezahürünü farklı şekilde etkilediğini anlamamızı sağlar. Ayrıca, sağlamlık kavramını tanınabilirlik için tutarak, sinyal algılama modelinin açıkladığı tüm verileri açıklayabilir. Ve tüm bunlara rağmen, malzemenin düzenlenmesinin yeniden üretimini neden kolaylaştırdığını anlamayı mümkün kılan hatırlamaya dahil olan arama süreçlerine yer vardır (bkz. Bölüm 10). Dolayısıyla, bağımsız tanıma ve hatırlama teorilerimizi birleştiren iki süreç hipotezi, bu iki teorinin erdemlerini birleştiriyor gibi görünüyor.
İki süreçli modelin sahip olduğu görünen, zaten bilinen gerçekleri açıklama yeteneğinin yanı sıra, iki süreçli model lehine ne tür verilere sahibiz? Bazı faktörlerin geri çağırma sürecinin iki bileşenini - arama ve karar verme - farklı şekilde etkilediği ortaya çıkarsa, bu model yeni bir destek alacaktır. Bu tür veriler, eğer elde edilebilirlerse, en azından bu iki aşamanın birbirinden ayrılma olasılığını doğrular, ki bunun izolasyonu tartışılan modelin önemli bir özelliğidir. Bu yöndeki deneylerden biri Kintsch (Kintsch, 1968) tarafından gerçekleştirilmiştir. Hem tanıma yöntemini hem de hatırlama yöntemini kullanarak sınıflara ayrılabilen listelerin ezberlenmesini tanımladı. Deneylerinde iki tür liste kullanıldı: kelimelerin her birinin kendi sınıfının adıyla güçlü bir şekilde ilişkilendirildiği listeler ve düşük derecede ilişkilendirme içeren listeler. Bu kelime seçimi sayesinde, Kinch esasen listelerin yapı seviyesini değiştirmiştir. Beklendiği gibi, düşük yapılandırılmışlıkta serbest hatırlamanın yüksek yapılandırılmışlığa göre daha az etkili olduğu, ancak her iki liste için de tanıma etkinliğinin aynı olduğu ortaya çıktı. Bu sonuçlar, liste yapısının hatırlama sürecinde geri alma aşamasını etkilediği, ancak hatırlama veya tanımada karar aşamasını etkilemediği fikriyle tutarlıdır. Diğer yazarlar ayrıca, liste düzenleme derecesindeki farklılıkların hatırlamayı etkilemeden hatırlamayı etkilediğini bulmuşlardır (örneğin bkz., Bucce ve Pagan, 1970).
Şimdiye kadar tanımladığımız iki süreçli model, yeniden üretim ve tanıma ile ilgili önemli fenomenlerin çoğunu açıklıyor gibi görünse de , Anderson ve Bower (1972) bir modifikasyon getirme ihtiyacına işaret ediyor. Onların görüşüne göre, sinyal algılamaya dayalı bir tanıma modelinde (ve dolayısıyla iki süreçli bir modelin karar aşamasında) kullanılan "güç" kavramı savunulamaz. Bu yazarlar, basit bir güç teorisinin sözde "liste farklılaşmasını" açıklamadığına işaret ediyor. Bu, deneklerin, içerdikleri birkaç listeden hangisine bağlı olarak öğeleri ayırt etme yeteneğini ifade eder. Bu yetenek çok önemlidir: örneğin denekler, belirli bir öğenin birinci ve dördüncü listelerde yer alıp almadığını veya ikinci ve üçüncü listelerde sunulup sunulmadığını yanıtlayabilir (Anderson ve Bower, 1972). Başka bir örnek verelim. Liste 1 on kez ve liste 2 yalnızca bir kez sunulduysa, liste 2 sunulduktan sonraki testte liste 1'deki öğelerin liste 2'deki öğelerden daha güçlü olması beklenir. 1. listedeki öğeler, 2. liste tanıma testinde çeldirici olarak kullanılırsa, yanlışlıkla bu listenin öğeleri olarak tanınmaları gerekir. Bu arada, gerçekte, bu durumda 1. listenin öğeleri ile 2. listenin öğeleri arasında ayrım yapma etkinliği, olağan yöntemle gerçekleştirilen tanıma testlerinden bile daha yüksektir (Winograd, 1968). Kısacası, basit güç teorisi, bu öğenin gücü listedeki öğelerin gücü kadar veya ondan daha yüksekse, öznenin bu öğenin başka bir listenin parçası olduğunu nasıl belirleyebileceğini anlamamıza izin vermez. şu anda test ediliyor. Bu nedenle, listelerin farklılaşması, kuvvet teorisi için bir zorluk yaratır.
Anderson ve Bower (Anderson ve Bower, 1972), liste farklılaştırması ve tanımanın temelde aynı süreçler olduğunu öne sürdüler: Bir özne, belirli bir öğeyi belirli bir listenin bileşenlerinden biri olarak tanıdığında, bu, özünde, ne zaman farklı değildir? kendisine sunulan tek listede yer alan bir unsur olarak tanır. Bu akıl yürütmeye göre "güç" tek başına liste farklılaştırması için bir temel oluşturamayacağından, tanıma ve çoğaltma modelleri oluşturmak için kullanılamaz. Bir alternatif olarak, bu yazarlar "bağlamsal güç" olarak adlandırılabilecek şeyi öne sürdüler. Bu terimin anlamını anlamak için, konuya herhangi bir kelime listesinin sunulmasının her zaman sıcaklık, günün saati, durum gibi çok çeşitli faktörlerden oluşan belirli bir "bağlamda" gerçekleştiği gerçeğiyle başlamalıyız. deneğin midesi, deneyi yapanın saçının rengi vb. Tüm bu faktörler birlikte bağlam oluşturur. Denek listeyi öğrendiğinde, bu bağlamsal faktörlerin DP'deki "verilen liste" etiketiyle ilişkilendirildiği varsayılır. Ve bu etiket sırayla listedeki sözcüklerle ilişkilendirilir (tamamen daha önce tartışılan ücretsiz hatırlama modelinde olduğu gibi).
Şimdi, Anderson ve Bower'a göre bir test sırasında neler olduğunu görelim. Denek, kelimeleri hafızasında aramaya başlar ve onları bulur (veya bir tanıma testi söz konusu olduğunda, sunulan öğeler tarafından doğrudan onlara yönlendirilir), ardından bulunan her kelime için kelimeye dahil edilip edilmediğine karar vermelidir. testin yapıldığı liste. Bunu, bir kelimeyi kendi izinin gücüne veya heyecanına göre değil, o kelime ile belirli bir listenin bağlam faktörleri arasındaki ilişki derecesine göre yargılayarak yapar. Örneğin, denekten 2. listedeki kelimeleri hatırlaması istendiğinde, hafızasından bazı kelimeleri geri çağırır; daha sonra liste 2 bağlam faktörü ile yeterince ilişkili olup olmadığını görmek için her birini teste tabi tutar.Eğer ilişkilendirme yeterliyse, kelimeyi yeniden üretir, değilse, onu atar. Bu teorinin listeleri ayırt etme yeteneğini nasıl öngördüğünü görmek kolaydır: farklılıklar küçük olsa bile her listenin farklı bir bağlamı vardır. Hatta deneklerin kendilerine verilen bir kelimenin sunulduğu bağlamı tanımlayabilmeleri beklenebilir ve çoğu zaman bunu gerçekten yapabilirler. Bu teori ayrıca, yalnızca bir liste olduğunda bir listeyi "farklılaştırma" şeklindeki daha basit problemdeki tanıma için de geçerlidir.
Anderson ve Bower, iki süreçli modellerini doğrulamak için, tanıma ve hatırlama üzerinde farklı etkileri olan bir listenin içeriğini değiştirdikleri deneyler yaptılar. Denekler bir dizi listeyi ezberledi; her liste, 32 kelimelik sınırlı bir "stoktan" alınan 16 kelime içeriyordu, bu nedenle listeler önemli ölçüde örtüşüyordu. Deneylerden birinde, her listenin sunumundan sonra, denek önce ana gruptan mümkün olduğu kadar çok kelimeyi hatırlamaya çalışmak zorunda kaldı, yani kendisine daha önce sunulan tüm kelimeleri, hangi listeye ait olursa olsun hatırladı. . Daha sonra denekten bu kelimelerden hangisinin en son sunulan listeye ait olduğunu belirtmesi istendi. Tabii ilk listeden sonra kontrol edildiğinde hatırlayabildiği tüm kelimeler o listeye aitti. Bununla birlikte, sunulan listelerin sayısı arttıkça durum değişti: konu, ana fondan giderek daha fazla kelimeyi yeniden üretti. Bu şaşırtıcı değildir, çünkü bellekte yer alan sözcükler giderek daha sık ezberlendikçe tüm sözcük kümesini bellekten (ana fon) geri alma yeteneğinin artması beklenebilir. Ancak deneğin en son sunulan listede hangi kelimelerin olduğunu bulma yeteneği, liste sayısı arttıkça azalmıştır. Yazarlara göre bunun nedeni, artan sayıda örtüşen listelerin sunulmasının bir sonucu olarak, aynı kelimelerin artan sayıda farklı bağlamlarla ilişkilendirilmesinden kaynaklanmaktadır. Sonuç olarak, son listedeki kelimeleri diğerlerinden ayırt etmek için bağlamsal faktörleri kullanmak gittikçe zorlaşmakta ve bu kelimelerin "tanıma" etkinliği azalmaktadır. Ek olarak, bu deney, tanıma verimliliğindeki düşüşü, iki süreç modelinin lehine bir kanıt olan hatırlama sonuçlarındaki iyileşmeden ayırmayı mümkün kıldı.
Şimdi kısaca özetleyelim. Bilgi çıkarımını açıklamak için iki süreçli bir hipotezimiz var. Bu hipoteze göre hatırlama şu şekilde gerçekleşir. Bilgi alımı için uygun "anahtar", uzun süreli belleğe uygun noktada "girmenizi" sağlar. Bu noktadan itibaren, bir öğeden diğerine önceden öğrenilmiş çağrışımsal yollar boyunca yürütülen arama başlar. Ne zaman bu arama bir öğeye yol açsa, tanıma süreci devreye giriyor. Bu öğe geri çağrılacak kümede yer alıyor mu? Evet ise, çoğaltılır; değilse, arama devam eder. Bu geri alma teorisinden, "anahtar" ile ezberlenen öğeler arasındaki veya bu öğelerin kendileri arasındaki ilişkileri kolaylaştıran herhangi bir faktörün (örneğin, sınıflandırma için uygun bir yapı veya aracılık) malzemenin ilk organizasyonunu kolaylaştırdığı genel kuralı gelir. ve istenen unsurların aranması ve dolayısıyla ve bunların hatırlanması.
Tulving ve Thomson (Tulving ve Thomson, 1973), bilgi çıkarma modelimizde daha fazla değişiklik gerektiren sonuçlar bildirdi. Bu yazarların işaret ettiği gibi, iki süreçli modele göre, hatırlama, tanıma ve başka bir süreçten (arama) oluştuğu için, tanıma asla hatırlamadan daha kötü olmamalıdır. Hatırlama tanımaya bağlı olduğu için, asla tanımadan daha etkili olamaz; aynı veya daha az verimlilikle gerçekleşebilir. Bu arada Tulving ve Thomson oldukça ustaca bir yöntemle hatırlamanın tanımadan daha etkili olabileceğini gösterdiler. Denekler 24 maddelik listeleri ezberledi. Her öğe, kendisiyle zayıf bir şekilde ilişkilendirilen bir diğeriyle aynı anda sunuldu; örneğin SOĞUK elementi "toprak, SOĞUK" şeklinde sunuldu. Listenin sunumundan sonra, liste öğeleriyle ilişkili öğelerin "anahtar" rolünü oynadığı bir çoğaltma testi gerçekleştirildi; böylece denekler, ana kelimeleri hatırlama zamanı geldiğinde bu ilişkili kelimelerin yararlı olduğunu öğrendiler. Ancak, bu tür iki listeden sonra, Tulving ve Thomson beklenmedik bir şekilde çekin sırasını değiştirdi. Deneklere "anahtar" unsurlar içeren normal üreme testini değil, bir dizi başka testi sundular. Spesifik olarak, deneklere liste öğeleriyle güçlü bir şekilde ilişkili sözcükler sundu ve onlardan bu sözcükleri serbest çağrışım için uyaran olarak kullanmalarını istedi.
Örnek olarak, öznenin "toprak" kelimesiyle zayıf bir şekilde ilişkilendirilen listenin bir öğesi olarak SOĞUK kelimesiyle ilk kez sunulduğu durumu ele alalım. Şimdi ona SICAK (SOĞUK kelimesiyle oldukça ilişkili) kelimesi teklif ediliyor ve onunla özgürce ilişkilendirmesi isteniyor. Daha önce sunulan listede JAR kelimesi yoktu, bu tür kelimelere "liste dışı anahtarlar" denir. Bu koşullar altında, denekler genellikle listede yer alan kelimeleri, liste dışı kelimelerle ilişkili bileşenler olarak yeniden üretirler. Örneğin, öznenin "soğuk" kelimesini HEAT kelimesiyle ilişkilendirerek yeniden üretmesi kuvvetle muhtemeldir. Serbest çağrışım testini tamamladıktan sonra deneklerden bu testte adlandırdıkları kelimelerden hangilerinin ilk listede yer aldığını belirtmeleri istendi. Örneğimizde, denek ZHAR uyarıcı kelimesi sunulduğunda "soğuk, sıcak, güneş, ateş" diye cevap verdiyse, o zaman "soğuk" kelimesinin listede yer aldığını belirtmesi gerekir. Kısacası "soğuk" kelimesini öğrenmesi gerekiyordu. Burada beklenmedik sonuçlar elde edildi: deneklerin bu görevi çok kötü yerine getirdikleri ortaya çıktı. Bu deneylerden birinde denekler, bir serbest çağrışım testinde yazım hatasına dahil edilen 24 kelimeden 18'ini yeniden üretti, ancak bunlardan yalnızca 4'ünü tanıdı. Başka bir problemde, orijinal listeden zayıf ilişkili bileşenler anahtar olarak verildiğinde, bu 24 kelimenin 15'ini hatırlayabildiler. Böylece, (uygun ipuçları verildiğinde) hatırlama yeteneklerinin, tanıma yeteneklerinden daha yüksek olduğu ortaya çıktı.
Tulving ve Thomson tarafından verilen, hatırlamanın tanımadan daha iyi performans gösterdiği örnek, kodlamanın özgüllüğünün başka bir örneğidir (bkz. Bölüm 10). Görünüşe göre denekler listedeki kelimeleri kendilerine sunulan zayıf çağrışımlar bağlamında kodlamışlar. Bu nedenle, farklı türde anahtarlar kullanamadılar - güçlü ilişkilendirmeler. Bu, iki süreç hipotezinden beklenenin tersidir; Görünüşe göre herhangi bir anahtar ve özellikle güçlü ilişkilendirmeler, arama sürecine yardımcı olarak hatırlamayı kolaylaştırmalıdır. Görünüşe göre, öğelerin kodlandığı ve doğrulandığı durum, bu öğelerin tanınması ve yeniden üretilmesi arasındaki ilişki üzerinde güçlü bir etkiye sahip olabilir. Kodlama, orijinal depolamanın koşulları hakkında çok özel bilgileri dikkate alabilir ve bunun sonucunda, kodlamanın gerçekleştirildiği tüm bağlam yeniden üretilmedikçe geri alma neredeyse imkansızdır.
TANIMA ARAMA SÜREÇLERİ
İki süreçli modellerinin daha yeni bir versiyonunda, Anderson ve Bower (1974), AHR modellerinde (8. Bölümde tartışılmıştır) hatırlamadaki rolünü tanımlayarak bağlamı kodlamanın önemini vurgulamaktadır. Ana birimi ifade olan AFC'nin yapısı, Anderson ve Bower modelinin önceki versiyonu göz önüne alındığında "bağlamın işaretleri" dediğimiz şeyi genişletilmiş bir biçimde sunmamıza olanak tanır. Bağlam özniteliği, verilen listenin sunulduğu belirli koşulları açıklayan bir ifade olarak tanımlanabilir. Anderson ve Bower, modelde bir değişiklik daha yaptılar: tanımanın, tıpkı hatırlama gibi, bir arama bileşeni içerdiğini varsaydılar; tanıma arama işlemi, tanıma için sunulan öğeye karşılık gelen bellek konumuna erişimi açmayı amaçlar. Bu varsayım, kodlama özgüllüğünün etkisini hesaba katmaya yardımcı olduğu için çok önemlidir. Geleneksel deneylerde, bir kelimenin tanınması test edilirken, bu kelimeye karşılık gelen bellek hücresi genellikle hemen bulunabilir. Bununla birlikte, belirli kodlama koşullarıyla yapılan deneylerin sonuçlarının gösterdiği gibi, bu işlem çok zor olabilir ve belirli bir kelimenin tanınması kontrol edilirken, değerinin depolandığı hücreye erişim hiçbir şekilde garanti edilemez.
Tanınmanın sadece karar vermekle sınırlı olmadığını, arama bileşenini de içerdiğini gösteren başka veriler de var. Benzer bir görüş Mandler ve çalışma arkadaşları tarafından da paylaşılmaktadır (Mandler, 1972; Mandler a.o., 1969). Bunun önemli bir teyidi, tanımanın listenin organizasyon derecesinden etkilendiğini gösteren bazı deneylerin sonuçlarıdır. Bu verilerin, daha önce tartışılan ve listenin düzenlenmesinin hatırlamayı etkilediğini ancak tanımayı etkilemediğini gösteren deneylerin sonuçlarıyla doğrudan çeliştiğine dikkat etmek önemlidir (örneğin bkz. Kintsch, 1968). Bununla birlikte, oldukça fazla kanıt, özellikle yüksek düzeyde yapılandırılmış listelerle yapılan deneylerde (Bower a.o., 1969; D'Agostino, 1969; Lachman ve Tuttle, 1965), listenin organizasyonunun da tanımayı etkileyebileceğini göstermektedir. Ve genellikle listenin düzenlenmesinin karar verme aşamasını değil, arama süreçlerini etkilediğine inanıldığı için, bu nedenle tanıma, aramanın bazı unsurlarını içerir.
Mandler ve ark. (Mandler a. o., 1969), liste yapısının tanımayı etkilemesinin olası yollarından birine dikkat çekti. Bir tanıma testinde, deneklerin bazı öğeleri kendinden emin bir şekilde "eski" veya "yeni" olarak atadığına, buna karşın bir veya diğer gruba tereddüt etmeden atayamayacakları bilinen sayıda eski ve yeni öğe olduğuna inanırlar. Bu unsurlar "çıkarma yoluyla doğrulamaya" tabi tutulmalıdır. Bu test, verilen öğeyi hatırlamanın mümkün olup olmadığı, yani görev hatırlama olsaydı, arama işlemi sonucunda onu bulmanın mümkün olup olmayacağı sorusunu gündeme getirir. Bu sorunun cevabı evet ise eleman eski, aksi halde yeni olarak adlandırılacaktır. Organizasyonun tanımayı etkilemesine neden olan, hatırlamadaki arama süreçleriyle aynı şekilde organizasyondan etkilenen bu geri alma yoluyla doğrulamadır.
Benzer bir model Atkinson ve Juola tarafından önerildi (Atkinson ve Juola, 1973). Listenin sunumundan sonra bir tanıma kontrolü yapılırsa, deneklerin önerilen öğelerin bazılarını hemen liste öğelerine veya çeldiricilere atfettiğine inanırlar; ancak, diğer unsurlar için, kişinin yanıt vermeden önce DP'de kapsamlı aramalar yapması gerekir. Bu modele göre, DP'deki bu arama, Sternberg'in PC tarama deneylerinde varsayılana benzer (bkz. Bölüm 7).
Arama süreçlerinin tanımaya katılımına ilişkin bu verilerle bağlantılı olarak, iki sürecin hipotezinde bir dizi önemli değişiklik yapılması gerekli hale geldi. Anderson ve Bower (Anderson ve Bower, 1974), "dört süreç hipotezi" olarak adlandırılabilecek şeyi kullanarak tanıma ve hatırlama arasındaki ilişkiyi tanımladılar. Bilgi çıkarma sürecinde dört alt süreci ayırt ederler: 1) istenen öğelere karşılık gelen hücrelerin aranmasında ilişkisel yolların incelenmesi; 2) bulunan öğenin gerçekten hatırlamaya tabi olup olmadığını bulmak için bağlamsal bilgilerin incelenmesi; 3) anlamını çıkardıktan sonra kelimenin çoğaltılması (DP'de karşılık gelen hücreyi bulmak); 4) kelimenin sunumu üzerine anlamı (DP'deki hücreler) bulmak. Bu süreçlerin ilk üçü hatırlamanın bileşenleri iken, ikinci ve dördüncüsü tanıma ile ilgili görünmektedir. Bu nedenle, iki süreç hipotezinin varsaydığı gibi, tanıma ve hatırlamada ortak bileşenler vardır. Bununla birlikte, dört işlem seçeneği, tanıma ve hatırlama arasında daha önce düşünülenden daha karmaşık bir ilişki anlamına gelir.
Son iki bölümde tam bir daire çizdik. İlk olarak, bizi tüm karmaşıklığıyla bilgi çıkarma sorununu çözmeye zorlayan kodlama sürecine odaklandık. Bu da bizi kodlamanın önemi fikrine geri getirdi. Genel olarak, belleğin işlevlerine ilişkin bu tartışma, insan bilgi işleme sisteminin dikkate değer derecede verimli ve esnek bir sistem olduğu izlenimimizi güçlendirdi.
Bölüm 12
Uzun süreli bellekte görsel temsiller
Bu bölümün ana teması olan D11'de yer alan görsel bilgilerin rolü, önceki bölümlerde bir ölçüde tartışılmıştır. Örüntü tanımaya baktığımızda, insanların karmaşık görsel uyaranları belirli anlamlı kategorilere nasıl atadıklarını anlamak için LTP'nin farklı uyaranların görsel özellikleri hakkında bilgi içerdiğini varsaymamız gerektiğini gördük. Özellik listeleri, prototipler veya dahili bir kopya oluşturmak için kurallar gibi bu bilgileri sunmanın olası biçimlerine baktık. Kısa süreli bellekteki görsel temsilleri tartışırken, uzun süreli bellekte depolanan bilgilere dayanarak yeniden oluşturulmuş iyi bilinen görsel görüntülerin (örneğin, alfabedeki harfler gibi) CP'de var olma olasılığını öne sürdük. Bu tür iç görsel görüntülerin döndürülebileceğini ve diğer uyaranlarla karşılaştırma için kullanılabileceğini belirledik. Arabuluculuğu göz önünde bulundurarak, kelime çiftlerini ezberlerken "zihinsel resimler" kullanmaları talimatı verilen deneklerin, bu tür özel talimatlar almayan deneklere göre daha yüksek hatırlama verimliliğine sahip olduğunu bulduk. Ve Shepard'ın (1967) tanıma konusundaki çalışmasını tartışırken, deneklerin yalnızca bir kez gördükleri çok sayıda resmi tanıyabildiklerini gördük.
Bu bölüm görsel hafızaya odaklanacaktır. Özellikle "görsel imge" kavramının anlamını açıklığa kavuşturmamız gerekecek. görüntü nedir? Bu nasıl kullanılabilir? DP'de gerçekten saklanan herhangi bir resim var mı? Evet ise, neye benziyorlar? Tüm bu sorular açıklama sırasında ortaya çıkacak, ancak yer yetersizliğinden dolayı mecazi hafıza gibi karmaşık bir konuya hak ettiği ilgiyi göstermemiz pek mümkün değil.
Görüntüler bellekte saklanıyor mu? Tamamen öznel fikirlere dayanarak, bu soru olumlu olarak yanıtlanabilir. Örneğin, bir kişinin dairesinin mutfağında (veya kendisi tarafından iyi bilinen başka bir dairede) kaç pencere olduğu sorusuna nasıl cevap verdiğini düşünün. Shepard'ın (1966) işaret ettiği gibi, böyle bir soruyu yanıtlarken, kişi söz konusu mutfağın zihinsel bir resmini veya görüntüsünü yaratıyor ve ardından zihinsel olarak etrafına bakıp içindeki pencereleri sayıyor. Başka bir örnek olarak (7. Bölüm'de anlatılmıştır), harfleri ve R'yi karşılaştırdığınızda ne olduğunu düşünün. ikinci? Bu soruyu cevaplarken, eğik figürü zihinsel olarak dik duracak şekilde çevirdiğinizi hissedebilirsiniz. Figürün kendisi hareketsiz kaldığı için, bazı zihinsel imgelerin hareket etmesi gerektiği açıktır. Bununla birlikte, zihinsel bir görüntü yaratıyor gibi görünen öznel bir izlenimin bu tür ikna edici gösterileri, herhangi bir resmin beyinde saklandığı anlamına gelmez; Ya da belki buna gerçekten tanıklık ediyorlar?
ŞEKİLLİ BİLGİLER İÇİN HAFIZA
Hafızamızda görsel imgeler var mı? Bu konu halen tartışmalı olsa da, hafızanın gözle algılanan olaylar hakkında bilgi depoladığına şüphe yoktur. Örneğin, çizgi filmlerde bile birçok farklı açıdan ve farklı koşullar altında yüzleri tanıma yeteneğimizi ele alalım. Peki ya sahneleri hatırlama yeteneğimiz? Bu insan yetenekleri deneysel olarak araştırılmıştır; özellikle Shepard (1967), insanların sıradan nesnelerin görüntülerini hatırlayabildiklerini gösterdi. Bu tür deneyler daha da geliştirildi. Standing ve işbirlikçileri (Standing a.o., 1970), deneklere her biri 10 saniye süreyle 2560 slayt sundu. Bu slaytların bir kısmıyla yürütülen bir takip testinde, denekler vakaların %90'ında doğru cevaplar verdi. Böylesine yüksek bir tanıma verimliliği göz önüne alındığında, deneklerin hafızasının bu slaytların sözlü açıklamalarını değil, başka bir şeyi, belki bir tür "resimsel" bilgiyi içerdiği düşünülebilir. Ne de olsa 2560 resmi anlatmak için kaç kelime gerekir! (Her resim için bin kelime harcanması gerektiğini kabul edersek, toplam 2.560.000 kelime gerekecektir!)
Figüratif belleğin varlığı lehine olan diğer veriler Shepard ve Chipman tarafından sağlanmaktadır (Shepard ve Chipman, 1970). Deneklere 105 kartlık bir deste verdiler. Her kartta, 15 eyaletlik bir gruptan alınan iki ABD eyaletinin adları yazılmıştır (105 kart, 15'e 2'lik tüm olası kombinasyonları tüketir). Deneklerden bu 105. kartları üzerlerinde temsil edilen durumların ana hatlarının benzerliğine göre düzenlemeleri istendi. İlk sıra, şekil olarak en çok benzeyen iki duruma, ardından geri kalanlardan en çok benzeyen iki duruma verilecekti ve bu böyle devam etti. Böylece, en küçük seri numaraları şekil bakımından en büyük benzerliğe karşılık geliyordu. Sıra sayıları bir mesafe ölçüsü olarak da düşünülebilir; o zaman en küçük sayı (ve dolayısıyla en büyük benzerlik), şekil açısından iki durum arasındaki minimum "mesafeye" karşılık gelir.
105 durum çifti için bu tür benzerlik puanları elde eden Shepard ve Chipman, bu verileri çok değişkenli bir ölçekleme programı kullanarak işledi. Bölümde daha önce bahsedildiği gibi. Şekil 8'de, çok boyutlu ölçeklendirme, öğe çiftleri arasındaki yakınlık ölçülerini kullanır ve bu öğelerin çok boyutlu bir uzayda dağılımını, bu uzayda aralarındaki mesafeler benzerlikleriyle ters orantılı olacak şekilde açıklar. Ayrıca, ortaya çıkan alanın boyutuna göre, deneklerin benzerlik değerlendirmelerini neye dayandırdıklarına karar verilebilir. Şek. Şekil 12.1, Shepard ve Chipman'ın 15-durum deneylerinde elde ettikleri benzerlik puanlarına dayalı olarak program tarafından oluşturulan iki boyutlu uzayları göstermektedir. Bu şekilden de görülebileceği gibi, devletler 4 gruba ayrılmıştır: 1) küçük, düzensiz şekilli, dalgalı kenarlı (şeklin alt kısmında); 2) dikdörtgen ve düz kenarlı (üstte); 3) dikey yönde uzatılmış, düzensiz şekil (solda); 4) konturları olduğu gibi bir kulp (sağda) oluşturan durumları belirtir. Böylece çok boyutlu çözüm, denekler benzerliği değerlendirirken önlerinde sadece isimlerini görmelerine rağmen bu durumların görsel özelliklerini yansıtır.

durumlar arasındaki benzerlik derecesi ve konturlarının şekli Shpovpnyaya ve mantarlarda (Shepard ve Chîpman, 1970 ) ve diğerlerinde - konturları [arka uçları oklar). Her bir durumun konturu çizilirken, merkez, guiuii okunun yanıtının geri atı olarak alındı.
Şek. 12.1, deneklere durumların adları değil, konturları verildiğinde yaklaşık olarak aynı sonuçlar elde edildi. Bu veriler, deneklerin DP'sinin durumların şekli hakkında bilgi içerdiğini ve bu nedenle durumların adlarını aldıktan sonra, bu bilgileri şekil benzerliklerini değerlendirmek için kullanabileceklerini göstermektedir.
Shepard (Shepard, 1968; Shepard ve Chipman, 1970), bellekte yer alan görsel bilginin gerçek dünyadaki karşılık gelen bilgilere "ikinci dereceden izomorfizm" ile ilişkili olduğunu öne sürdü. İzomorfizm, temelde aynı olan iki nesnenin ilişkisini belirtmek için kullanılan matematiksel bir terimdir. İkinci dereceden izomorfizm - Shepard'ın anladığı anlamda - benzerliğe daha yakın bir şeyi ima eder. Shepard, bir koleksiyondaki öğeler arasındaki ilişkiler diğerindeki ilişkilerle eşleşiyorsa, iki öğe koleksiyonunun ikinci dereceden bir izomorfizm ilişkisi içinde olduğunu düşünür. Bu nedenle, gerçek dünyanın bazı öğeleri, bellekte aralarındaki ilişki gerçek dünyadaki ile aynıysa, bellekteki karşılık gelen öğelerle ikinci dereceden bir izomorfizm ilişkisi içinde olacaktır. Eyalet adlarında durum böyle görünüyor. Oklahoma ve Idaho arasındaki gerçek ilişki (her ikisinin de "kulpları" vardır) deneklerin Shepard ve Chipman'ın hafızasındaki ilişkilerine uygun bir şekilde yansıdı (en azından bu, elde edilen benzerlik tahminleriyle değerlendirilebildiği ölçüde). Shepard, bellekte yer alan görsel bilginin genellikle karşılık gelen gerçek verilerle ikinci dereceden bir eşbiçimlilik ilişkisi içinde olduğuna inanır. Başka bir deyişle, "zihinsel imgeler", zihinsel imgeler arasındaki ilişkinin gözün algıladığı resimler arasındakiyle aynı olması anlamında gerçek imgelerine benzer.
D11'deki figüratif kodlama fikri, Frost (Frost, 1972) tarafından yapılan araştırmalarla daha da desteklenmiştir. Frost, sıradan nesneleri tasvir eden 16 çizimden oluşan bir set derledi (bazıları Şekil 12.2'de gösterilmektedir). Bu çizimler, dört kategorideki veya sınıftaki nesneleri temsil ettikleri için anlamsal bir temelde sistematik hale getirilebilir: hayvanlar, giysiler, araçlar ve mobilyalar. Ancak bu figürler, dört konumdan birinde oldukları için görsel olarak da sınıflandırılabilir: uzun eksenleri dikey, yatay, sağa eğimli veya sola eğimli olabilir. Bu 16 çizim, biri tanıma yöntemiyle doğrulamayı beklemek zorunda kalan, diğeri ise sunulan nesnelerin adlarını serbest hatırlama yöntemiyle iki denek grubuna sunuldu. Daha sonra her iki grup da serbest hatırlama ile test edildi. Sonuçlar, serbest hatırlama testini bekleyen deneklerin öğeleri anlamsal temelde gruplandırdığını, yani SAME anlam sınıfına ait öğelerin birlikte geri çağrıldığını gösterdi. Buna karşılık, tanıma için test etmeyi bekleyen denekler, öğeleri hem anlamsal hem de görsel ipuçlarına dayalı olarak gruplandırdı. Bu sonuçlar, tanıma testini bekleyen deneklerin DP'lerinin bu öğelerin görsel temsillerini sakladığını; hatırlama sırasında hem bunları hem de anlamsal temsilleri kullandılar. Sınıflandırılabilir listelerin çoğaltılmasında olduğu gibi, deneklerin öğeleri çoğaltması, orijinal kümenin organizasyonunu yansıtıyordu. Bir tanıma testi bekleyen ve görsel özelliklere dayalı olarak çizimleri kodlayan denekler için organizasyon, bu özelliklere dayalı sınıflar oluşturacaktı. Buna karşılık, serbest hatırlama testini bekleyen denekler, materyali yalnızca semantik sınıflar halinde düzenlediler ve bu nedenle görsel ipuçlarına dayalı gruplandırmalar oluşturmadılar. Frost tarafından elde edilen diğer veriler de bu hipotezi desteklemektedir. Özellikle, bir tanıma testi bekleyen deneklerin çizimleri görsel olarak sunulduğunda daha iyi tanıyabildikleri ve bir hatırlama testi bekleyenlerin, tasvir edilen öğelerin adlarını daha iyi tanıyabildikleri ortaya çıktı.

Pirinç. J2.2. Frost tarafından kullanılan uyaranlar anlamsal özelliklere (dikey çubuklar) veya uzamsal yönelime (yatay sıralar) göre sınıflandırılabilir (Huni ve Love, 1972).
Önceki tüm tartışmalardan çıkan sonuç açıktır ki, bir kişi DP'de yüzleşmek zorunda olduğu her şeyin görsel belirtileri hakkında bilgi depolayabilir: gördüğü yüzlerin işaretleri, incelediği haritalar, tanık olduğu sahneler, ve t.i. Ek olarak, mevcut verilere bakılırsa, DP'de saklanan görsel bilgi, görülenin görüntüsüne bir dereceye kadar benzer. Bu tür "resimsel" kodlar, aynı algıların sözlü tanımlarıyla karşılaştırılmalıdır. Kısacası, "görsel imgeler" terimi, özellikle, görme yardımıyla elde edilen belirli bilgilerin hafızada temsili anlamına gelebilir.
ZİHİNSEL GÖRÜNTÜLER VE HAFIZA
Bununla birlikte, görsel imgelerle ilgili fikirlerin geliştirilmesi başka bir sorunla bağlantılıdır. Özü, bilgiyi sunmanın bir yolu olarak görüntülerin sözlü kodlara alternatif olarak hizmet edebilmesinde yatmaktadır. Örneğin, bir kişi KÖPEK-BİSİKLET eşli ilişkisini hatırlamak için bisiklete binen bir köpeği hayal edebilir. Böyle bir resim, aşağı yukarı "bisiklet süren bir köpek" sözleriyle aynı işlevi görür. Bu nedenle görüntü, kelimeler kullanılarak kolayca tanımlanabilecek bilgileri temsil etme aracı olarak hizmet edebilir. Figüratif temsiller, öğrenme ve hafıza ile ilgili görevlerde kullanıldığında D11'deki sözlü temsiller kadar veya hatta onlardan daha faydalı olabilir.
Az önce belirtilen bakış açısının ana destekçilerinden biri olan Paivio (1969, 1971) iki sistem veya iki kodlama biçimi teorisini geliştirdi; bu teori, şimdiye kadar bu kitapta takip ettiğimiz hafıza teorisinden oldukça farklıdır. İki sistem teorisine göre, bilgiyi bellekte temsil etmenin iki kodlama sistemi olarak adlandırılabilecek iki ana yolu vardır. Bunlardan biri, özellikle son iki bölümde ağırlıklı olarak ele aldığımız sözlü veya sözlü (dilsel) temsildir. İkinci yol sözlü değildir; resimsel olarak adlandırılabilir ve özellikle görsel görüntüleri içerir (yalnızca onları değil). Bu iki sistem şüphesiz yakından ilişkilidir, bu da sözel bir etiketten bir görüntünün çıkarılmasını veya tam tersini mümkün kılar. Ancak aralarında bazı ciddi farklılıklar vardır.
Birincisi, figüratif sistem, örneğin "köpek" veya "bisiklet" gibi tasvir edilebilecek belirli nesnelerle daha iyi başa çıkar. Ama "gerçek" gibi soyut bir kavram nasıl çizilebilir? Ve bu, bazı şeylerin kelimelerle kodlanmasının daha kolay olduğu, bazılarının ise hem sözlü hem de sözlü olmayan biçimde temsil edilebileceği anlamına gelir. İkinci kategori, örneğin "sepet" veya "ev" gibi somut kavramları içerirken, birinci kategori "adalet" veya "düşünme" gibi soyut kavramları içerir. İkincisi, bu iki sistem bilginin işlenme biçiminde farklılık gösterir. Sözel sistemde, sıralı işleme ana rolü oynuyor gibi görünüyor . Örneğin, sözlü konuşmanın oluşturulduğu sözcükleri algılarken, sesler birbiri ardına girdiye girer ve anlamları büyük ölçüde sıralarına bağlıdır. Bu, görünüşe göre "uzaysal olarak paralel" bir şekilde, yani uzayın belirli bir bölgesinde aynı anda işlenen görsel bilgilerin işlenmesiyle karşılaştırılabilir. Örneğin, A harfini gördüğümüzde onu / \ - öğelerine ayırmadan bir bütün olarak işleyebiliriz.
İki kodlama sistemi kavramının sonuçlarından biri, hem sözel hem de mecazi biçimde depolanabilen bilgilere yalnızca tek biçimde depolanan bilgilere göre daha erişilebilir olması gerektiğidir, çünkü ilk durumda ona hem sözlü hem de olmayan yollarla ulaşabiliriz. -sözel alma süreçleri. Belli bir anlamda, iki kez kodlanan bir öğe hakkındaki bilgi miktarı, yalnızca bir biçimde kodlanan bir öğe hakkındaki bilgi miktarının iki katıdır. Bu nedenle, somut şeylerin adları, soyut kavramları ifade eden kelimelerden daha kolay hatırlanmalıdır: ilki hem mecazi hem de sözlü biçimde, ikincisi ise yalnızca sözlü olarak sunulabilir. Göreceğimiz gibi, bu öngörü gerçekten doğrulanmıştır.
İki sistem teorisi açısından yorumlanabilecek psikolojik veriler çok fazladır. Burada kendimizi bu teoriyi destekleyen bazı tipik sonuçların değerlendirilmesiyle sınırlıyoruz. Bu, özellikle kelimelerin "mecazi temsilinin" ezberlenmeleri üzerindeki etkisine ilişkin verileri içerir; uyaranın doğasının (bir kelime veya bir resim) çeşitli deneysel prosedürlerin sonuçları üzerindeki etkisi hakkında; arabuluculukta zihinsel imgeler kullanmanın etkisi hakkında (bunu daha önce Bölüm 10'da tartışmıştık).
Az önce belirttiğimiz gibi, iki kodlama biçimi hipotezinin yararlı olabileceği sorulardan biri, kelimelerin "mecazi temsil edilebilirliği"nin etkisi sorusudur. Bir kelimenin bir özelliğinden, onun "anlamlılığından" daha önce bahsetmiştik (Noble, 1961). Belirli bir kelimenin anlamlılığının bir ölçüsü olarak, belirli bir süre için serbest çağrışım testlerinde sunulduğunda ortaya çıkan çağrışımların sayısı kullanılır. Bu nedenle, belirli bir kelimenin anlamlılığı, diğer kelimelerle iç içe geçme derecesini yansıtır. Şimdi, belirli bir kelimenin bir imgeyi ne kadar kolay uyandırabileceğinin ölçüsünü belirlemeye çalışalım. Paivio (Paivio, 1965), deneklerden sunulan kelimeye karşılık gelen bir görsele sahip oldukları anı bildirmelerini istedi; bu görüntü görsel (zihinsel resim) veya hatta işitsel olabilir. Bu kelimenin mecazi temsil edilebilirliğinin (RP) bir ölçüsünü türetmek için, deneklerin içlerinde görüntülerin göründüğünü bildirme hızı kullanıldı. OP ne kadar yüksekse, bu kelime bir görüntüyü o kadar kolay çağrıştırır. Genel olarak, OP'nin büyük ölçüde kelimenin somut anlamına bağlı olduğunu da not edebiliriz: belirli bir kelime belirli bir içerikle ne kadar ilişkilendirilirse, OP'si o kadar yüksek olur. Bu elbette oldukça doğaldır, çünkü belirli nesnelere gönderme yapan DOG gibi sözcüklerin bu nesnelerin görüntülerini çağrıştırması beklenir ve DÜŞÜN gibi bir sözcüğün karşılık gelen, hayal etmesi kolay bir nesne yoktur, bu nedenle kolayca bir görüntü oluşturamaz.
Anlaşıldığı üzere, kelimelerin mecazi temsilinin büyüklüğü, çeşitli görevleri yerine getirirken hafızanın verimliliğini oldukça doğru bir şekilde tahmin etmeyi mümkün kılıyor. Bu bakımdan aynı kelimenin anlamlılık derecesinden bile daha önemlidir. EP'nin performansla ilişkili olduğu bir durum tanıma testleridir. Listeler sunulduğunda ve ardından tanıma yöntemiyle test edildiğinde, somut isimler (yüksek OD) soyut isimlerden (düşük OD) daha iyi tanınır. Deneklere resimler sunulursa, tanıma etkinliği özel isimlerden bile daha yüksektir; Yukarıda resim tanıma deneylerinde belirtilen mükemmel sonuçları hatırlarsanız, bu beklenebilir (inceleme için bkz. Paio, 1971). Serbest hatırlama için de benzer veriler elde edilmiştir: soyut kelime listelerinin çoğaltılma etkinliği, belirli kelime listelerinden daha düşüktür. Ve listelere resimler eşlik ediyorsa (ve deneklerden bu resimlere eşlik eden yazıları hatırlamaları istenir), o zaman sonuçlar belirli kelimeleri ezberlemekten bile daha iyidir. Bu tür farklılıklar hem 5 dakikalık akılda tutma aralıklarında hem de bir hafta mertebesinde daha uzun aralıklarla ortaya çıkar. Ezberleme ve öğe dizilerini yeniden oluşturma sırasında resimler, belirli ihtişamlar ve soyut sözcükler için benzer bir verimlilik derecesi gözlemlenir (Herman a. o "1951; Paivio a. Csapo, 1969). Ayrıca, bu etkilerin, görünüşe göre, sadece mecazi temsil edilebilirlik üzerinedir ve listelerde kullanılan kelimelerin anlamlılığı ile ilgili değildir (bkz. örneğin, Paivio a. o "1969).
Bu verilerden çıkarılabilecek genel sonuç, figüratif temsil edilebilirlik (RP) ve somutluğun, sözlü bilgilerin bellekte tutulmasını etkilediğidir. Bu, iki kodlama biçimi teorisi lehine bir argüman olarak yorumlandı. Bunu yaparken aşağıdaki hususlar dikkate alınmıştır. Yüksek OD'ye sahip kelimeler, iki farklı uzun süreli bellek sisteminde temsil edilir - sözel kodlu bir sistemde ve bir tür mecazi, "resimsel" kodlu bir sistemde. Düşük OP'li kelimeler için sadece bir kod vardır - sözel. Bununla birlikte, resimler sunulursa, sözlü bir açıklama veya bir etiketle birlikte bellekte çok güçlü bir figüratif iz kalır. Tanıma veya hatırlama yoluyla bu öğelerin ezberlenmesini test etme zamanı geldiğinde, sonuçlar bellekte depolanan bilgi miktarına bağlıdır. İki kodla, sonuçlar tek koddan daha iyi olacaktır. Bir anlamda hafızadaki bir unsurun gücünün, onun sözel ve mecazi gücünün toplamı olduğunu düşünebiliriz.
ARACILIKTA GÖRÜNTÜLERİN ROLÜ
Arabuluculukta imgelerin rolüne ilişkin çalışmada da iki tür kodlama hipotezi lehine kanıtlar elde edilmiştir. Başlıca sonuçlar, Bower'ın daha önce tartışılan çalışmasında açıklanmıştır (Bower, 1972b). Bu yazar, eşli ilişkilendirme görevindeki deneklerden uygun zihinsel görüntüler oluşturmaları istendiğinde, hatırlama verimliliğinin önemli ölçüde arttığını buldu. Örneğin, bir KÖPEK-BİSİKLET kelimesi çifti sunulduğunda, denek bisiklete binen bir köpeği hayal edebilir. Zihinsel görüntülerden bahsetmeden olağan talimatları alan diğer denekler için, hatırlama verimliliği yaklaşık 1/3 daha düşüktü. Açıkçası, görüntüler iyi aracı faktörler olarak hizmet etti. Hatırlama sırasında, öznenin daha önce oluşturduğu bir resmi (bisikletli bir köpek) bellekten geri getirmek için KÖPEK uyaran bileşenini kullandığı varsayılır. Bu resimden bir bisiklet görüntüsünü çıkarıyor ve ardından "bisiklet" kelimesini yeniden üretiyor.
Bower, ikili çağrışımların arabuluculuğunda imgelemenin rolünü daha da ayrıntılı olarak araştırdı. Örneğin, birkaç reaksiyon bileşeninin bir uyarıcı bileşenle, bir reaksiyonun onunla ilişkilendirildiği şekilde tam olarak aynı şekilde ilişkilendirilebileceğini saptadı. Böylece, özneye ezberlemesi için beş kelime önerilebilir: KÖPEK, ŞAPKA, BİSİKLET, YER İPE YSKII, ÇİT, bunları uyarıcı kelime SIG ARA ile ilişkilendirerek. Bu durumda denek, hayal gücünde, ağzında puro olan, çitin yanında bisiklet süren bir köpeği (elbette şapkalı) durduran bir polisin resmini yaratabilir. Yalnızca CIGARA kelimesi sunulduğunda, bu resimden listelenen beş kelimeyi çıkarabilir mi? Deneyin sonuçlarının gösterdiği gibi, yapabilir. Bower, hatırlamanın, oluşturulan resimde uyarıcı bileşenle ilişkilendirilmesi gereken öğelerin sayısına bağlı olmadığını buldu. Denekler, 20 kelimelik bir listeyi, yanlış yazılan her kelime için bir tane olmak üzere yirmi yerine bir uyarıcı bileşenle ilişkilendirirse, hatırlama kötüleşmedi. Bu durumda, uyarıcı bileşene "askı" denir - olduğu gibi üzerine çeşitli reaksiyonlar asılabilir.
Bower ayrıca, imgelemenin yalnızca reaksiyon bileşenlerinin "askı kelimesi" ile bir tür karmaşık resimde birleştirildiği durumlarda hatırlamaya katkıda bulunduğunu da buldu. Denekten köpek-bisiklet çiftini hatırlaması için bir köpek ve ardından ayrı ayrı bir bisiklet hayal etmesini isterseniz, sonuçlar ondan köpek ve bisikletin bir şekilde etkileşime girdiği bir resim hayal etmesini istemenizden çok daha kötü olacaktır. . Bu anlaşılabilir bir durumdur, çünkü tek başına bisiklet imgesi, köpeğin imgesini bellekten geri getirmede çok az yardımcı olur. KÖPEK kelimesini "bisiklet" kelimesini elde etmek için kullanmak için, hafızamızda bir kelimenin sunumundan ortaya çıkabilecek, ancak her iki nesneyi de içeren bir resim olmalıdır; birini diğerini kullanarak çıkarabilmeniz için her iki öğeyi de birleştirmesi gerekir.
Görüntüler aracılığıyla arabuluculuk, yalnızca ikili çağrışımların oluşumunda yararlı olmayabilir. Örneğin, Delin (Delin, 1969) bunu sıralı ezberleme görevlerinde kullanmıştır. Deneklere, iyi bir ezberleme için, dizideki her bir bitişik öğe çiftini bir etkileşimde veya diğerinde hayal etmenin gerekli olduğunu açıkladı. Bunun için çok zaman ayırdı, kelimeleri yavaşça sundu (her biri 11 saniye). Örneğin KÖPEK, BİSİKLET, ŞAPKA sırasını içeren bir liste sunulduğunda, denek önce bisikletin üzerindeki bir köpeği, ardından ayrı bir resim olarak bisikletin gidonlarına asılı bir şapkayı vb. . Bu talimat, öğelerin sırasını hatırlamayı kolaylaştırdı ve olağan talimatları alan deneklerin sonuçlarına kıyasla sonuçları iyileştirdi.
GÖRSELLER VE DOĞAL DİL
Figüratif arabuluculuk fikri, doğal konuşma parçaları için hafıza çalışmasında da çok verimli oldu. Daha önce gördüğümüz gibi (bkz. 9. Bölüm), bu tür parçaları unutmak, genellikle ifade edildikleri sözcükleri unutmakla ifade edilir, ancak anlamı değil. Örneğin, Sachs (Sachs, 1967) tarafından yürütülen bir çalışmada, denekler bir cümleyi aktiften pasife çevirmeye, anlamını örneğin olumludan olumsuza değiştirmeye kıyasla çok daha az güçlü tepki verdiler. Begg ve Paivio (Begg a. Paivio, І969) daha da ileri gitti. Soyut ve somut nitelikte cümleler kullanarak Sacks ile aynı deneyleri yaptılar. Somut isimlerin içinde bulunduğu somut cümleye örnek olarak "Sevgi dolu anne çocuklarıyla ilgilendi" sözü, soyut cümleye ise "Mutlak iman sarsılmaz ilgi uyandırdı" cümlesi örnek gösterilebilir. Bu tür cümleler, özneye kısa metin pasajları da dahil olmak üzere sunuldu ve ardından tanınma için test edildi. Teste katılan her çeldirici unsur, orijinal cümlelerden birine benziyordu, ancak ondan ya sadece sözlü biçim ya da anlam olarak farklıydı. Örneğin, yukarıdaki belirli cümlenin ifadesini değiştirerek, "Çocukları seven bir anne baktı" ve anlamsal bir değişiklikle "Sevgi dolu çocuklar anneye baktı" ifadesini elde edebilirsiniz.
Begg ve Paivio'nun deneyinin sonuçları Şek. 12.3. Bu şekilden de görülebileceği gibi, Sacks tarafından alınan veriler, soyut önerilerle ilgili değil, belirli ile ilgili olarak onaylanmıştır. Somut cümlelerde denekler anlamsal değişiklikleri lafızdaki değişikliklerden daha kolay fark ederken, soyut cümlelerde bunun tersi gözlenmektedir. Bu sonuçlar, Paivio'nun görüntülerin bilgi depolamadaki rolü hakkındaki fikirleri temelinde açıklanabilir. Paivio, belirli bir cümlenin anlamının hafızada kelimelerden çok resimler şeklinde sunulduğuna inanıyor. Dolayısıyla kelimelerdeki anlamı etkilemeyen değişiklikler, hafızada yer alan görüntü ile çelişmeyecek ve fark edilmeyecektir. Cümle soyutsa, görüntü cümlenin anlamının hafızada etkili bir şekilde saklanmasını mümkün kılmaz; anlam burada kelime biçiminde saklanmalıdır ve bu nedenle ifadelerdeki değişiklikler fark edilecektir.
Çavdar. 12 3, Doğru olma olasılığı y e Fra in û gg;ee abstract ile semantik (semantik) ile sözcüksel (yalnızca ea «ena e.ioi} değişiklikleri (Beg £ a.
Paivio, 1469).
Bu son deneyin sonuçlarına ve yorumuna bakılırsa, mecazi temsil fikri, dilin anlaşılmasını açıklamak için bir hipotez olarak uygundur. Bu görüş, dil yoluyla iletilen bilgilerin anlaşılmasında ve hatırlanmasında görüntülerin çok önemli bir rol oynadığına inanan Paivio (Paivio, 1971) tarafından paylaşılmaktadır. Başka bir deyişle, sözlü mesajları, özellikle bu mesajlar somutsa, çağrıştırabilecekleri imgeler açısından anladığımıza inanıyor. Elbette dili (konuşmayı) ve anlamını anlamaya yönelik başka teoriler de var; Böyle o kadar çok teori var ki, hepsini bu kitapta ele almak imkansız. Bununla birlikte, burada, Bölüm 1'de tartışılan semantik hafıza teorilerinin işaret edilmesi gerekir. 8 dil ile iletilen bilgilerle ilgilidir; böylece, imgeler kullanılmadan dilin anlaşılmasını tanımlarlar.
DP'de "resimsel" türde temsillerin varlığı lehine oldukça ikna edici verilere sahip olduğumuz izlenimi edinilebilir. Bu nedenle, karşıt bakış açılarını dikkate almak artık çok uygun. Aslında, bilginin LTP'de mecazi bir biçimde depolanıp depolanmadığına dair tartışma psikolojide uzun süredir devam etmektedir (inceleme için bkz. Paivio, 1971). Ancak son yıllarda, bu sorunu modern bilişsel psikoloji ile ilişkilendiren yeni, daha ayrıntılı teorilerin ortaya çıkması nedeniyle bunlara olan ilgi yeniden canlandı.
GÖRÜNTÜ HİPOTEZİNE İTİRAZLAR
Sağduyu, uzun süreli belleğin görüntüleri sakladığı teorisinin geçerliliğini sorgulamamıza neden olabilir, özellikle de bu görüntülerin tam olarak gerçek dünyadaki nesneler gibi görünmesi gerekiyorsa. Pylyshyn (1973), bu teorinin karşı karşıya olduğu bir dizi ciddi zorluğa işaret etti. Ortaya çıkan ilk soru, bu zihinsel görüntülerin neye benzediğidir. Algıladığımız bilgileri gerçekten doğru bir şekilde yansıtıyorlarsa, o zaman bu tür pek çok görüntü olması gerektiği açıktır. Neredeyse sınırsız sayıda farklı sahneyi görsel olarak algılayabildiğimiz için, DP'nin tüm bu sahnelerin ayrıntılı kopyalarını depolamak için sınırsız alana sahip olması gerekir. Hafızada saklanan tüm bu görüntülerin nasıl kullanılabileceği de net değil. Bir şekilde hafızadan geri alınmaları gerekir ve bunun için içerdiklerini "görmek" için onları yeniden algılamak ve analiz etmek gerekir. Ancak bu görüntülerin yeniden algılanması gerekiyorsa, o zaman algı sürecinde zaten "işlenmiş" bir biçimde depolanabilirler ve yalnızca görülen sahnelerin tam kopyaları biçiminde değil. Başka bir soru, bir kelimenin belirli bir resme nasıl erişim sağlayabileceğidir: Sonuçta, aynı kelime çok sayıda resme atıfta bulunabilir - hangisinin hafızadan alınması gerektiğini nasıl anlarsınız? Pylyshin, tüm bu noktalar göz önüne alındığında, görüntülerin - ya da onlara ne diyorsak - ham duyusal veriler olarak değil, bir tür analizin ürünleri olarak bellekte saklanması gerektiğine inanıyor. Ancak bu durumda, duyusal kaydın dışında kalan dış dünyayı tam olarak kopyalayamazlar, daha çok algılananın bir açıklaması gibi olmalıdırlar. Bu, insanların "resimsel" nitelikte öznel temsillere sahip olmadığı anlamına gelmez; bu yalnızca, bu tür temsillerin mevcudiyetinin ilgili bilgilerin mecazi bir biçimde saklandığını göstermediği anlamına gelir: böyle bir sonuç hatalı olur.
Anderson ve Bower (Anderson ve Bower, 1973), Pylyshin'in bakış açısını destekler. Onların görüşüne göre, mecazi olarak kabul edebileceğimiz bu hafıza izleri, "tamamen sözlü" olarak kabul ettiğimizlerden farklı değildir. Oluşturdukları AFC modelinde, uzun süreli bellekte yer alan tüm bilgiler, birbiriyle bağlantılı kavramlardan oluşan soyut yapıların ifadeleri olarak temsil edilebilir. Böyle bir model, hem sözlü hem de mecazi kodların (benimsediğimiz terimlere uygun olarak) hafızadaki varlığını açıklamayı mümkün kılar. Sözcelerin (düğümler ve çağrışımlar) oluşturduğu şey oldukça soyuttur ve "sözlü" veya "mecazlı" gibi kavramların ötesine geçer. İfadelerin yardımıyla hem kelimeler hem de resimler hakkındaki bilgileri açıklayabilirsiniz.
Hafızadaki görüntülerin varlığına yönelik mantıksal itirazlara ek olarak, birleşik bir görüntü ve sözel süreçler teorisi lehine deneysel kanıtlar da vardır (yani, her iki sürecin de temelde benzer olduğu - bunların açıkça iki olmadığı gerçeği lehine) bilgi temsilinin sınırlandırılmış biçimleri). Bower'ın ikili ilişkilendirme öğrenimi ve imgeleme hakkındaki ilk verileri, iki biçimli kodlama hipoteziyle daha iyi uyum içinde olmasına rağmen, sonraki çalışmasının sonuçları tek bir mekanizmayı destekliyor.
Bir deneyde (Bower ve Winzenz, 1970), eşli çağrışım görevindeki deneklerden arabulucu olarak cümleleri kullanmaları istendiğinde, bunun görüntüleri kullanmak kadar etkili olduğu ortaya çıktı. Bu tür cümleler, çiftin unsurlarını birbirine bağlamalıdır (defalarca alıntılanan "bisiklet süren bir köpek" örneğinde olduğu gibi). Daha da şaşırtıcı olanı, deneklerden çağrışımları bazen cümlelerle, bazen de imgelerle pekiştirmeleri istendiğinde, bu yöntemlerden hangisini kullandıklarını iyi hatırlamamaları (Bower a. o., 1972). Görünüşe göre bir durumda görüntüler ve diğerinde cümleler oluşturulursa, denekler eşleştirilmiş kelimeleri bağlamak için hangi arabulucuyu kullandıklarını söyleyebilecekler. Aslında ikisi arasında net bir ayrım yapamıyorlar. Bu, "imgelerin" cümleleri kullanırken ortaya çıkanlardan farklı olmadığını düşündürür. Bower'a göre, özneden ister resim ister cümle kullanması istensin, her iki durumda da verilen kelimeler arasındaki anlamlı ilişkileri aramaya ve kodlamaya teşvik edilir. Bower, eşleştirilmiş çağrışımların ezberlenmesini kolaylaştıranın bir tür zihinsel imge değil, anlamsal bağlantıların oluşumu olduğuna inanıyor; bu nedenle bu iki arabuluculuk türü aynı etkiyi verir.
Wiseman ve Neisser (1971), figüratif ve sözel kodlamanın birliğine tanıklık eden diğer deneysel verileri sunmuştur. Deneklere, çeşitli sahnelerin görüntülerinden konturların bir kısmının çıkarılmasıyla elde edilebilecek bir dizi Mooney resmi gösterdiler. Bu tür resimlerde tam olarak neyin tasvir edildiğini anlamak oldukça zordur, ancak bazen bozulmaya rağmen olay örgüsünü anlamayı başarır. Resimlere bakarak denekler anlamlarını çözmeye çalıştı. Daha sonra, aynı türden diğer resimlerin çeldirici görevi gördüğü bir tanıma testi gerçekleştirildi. Aynı zamanda, Wiseman ve Neisser, tanımanın yalnızca deneklerin belirli bir resimle ilk kez sunulduklarında ona bir tür yorum yaptıkları ve tanınmayı kontrol ederken tekrar aynı şekilde yorumladıkları durumlarda başarılı olduğunu buldular. . Diğer durumlarda (resmin ilk sunumda veya doğrulama sırasında yorumlanamadığı durumlarda), tanıma etkinliği çok düşüktü. Bu sonuçlar, tanımanın, doğrulama sırasında sunulan resimlerin bellekte saklanan figüratif izlerle karşılaştırılmasına dayanmadığını göstermektedir. Doğru tanıma için, deneklerin kontrol ederken resmi ilk sunuldukları zamanki gibi yorumlamaları önemlidir. Sadece daha önce sunulanla aynı olan bir resmi görmek, doğru tanıma için yeterli değildir. 1. test sırasında denekler görünüşe göre tanınabilir resimleri DP'de saklanan yorumlanmamış sahnelerle karşılaştırmadı; görünüşe göre bu resimlerin içeriğine ilişkin önceki sonuçlarını mevcut yorumlarıyla karşılaştırdılar. Bu, deneklerin, uyaranın bir kopyası değil, belirli bir uyarana ilişkin analizlerinin sonuçları hakkında bilgi tuttukları gerçeğinden yanadır.
Nelson, Metzler ve Reid (Nelson a. o., 1974) tarafından elde edilen veriler, resimlerin ayrıntılı kopyalarının DP'de saklanması fikrine de karşı çıkıyor. Bu yazarlar, deneklerin geçmişte kendilerine sunulan resimleri tanıma konusundaki şaşırtıcı yeteneğini açıklamak için benzer bir fikrin sıklıkla ileri sürüldüğüne dikkat çekiyorlar (bkz. örneğin, Shepard, 1967); başka bir deyişle, figüratif belleğin sözel belleğe üstünlüğünün, bellekte depolanan resimlerle ilgili bilgilerin daha ayrıntılı olmasından kaynaklandığı varsayılmıştır. Ve bu durumda, herhangi bir detayın tanınması, resmin tamamının tanınmasına yol açmalıdır, bu da resimlere nispeten yetersiz sözlü bilgilere göre bir avantaj sağlar. Bu hipotezi test etmek için Nelson ve çalışma arkadaşları, aynı sahne hakkındaki bilgilerin dört farklı uyaran türüyle sunulduğu deneyler yaptılar (Şekil 12.4): tek bir cümle, ayrıntıları olmayan bir çizim, ayrıntılı bir çizim ve bir fotoğraf. Her deneğe bu dört uyarandan biri sunuldu ve ardından tanıma için test edildi. Üç figüratif uyarandan herhangi biriyle yapılan deneylerde tanıma etkinliğinin sözel bir uyarana göre daha yüksek olduğu ortaya çıktı. Üç mecazi uyaran için tanıma sonuçları aynıydı; başka bir deyişle, daha fazla ayrıntı tanımayı kolaylaştırmadı. Bu sonuçlar, resimler için belleğin üstünlüğünün, bunların ayrıntılı kopyalarının DP'de depolanmasından kaynaklanmadığı anlamına gelir. Dahası, hayali uyaranların genellikle DP'de belirli resimler biçiminde depolanıp depolanmadığına dair bir şüphe vardır. Ayrıntılı olmayan ve ayrıntılı resimleri tanımanın eşit kolaylığı, yorumların deneklerin hafızasında saklandığı ve değil
uyaranların "görüntüleri". Bu durumda, görünüşe göre, bu yorumlar oldukça soyuttu ve bu nedenle, farklı derecelerde ayrıntıya sahip resimler için açıklamalar olarak eşit derecede uygundu.

Rle. 12.4. Prnyer ClIPltH. NOLSH PLOLGTALІіТіі ONE frichor (4), riopk, ns içeren detaylar (B), detaylı çizim (i) ve fotoğraf ( D) (Nelsorı a. &,) E74),
Görüntülerin konuşmayı anlamanın temeli olduğu fikri de itirazları artırdı. Özellikle, Begg ve Paivio'nun (Begg ve Paivio, 1969) belirli cümlelerin bellekte imgelerle ve soyut cümlelerin kelimelerle temsil edilebileceği hipotezi eleştirilmiştir. Öncelikle Begg ve Paivio'nun sonuçlarının yeniden üretilmesinin zor olduğu ortaya çıkmış (örneğin bkz. görünürlük (Johnson a. o. , 1972). Franks ve Bransford (1972) kendi paylarına mecazi kodlama hipotezini sorguladılar. Daha önceki sözel soyutlama çalışmalarına benzer bir deney yaptılar (bkz. Bölüm 9) (Bransford ve Franks, 1971). Okuyucunun hatırlayacağı gibi, daha önceki bu çalışmada deneklere dört basit tümcenin çeşitli kombinasyonlarından oluşturulan cümle grupları sunuldu. Sonraki testlerde, cümlelerin tanınması, bu cümlelerin gerçekten sunulup sunulmadığına değil, dört orijinal ifadede yer alan fikirler arasından kaç tane fikri birleştirdiklerine bağlıydı. Bundan, Franks ve Bransford, öznenin, orijinal ifade grubunu algılayarak, bunların içerdiği bilgileri entegre ettiği ve depolama için bazı genelleştirilmiş versiyonlar ortaya koyduğu sonucuna vardı; buna dayanarak, yargısını tanımaya dayandırdı ve bu nedenle, bir cümle ne kadar orijinal basit fikirler içeriyorsa (ve dolayısıyla bütünleşik bir forma ne kadar çok benziyorsa), o kadar kolay eski olarak "kabul edildi".
Bransford ve Franks (Bransford ve Franks, 1971) ilk çalışmalarında somut cümleler kullandılar. Begg ve Paivio'nun fikirlerine dayanarak, soyut cümlelerle sonuçların farklı olması beklenebilir; çünkü bu yazarlar, soyut cümlelerin sözel biçimde saklandığına ve buna bağlı olarak, ifadelerdeki değişikliklerin anlam değişikliklerine göre onlarda daha kolay tespit edildiğine inanırlar. Bu da, Franks ve Bransford deneyinde, soyut cümleler durumunda tanıma etkinliğinin daha yüksek olacağı anlamına gelmelidir. Ancak soyut cümlelerle yapılan bu deneye rağmen (Franks ve Bransford, 1972) somut cümlelerle aynı sonuçları vermiştir. Bundan, her ikisinin de bellekte benzer şekilde işlendiği sonucu çıkar. Genel olarak, tüm bu veriler, görüntülerin cümleleri ezberlemedeki rolü hakkındaki hipoteze karşı tanıklık eder.
"GÖRÜNTÜLER" VAR MI?
ÇELİŞKİNİ ÇÖZMEK İÇİN OLASI BİR YOL
Yukarıdaki mantıksal argümanların ve deneysel verilerin gösterdiği gibi, mecazi kodlama hipotezi savunulamaz ise, o zaman geriye ne kalır? İmgelemenin ezberleme verimliliği üzerindeki etkisi nasıl açıklanabilir? Ve neden sık sık zihnimizde canlı imgeler varmış gibi hissederiz? Konulara ezberlenmiş öğelerin görüntülerini ve yüksek OD değerlerini (“sözcüklerin mecazi temsil edilebilirliği”) oluşturmalarını öneren talimatların neden ezberlemeyi kolaylaştırabileceği sorusunun cevaplarından biri Anderson ve Bower tarafından önerildi (Anderson ve Bower, 1973). Onlara göre, görüntülerin oluşturulmasına elverişli koşullarda, DP'de kodlanan ve depolanan bilgiler kavramsal olarak daha zengin ve ayrıntılıdır. Bu durumda, mecazi ve mecazi olmayan depolama biçimleri arasındaki fark, resimler ve kelimeler arasındaki fark gibi bir tür niteliksel farkla değil, kodlamanın ayrıntılarıyla ilgilidir. Anlamsal olarak daha zengin "mecazlı" kodların çıkarılması daha kolaydır, bu da onların kelimeleri ezberleme üzerindeki olumlu etkisini açıklar.
Zihinsel resimlerle ilgili öznel izlenimlerimizi açıklamak için kısa süreli bellekteki "çalışma alanı" kavramına geri dönelim. Ch'de. 7, CP'de görsel kodların varlığına ilişkin veriler dikkate alınmıştır. Bu kodlar, bazı görsel uyaranların sunumundan sonra ortaya çıkabilir veya LTP'de depolanan bilgilere dayalı olarak oluşturulabilir. DP görsel bir görüntü değil, görülen sahnenin biraz daha soyut tanımını saklıyorsa, bu, CP'de resim benzeri bir kod oluşturmak için yine de yeterli olabilir (Pylyshyn, 1973 benzer düşünceleri dile getirdi). İçimizde ortaya çıkan zihinsel resimlerin öznel fikrinin altında yatan bu yeniden yaratılmış "imaj" dır. Bununla birlikte, bu tür bir görüntü DP'de yer alan bilgilerden oluşturulduğundan, bu bilgilerden daha ayrıntılı olamayacağına dikkat edilmelidir. Bu nedenle, görsel olarak algılanan sahnenin en iyi ihtimalle soyut bir kopyasıdır. Shepard'ın terminolojisini kullanırsak, onun bu sahneyle ikinci dereceden bir izomorfizm ilişkisi içinde olduğunu söyleyebiliriz. Bununla birlikte, Shepard'ın zihinsel dönüş deneyleri (7. Bölümde ele alınmıştır) bazı durumlarda görüntülerin karşılık geldikleri dış nesnelere çok benzediğini göstermektedir.
Yukarıda söylenenlerden, görüntülerin varlığına hem lehte hem de aleyhte güçlü argümanların olduğu açıktır. Bu şaşırtıcı gelmemeli: Daha önce de belirtildiği gibi, zihinsel imgeler sorunu psikolojideki en eski tartışmalı sorunlardan biridir ve bunun oldukça uzun bir süre tartışmalı kalacağı düşünülebilir. Ancak tüm çelişkilere rağmen görsel hafıza ile ilgili bazı temel hükümler formüle etmek mümkündür. İlk olarak, dış dünyanın uzun süreli bellekte tüm ayrıntılarıyla nesnelere karşılık gelen resimler biçiminde temsil edildiği varsayılamaz; Görünüşe göre böyle bir olasılık, hem mantıksal değerlendirmelerden hem de deneysel verilerden hareketle dışlanmalıdır. İkinci olarak, DP'nin görsel olarak algılanan sahneler hakkında bilgi içerdiği kabul edilmelidir, çünkü bu tür bilgiler örüntü tanıma ve daha önce görülen şeylerin hatırlanması için gereklidir. Bununla birlikte, DP'de yer alan bilgilerin veya bu bilgilerden yeniden oluşturulan görüntülerin ne ölçüde "zihinsel" resimlere benzediği belirsizliğini koruyor. Bu konuda, anlaşmazlıklar elbette devam edebilir.
Bölüm 13
Mnemonast, satranç oyunu ve hafıza
Bu kitabın önceki on iki bölümünde uzun bir yol kat ettik. İnsan hafızası ile ilgili olarak pek çok farklı konuya değindik: dış dünyadan gelen girdi mesajlarının tanınması, kısa süreli hafıza sorunları ve uzun süreli hafızanın en karmaşık yönleri. Bu sonuç bölümünde birbiriyle ilişkili iki konuyu tartışacağız. Bunlardan biri anımsatıcı, diğeri ise hafıza ile özel beceri ve yetenekler arasındaki ilişkidir. İkinci konu, psikologlar tarafından detaylı olarak incelenen bir örnekte, yani satranç oyuncularının sahip olduğu belirli yeteneklerde ele alınacaktır. Bu konuların her biri kendi içinde ilginçtir, ancak burada yalnızca bu kitapta tartışılan malzemenin çoğunu bir araya getirmemize yardımcı olabilecek yönlerine değineceğiz, çünkü anımsatıcıları ve satrancı tartışırken role değinmemiz gerekecek. algı ve kısa ve uzun süreli hafıza ile ilgili süreçlerin
MNEMONİKLER VE MNEMONİSTLER
Bölümde daha önce belirtildiği gibi. 5, "anımsatıcılar", hafızaya yardımcı olmak için özel olarak öğrenilmiş tekniklerin ve stratejilerin kullanılması anlamına gelir. Önceki bölümlerde, çeşitli anımsatıcı aygıtları defalarca ele aldık. Örnek olarak iki tanesini aktaralım: Eşli çağrışımlara aracılık etmek için görsel bir imgenin veya bazı tümcelerin kullanılması, anlamsız heceleri kodlamak için aracı sözcüklerin kullanılması. n sayısını "daireler hakkında bildiklerim" ile kodlamak veya "Her avcı sülünlerin nerede oturduğunu bilmek ister" ifadesiyle spektrumdaki renklerin sırasını hatırlamak gibi diğer bazı anımsatıcı hileler neredeyse herkesin aşina olduğu bir şeydir. Herhangi bir öğenin tüm listesini ezberlemeyi kolaylaştıran birkaç örnek vardır. Bunlardan biri, uzun bir dizi nesneyi zihinsel olarak birbiri ardına, sırası özel olarak ezberlenmiş farklı yerlere yerleştirerek hatırlamanın eski bir yolu olan "yer yöntemi"dir. Bir listeyi ezberlemenin başka bir yolu da, içindeki öğelerin adlarını işleyerek bir hikaye oluşturmaktır.
Listeleri ezberlemenin başka bir yolu da askı sözcük sistemi veya bağlantı sözcükler olarak adlandırılır. Bu sistem, sayısı kolayca artırılabilen 10 adede kadar öğe içeren listeleri hatırlamanıza olanak tanır. Her şeyden önce, anımsatıcı on kelimeyi kesin olarak ezberlemelidir, örneğin: "topuz, ayakkabı, ağaç, kapı, arı kovanı, çubuk, gökyüzü, kapı, çizgi, tavuk 1" Bundan sonra, yöntemdeki ile yaklaşık olarak aynı şey yapılır. yer. Diyelim ki size şu listeyi ezberlemeniz teklif edildi: EKMEK, JAPON, HARDAL, PEYNİR, UN, SÜT, DOMATES, MUZ, TEREYAĞI, SOĞAN. Bu listeyi hatırlamak için, her elemanın referans listesindeki karşılık gelen elemanla etkileşime girdiğini hayal edin. Bir somun ekmekten büyüyen bir çörek, bir ayakkabıda birkaç kırık yumurta, üzerinde hardal kavanozları sarkan bir ağaç ve benzeri hayal edin. Öğe listesini daha sonra yeniden oluşturmak için, anahtar kelimeleri hatırlamak yeterlidir ve bunların her biri, karşılık gelen öğeyi bellekte canlandıracaktır.
1 Orijinalde bu, her kelimenin seri numarasını hatırlamayı kolaylaştıran bir kafiye listesidir: "Bir topuzdur; iki ayakkabıdır; üç ağaçtır; dört kapıdır; beş kovandır; altı sopa, yedi cennet, sekiz kapı, dokuz çizgi, on tavuktur.
Pek çok anımsatıcı aygıtın öğrenilmesi kolaydır, diğerleri ise oldukça zordur; sadece özellikle nitelikli anımsatıcılar tarafından kullanılabilenler bile var, şu ya da bu nedenle bu işle özel olarak uğraşan kişiler. Bower (1973), bu tür yüksek sınıf anımsatıcılardan oluşan bir grupla tanışma izlenimlerini aktarır. Her birinin çeşitli anımsatıcı hileler ve numaralarda arkadaşlarını geride bırakmaya çalıştığı bir anımsatıcı kongresine katıldı. Bower'ın yazdığı gibi, anımsatıcılar oldukça yetenekli olduklarını kanıtladılar. Bunlardan biri, halk tarafından kendisine sunulan dört kelimeyi dinledikten sonra, bir kelimeyi oluşturan harfleri, diğerinin harflerini - ters sırayla, üçüncüsünün harflerini - baş aşağı ve sırasına göre hızlıca baş aşağı yazabiliyordu. aynı zamanda ters sırada ve dördüncü - ters sırada normal sırayla. Ancak hepsi bu kadar değildi: böyle bir kayıt yaparak, her bir kelimedeki harf sırasını bozmadan, bir kelimedeki harfleri diğerlerinden gelen harflerle eşit şekilde değiştirdi. Ancak aynı zamanda "The Shooting of Dan McGrew" şarkısını da okuduğu için bu ona yetmedi. Başka bir anımsatıcı, karıştırılmış bir deste karta bakıp onları tam olarak sırayla sıralayabilir.
Bu harika anımsatıcıların becerilerine tanık olmak zor değil. Sanatlarına hayran olmak da zor değil. Ancak tüm bunları nasıl başardıklarını tespit etmek çok zor. Bower, kelimeleri karıştıran anımsatıcıya bunu nasıl başardığını sordu. Çok uzun bir uygulama sonucunda ellerinin sadece ihtiyaç duydukları her şeyi yaptığını ve kendisine çağrılan kelimeleri düşünmesinin yeterli olduğunu söyledi. Cevabının konunun özünü hiç yansıtmamasına şaşmamalı. Ama piyanoda bir parçayı nasıl çaldığımızı, üç kere iki kaçtır sorusunun cevabını nasıl bulduğumuzu, bisiklet sürerken nasıl denge kurduğumuzu kelimelerle anlatmamız istense yine aynı çıkmazda kalırdık. . . Bu tür becerilerle ilgili olarak, kendini gözlemleme oldukça zordur.
Ancak anımsatıcıların faaliyetlerini daha titiz yöntemlerle incelemek mümkündür. Böylece, son derece yetenekli iki anımsatıcının becerilerini ayrıntılı olarak incelemek mümkün oldu: biri Luria (1968), diğeri ise Hunt and Love (Hunt and Love, 1972) tarafından incelendi. Bu iki insan, çocukluklarında birbirlerinden sadece 55 km uzakta yaşadıkları noktaya kadar birçok yönden benzerdi. Aynı zamanda, anımsatıcı becerileri biraz farklıydı; örneğin, Luria tarafından incelenen anımsatıcı, kendi sözleriyle, Hunt and Love tarafından incelenenden çok daha fazla görüntü kullandı.
Onun hakkında birçok deneysel veri toplandığı için ikincisi hakkında ayrıntılı olarak konuşacağız (ona V.P. diyeceğiz). V.P.'nin hayatında sıra dışı hiçbir şey yoktur. 1935 yılında Letonya'da doğdu ve ailenin tek çocuğuydu. Üç buçuk yaşında okumayı öğrendi ve bu onun erken zihinsel gelişimine tanıklık etti. Çocukluğunda olağanüstü hafızası da kendini gösterdi: Beş yaşında yarım milyon nüfuslu bir şehrin planını ezberledi ve on yaşında bazılarının programında yer alan 150 şiir ezberledi. bir tür rekabet. Ayrıca sekiz yaşında satranç oynamaya başladı. Bütün bunlar, V.P.'nin yüksek zihinsel yetenekleri hakkında bir sonuca varmayı mümkün kıldı ve IQ'suna ilişkin son tahminler bu sonucu doğruladı. Bellekle ilgili testlerde en yüksek puanı aldı. Özellikle kısa süreli belleğin önemli rol oynadığı bir testte V.P. %95 puan aldı. Ayrıntıları hızlı bir şekilde kavrama yeteneği olan hızlı anlama testinde de çok yüksek puan aldı. Hunt and Love'ın işaret ettiği gibi, genel olarak puanları yüksek bir zihinsel gelişime işaret ediyor, ancak istisnai bir hafızayı tahmin etmek için gerekçe sağlamıyor.
Bu arada, V.P.'nin bu konuda olağanüstü yeteneklere sahip olduğuna şüphe yok. Hunt and Love bunu, birçoğu okuyucunun zaten aşina olduğu bir dizi deney yaparak kanıtladı (mümkünse, bu deneysel yöntemin açıklandığı bölüm belirtilecektir). Kısa süreli bellekle ilgili görevleri yerine getirirken önce V.P.'nin sonuçlarını ele alalım. Bu türden en temel sorunlardan biri, bellek miktarını, yani CP'nin barındırabileceği yapısal birimlerin sayısını belirleme sorunudur (bkz. Bölüm 5). Bildiğiniz gibi, bellek miktarı genellikle 5-9 öğe aralığındadır. İlk başta, V.P.'ye hızlı bir şekilde bir dizi figür sunulduğunda, hafızasının bir tür istisnai kapasite ile ayırt edildiğine dair hiçbir izlenim yoktu. Ancak kısa sürede hafıza miktarını artırmanın bir yolunu buldu. 1 s aralıklarla rakamlarla sunulduğunda, bunları 35 basamaklı gruplar halinde birleştirdi ve daha sonra bu tür her grupla bir tür sözlü kod ilişkilendirdi (1492, kodlama için açıkça uygun olan bir basamak grubuna örnek olarak hizmet edebilir) . Bunu yaparak hafızasını kolayca 17 haneye çıkardı. Bu kodlama yönteminden bahseden kontrol denekleri de hafıza kapasitelerini bir şekilde artırmayı başardılar, ancak çok fazla değil.
Peterson ve Peterson probleminde elde edilen CP'den unutmaya ilişkin veriler de ilgi çekicidir (bkz. Bölüm 6). Bu görevde üçlü geriye doğru sayarken üç ünsüz harfi hafızanızda tutmanız gerekiyor. Tipik olarak denekler, 18 saniyelik bir aralıkta izin hızlı bir şekilde solmasını yaşar; ancak, bu dönemde V.P. çok az unutma gösterdi veya hiç unutmadı. Bu sadece ilk denemede (proaktif inhibisyon minimum olduğunda ve üreme etkinliği maksimuma ulaştığında) değil, diğer tüm denemelerde de böyleydi. V.P.'nin kendisi bu tür sonuçlar için olası bir açıklama önerdi.Birkaç dil bilgisinin, herhangi bir kelimeyi ezberlemesi için kendisine sunulan neredeyse tüm üçlü ünsüzlerle ilişkilendirmesine izin verdiğini ve bu şekilde üç harfi tek bir yapısal harfe dönüştürdüğünü söyledi. birim. Bu durumda, unutmanın olmadığı, Peterson problemi yerine getirildiğinde yapısal birimlerin sayısının etkisi hakkında bilinenlerden tahmin edilebilir: bu tür üç birim durumunda, unutma bir duruma göre çok daha belirgindir. birim. Ek olarak, birden çok dilin kullanılması, unutmayı azaltmış olması gereken (Wickens'ın çalışmasında olduğu gibi, bkz. Bölüm 7) proaktif engellemenin kaldırılmasına yol açabilir. Bunun nedeni, her dilin sanki yeni bir ezberlenmiş öğeler sınıfını temsil etmesi ve yeni bir sınıfa geçişin genellikle proaktif engellemenin kaldırılmasına yol açmasıdır.
Hunt and Love ayrıca V.P.'nin Sternberg problemini kullanarak belleği tarama yeteneğini de araştırdı (Bölüm 7). Bu görevde deneğin, verilen uyaranın testten kısa bir süre önce kendisine sunulan öğeler grubuna dahil olup olmadığını belirtmesi gerektiğini hatırlayın. Bu deneyler, genellikle ilk setteki eleman sayısıyla doğrusal olarak artan reaksiyon süresini ölçer. Bununla birlikte, yapılan deneylerde böyle bir artış görülmedi . Ezberlediği altı element setini, bir elementi yaptığı kadar hızlı bir şekilde "inceledi" ve bunu yapması da aşağı yukarı aynı süreyi aldı; diğer konuların bir öğeye ne kadar harcadığı. Bu, deneklerin çoğundan farklı olarak, V.P.'nin SP'de istenen unsuru, içerdiği tüm unsurların paralel bir incelemesi yoluyla aradığını varsaymamıza izin verir.
Tüm bu sonuçlar, V.P.'nin bellek boyutunun normalden önemli ölçüde farklı olmadığını göstermektedir. Bununla birlikte, CP'si diğer açılardan tamamen sıra dışıdır. CP'de saklanan bilgilerin paralel olarak taranmasını sağlayabilir; CP'deki öğeleri, başkalarının unuttuğu koşullar altında da elinde tutabilir; diğer konulardan daha fazla yapılandırma kapasitesine sahiptir. Görünüşe göre, V.P.'nin bu bellek özellikleri, en azından kısmen, girdi bilgilerine inanılmaz bir hızda aracılık etme ve yeniden kodlama yeteneğinden kaynaklanıyor. Ve bu, hızlı bir şekilde yapılandırma üretmesine izin verir, bu da bellek miktarını artırma ve CP'deki girişimin etkisine boyun eğmeme yeteneğinin temelini oluşturur. Arabuluculuk ve organizasyonun bilgilerin uzun süreli depolanması üzerindeki benzer etkisi göz önüne alındığında, V.P.'nin uzun süreli ezberleme konusunda aynı istisnai yeteneklere sahip olması beklenebilir. Yani aslında olduğu ortaya çıktı.
Hunt and Love, birkaç görev aracılığıyla V.P.'nin uzun süreli hafızasını inceledi. Bunlardan biri, Bartlet'in deneylerinde kullanılan ve deneklerin çoğunun yeniden üretildiğinde çarpıttığı "Ruhların Savaşı" efsanesinin yeniden anlatımıydı (bölüm 9). V.P. bu efsaneyi dinledi ve ardından 253'ten başlayarak sıfıra kadar yedişer saydı. Daha sonra 1 dakikadan 6 haftaya kadar değişen aralıklarla kendisine gösterilen efsanenin belirli bölümlerini yeniden üretti. Her durumda, efsaneyi şaşırtıcı derecede iyi hatırlıyordu. Kelimesi kelimesine yeniden üretemese de metne çok yakın bir şekilde yeniden anlattı. Aynı zamanda, haftalar sonra, onu dinledikten bir saat sonra olduğu gibi hatırladı.
Hafıza testi deneylerinde V.P.'nin bu kadar mükemmel sonuçlarını açıklayan nedir? Her şeyden önce, görünüşe göre görsel imgelere başvurmadığı ortaya çıktı. Tabii ki, V.P. mecazilik derecesine kayıtsız değildir, çünkü yüksek "figüratif temsil edilebilirliğe" sahip unsurları düşük olandan daha iyi hatırlar (Bölüm 12). Kendi itirafına göre, bazen mecazi anımsatıcı araçlara başvurur, ancak çoğunlukla sözlü araçlar kullanır. V.P.'nin görsel görüntüleri nadiren kullandığı gerçeği, resimleri gruplandırmak için Frost görevini gerçekleştirmesinin sonuçlarıyla gösterilir (Bölüm 12). Başkan Yardımcısı ve kontrol deneklerine önce Frost'un uyaran olarak kullandığı resimler sunuldu (hem içerik hem de uzamsal yönelime göre gruplandırılabilir) ve ardından, bir süre sonra onlara beklenmedik bir serbest hatırlama testi verildi. Aynı zamanda, kontrol denekleri, resimleri yönelimlerine göre gruplandırma konusunda güçlü bir eğilim gösterirken, V.P. onları yalnızca içeriğe göre gruplandırdı. Uyaranların hafızasında görsel imgeler şeklinde saklanmadığı görülüyordu. Başka bir durumda, V.P.'den her biri 6 sayıdan oluşan 8 satırdan oluşan iki matrisi ezberlemesi istendi. Bir matriste sayılar çift sıralar halinde dizilmişti, diğerinde ise satırlar düzensizdi ve sayılar arasındaki mesafeler aynı değildi. Bu matrislerin kısa bir incelemesinden sonra V.P., hem birini hem de diğerini kusursuz bir şekilde ve dahası aynı hızda yeniden üretebildi. "Gevşek" matrisi okumak daha fazla zaman aldığından, bu sonuçlar V.P.'nin bu matrisi bellekte depolanan bazı görsel görüntülerden "okumadığını" göstermektedir. Aslında, V.P.'nin kendisi sözlü anımsatıcı cihazlar kullandığını açıkladı, örneğin, hafızasına bir dizi sayı koydu, bunu bir tür tarih olarak hayal etti ve o gün ne yaptığını hatırladı.
Böylece, V.P.'nin olağanüstü bir sözel hafızaya sahip bir anımsatıcı olduğu izlenimi edinilir. İlgisiz uyaranlarla sunulduğunda, hızlı bir şekilde anımsatıcı şemalar oluşturabilir ve bunları materyali yapılandırmak ve düzenlemek için kullanabilir. Bu, CP ve DI ile yapılan deneylerde inanılmaz derecede yüksek oranlara yol açtı. Ayrıntıları hızlı bir şekilde kavrama konusundaki mükemmel yeteneği de ona büyük ölçüde yardımcı oluyor, bu sayede bir tür anımsatıcı cihaz kullanmanın temelini hemen buluyor. V.P.'nin olağanüstü yeteneklerinin başka bir faktörle - hafıza eğitimine erken bir başlangıçla - ilişkili olması mümkündür. Hem VP hem de Luria tarafından incelenen anımsatıcı, aynı eğitim sistemine sahip (hatta okulları aynı coğrafi bölgedeydi) okulların öğrencileriydi ve burada ezberci öğrenme önemli bir rol oynadı. Bu gibi durumlarda öğrenci ezberleme yeteneğini geliştirmek zorundadır. Bu, elbette oldukça spekülatif olmasına rağmen, çocuklukta edinilen bu becerilerin V.P.'yi bu alanda geliştirmeye sevk eden bir itici güç olarak hizmet edebileceği sonucuna götürür.
HAFIZA VE SATRANÇ SEN
V.I.'nin mükemmel bir satranç oyuncusu olduğunu not etmek ilginçtir. Kamuoyuna konuştu, yedi kurulda eşzamanlı oturumlar verdi ve dahası, tahtaya bakmadan körü körüne. Ayrıca birçok oyunu yazışma yoluyla yürütür ve aynı zamanda oyunun gelişimini takip etmek için hamleleri yazmak zorunda değildir. Bu tür hafıza gösterileri güçlü bir izlenim bırakıyor ve V.I.'nin bir anımsatıcı olarak olağanüstü yetenekleri hakkında bildiğimiz her şeyle oldukça tutarlı. Bununla birlikte, satranç alanında bu tür yeteneklerin tezahürünün oldukça yaygın olduğu ortaya çıktı: çoğu satranç ustası ve büyükusta, kendilerine tahta yalnızca 5 saniye gösterilirse, konumu neredeyse doğru bir şekilde yeniden üretebilir (deGroot, 1965, 1966). Ancak bunu ancak satranç tahtasındaki taşların dizilişinin gerçek oyunun bir anını yansıttığı durumlarda yapabilirler; taşlar gelişigüzel dizilirse, o zaman usta, önemsiz bir satranç oyuncusundan daha iyi görmediği resmi eski haline getirebilecektir. Bu, satranç ustalarının tahtada bir konumu yeniden oluşturma yeteneğinin görünüşe göre CP'lerinin herhangi bir özel yeteneğiyle değil, oyunun kendisine ilişkin bilgileriyle bağlantılı olduğunu gösterir.
Ustaların "doğal" satranç pozisyonlarını yeniden üretme yeteneği, Simon ve işbirlikçilerinin bir dizi çalışmasının konusudur (Simon a. Barenfeld, 1969; Chase a. Simon, 1973; Simon a. Gilmartin, 1973). Bu çalışmaların sonuçlarından biri, bir satranç oyuncusunun hafızasının bilgisayarda simülasyonuydu. Bu yazarlar tarafından derlenen bilgisayar programı, algılama süreçleri ile kısa ve uzun süreli belleğin işlevlerinin birbiriyle birleştiğinde nasıl etkili bir ezberleme için temel oluşturduğunu gösterdiği için özellikle ilgi çekicidir.
Simon ve Barenfeld (Simon a. Barenfeld, 1969), bir satranç tahtasında konumları yeniden oluşturmanın algısal yönlerini inceleyerek işe başladılar. Özellikle, satranç oyuncularının kendilerine yeni bir taş grubu sunulduktan sonraki ilk birkaç saniye içinde bu tahtayı nasıl gördükleriyle ilgilendiler. Bu tür gruplandırmaları ezberlemelerine ilişkin veriler, iyi satranç oyuncularının bu ilk birkaç saniye içinde şaşırtıcı miktarda bilgi almayı başardıklarını gösteriyor. Ayrıca satranç oyuncularının göz hareketleri kaydedilerek, dikkatlerinin en önemli stratejik konumu işgal eden taşlara odaklandığı görülmüştür.
Simon ve Barenfeld, bir bilgisayar programı olarak uyguladıkları bir satranç tahtası algı modeli önerdiler. Programları, bir satranç oyuncusunun öncelikle dikkatini tahtadaki önemli taşlardan birine odakladığı varsayımına dayanmaktadır. Ancak, aynı anda çevresel görüşle dikkati bir figüre odaklayarak, komşu figürler hakkında bilgi toplar. Özellikle, hangilerinin ana figürle önemli bir ilişki içinde olduğunu not eder - onu tehdit ederler, korurlar veya onun tehdidi veya koruması altındadırlar. Daha sonra satranç oyuncusu bakışını ana taşla ilişkili bu taşlardan birine kaydırır, dikkatini onun üzerinde yoğunlaştırır, ardından üçüncüye geçer ve böyle devam eder, böylece oyuncunun görsel dikkati önemli bir taştan hareket ederek tahtanın etrafında hareket eder. figürler arasındaki anlamlı ilişkiler tarafından yönlendirilir. Bu varsayımlara dayanarak, simülasyon programı, insanların satranç oynarken yaptıkları göz hareketlerinin yaklaşık olarak aynısını elde etmeyi mümkün kıldı.
Bir satranç pozisyonunun etkili görsel kodlaması, yeniden üretilmesinin yalnızca bir yönüdür. Taşların dizilişini algılayan bir satranç oyuncusu bunu nasıl hafızasında tutar? Ne de olsa, 5 saniye boyunca bakarak tüm pozisyonu yeniden üretebiliyor. Bu kadar kısa bir tutma aralığı nedeniyle, bunun kısa süreli belleğin kapasitesini kullandığı düşünülebilir. Ancak CP'nin kapasitesi sınırlı olduğundan, gerekli tüm bilgiler sadece birkaç yapısal birim şeklinde saklanmalıdır. Bu nedenle, bir pozisyonun yeniden üretilmesi için, ilgili bilgilerin algılandıktan sonra yapılandırılması ve CP'ye gömülmesi gerekir.
CP'nin satranç pozisyonlarını yeniden üretmedeki rolü Simon, Chase ve Gilmartin tarafından incelenmiştir. Satranç ustalarının bu tür yeniden üretim yeteneklerinin, tahtadan algılanan bilgileri yapılandırma yetenekleriyle açıklandığı hipotezinden yola çıktılar. Bu hipoteze göre, birinci sınıf bir satranç oyuncusu tahtaya baktığında bazı taş kombinasyonlarının tanıdık olduğunu fark eder. Bu gruplara belirli etiketler veya kodlar atayabilir, bu da onların ayrı yapısal birimler olarak algılanmalarını sağlar (tıpkı üç BM harfinin birleşiminin tek bir yapısal birime dönüşmesi gibi). Çeşitli taş gruplarını bu tür birimlerde birleştirerek, satranç oyuncusu bunları CP'nin sahip olduğu hacme yerleştirebilir. Bu sayede tahtadaki taşların konumu ile ilgili bilgileri hafızasında tutma ve bu bilgileri konumu yeniden oluşturmak için kullanma fırsatı elde eder. Daha zayıf satranç oyuncuları, şüphesiz taş gruplarını çok daha az tanıyabilir ve bunları yapısal birimler olarak kodlayabilir, bu da konumları yeniden oluşturma yeteneklerinin daha düşük olacağı anlamına gelir. Ayrıca, hem ustaların hem de zayıf oyuncuların rastgele düzenlemeleri kodlama konusunda eşit derecede yetersiz olduklarına işaret edilmelidir, çünkü ikincisi anlamlı olarak kabul edilemez.
Chase ve Simon, ustalardan yeni başlayanlara kadar her seviyeden oyuncuya iki problem vererek bu hipotezi test etti (Şekil 13.1). Bunlardan birinde hafıza test edildi: denek, yalnızca 5 saniye boyunca gördüğü bir pozisyonu yeniden oluşturmak zorunda kaldı. Başka bir görev algı ile ilgiliydi: özne, önündeki konumu yeniden oluşturmalıdır. Video kaydedici, öznenin bakışının uyarıcı panosundan oynatma panosuna geçişini ve tersini kaydetmeyi mümkün kıldı.

Pirinç. 13.1. Yeniden yüzeye çıkan bir satranç 4іr ?іc4ni ile üsleri kurma şeması (Chase ve Srman. 1973). Belleği incelerken, ekran 5 derece kaldırılır ve ardından yerine konur, ardından denek, Stile tahtasında sunulan fngur'un konumunu yeniden oluşturmaya çalışır. Algı çalışmasında genişlik tamamen kaldırılır, ardından deney sunulan konumu olabildiğince çabuk ayırmaya çalışır.
Algısal görevde, Chase ve Simon, tahtaya yerleştirilen herhangi bir figür grubunun, uyarıcı tahtaya iki bakış arasında bir "yapısal birim" olarak yeniden üretildiğini düşündüler. Ezberleme görevinde, bir "yapısal birim", aralarında çok kısa (2 s'den fazla olmayan) aralıklarla düzenlenmiş bir dizi şekil olarak kabul edildi "İki rakamın ayarlanması arasında iki saniyeden fazla zaman geçtiyse, bunlar farklı olarak atfedildi. yapısal birimler Böyle bir tanım, öznenin bir yapısal birime dahil olan tüm figürleri hızlı bir şekilde düzenlediğini, ardından duraksadığını, bu sırada bir sonraki birimin kodunu çözmeye çalıştığını, içinde yer alan figürleri, duraklamaları vb. Benzer bir akıl yürütme Johnson tarafından geçici bir hata olasılığı göz önünde bulundurulurken kullanıldı (bkz. Bölüm 5).] Bu tanımların geçerliliği: "yapısal birim", burada şekiller arasındaki durum bir yapısal birime atfedilmelidir, her iki problemde de benzer olduğu ortaya çıktı, sonuç olarak her iki durumda da yapısal birimler yaklaşık olarak aynı değere sahipti. kuyu; algılama görevinde böyle bir birim (ortalama olarak) 2.3 rakam ve ezberleme görevinde 2.2 rakam içeriyordu.
Yapısal birimleri bu şekilde belirledikten sonra, Chase ve Simon usta, birinci sınıf satranç oyuncusu ve başlangıç seviyesindekiler için yapısal birimlerin ortalama sayısını ve birim başına taş sayısını hesapladılar. Hafıza görevinde bir yapısal birimin değerinin satranç oyuncusunun becerisine bağlı olduğunu buldular: Bir birimi oluşturan taşların sayısı, oyuncunun seviyesi düştükçe azalır. Bu, deneyimli oyuncuların bir yapısal birime daha fazla taş sığdırdıkları için bir satranç pozisyonunu daha iyi yeniden üretebildikleri hipoteziyle tutarlıdır. Algılama görevi, farklı beceri seviyelerindeki oyuncular arasındaki başka bir farkı ortaya çıkardı. Buradaki yapısal birimin değeri, ezberleme görevindekiyle yaklaşık olarak aynı olmasına rağmen, artık satranç oyuncunun becerisine bağlı değildi: Tahtaya bir bakışta kapsanan ortalama taş sayısı, her iki taraf için de yaklaşık olarak aynıydı. acemi ve usta. Ancak, oyuncunun sınıfı ne kadar yüksekse, tahtaya bakmak için o kadar az zamana ihtiyacı vardı. Bu, algısal görevde çok daha az zaman harcayan ustanın yeni başlayan kadar bilgi topladığını gösterir. Böylece ustaların tahtadaki konumu hızlı bir şekilde algılayıp kodlayabildikleri ve ayrıca algıladıklarını daha etkin bir şekilde yapılandırdıkları kanaatindeyiz.
Son olarak, Chase ve Simon birinci sınıf satranç oyuncuları tarafından yaratılan yapısal birimlerin doğasını keşfettiler. Hafıza görevindeki bireysel yapısal birimlere karşılık gelen konfigürasyonların sayısı nispeten azdı ve bunlar, bir satranç oyununda belirli bir anlamı olan taşlar arasındaki ilişkileri yansıtıyordu. Ustalar tarafından yaratılan tüm yapısal birimlerin %75'inden fazlası yalnızca üç durum sınıfına aitti ve hepsi satranç pozisyonları için çok tipikti. Ve bu, yapısal birimler oluştururken, bir satranç ustasının DP'de saklanan nispeten az sayıda gruplama kullandığı anlamına gelir. Bu nedenle, bu sonuçlar, birinci sınıf satranç oyuncularının, satranç tahtası üzerindeki konumları hızlı bir şekilde yeniden kodlamak için DI1'de bulunan gruplamaları kullandıkları ve bunun da bu konumları kısa bir süre için ezberlemelerini kolaylaştırdığı hipotezini doğrulamaktadır.
Simon ve Gilmartin (1973), orijinal algısal programı bir öğrenme sistemiyle birleştiren bir simülasyon programı geliştirerek satrançtaki bu araştırmayı sürdürdü. Bu daha karmaşık programın, tahtadaki taşların düzenini, hafızasında kayıtlı yaklaşık 1000 gruplama ile birinci sınıf bir satranç oyuncusundan daha iyi yeniden üretebileceğini gösterdiler. Tahminlerine göre, hafızada yaklaşık 50.000 ve muhtemelen daha az grup saklarsanız, makine, ana makineden daha kötü olmayan konumları yeniden üretebilecektir. Uzun yıllar satranç oynayan bir ustanın hafızasında böylesi bir gruplama stokunun birikebilmesi oldukça makul görünüyor (Simon ve Barenfeld, 1969).
L L L
Belleğin önemli bir rol oynadığı iki duruma ilişkin bu oldukça ayrıntılı tartışmada, kitapta tartışılan bir dizi konuyu yeniden ele aldık. Önde gelen anımsatıcıların ve satranç ustalarının belirli yeteneklerinin altında yatan olguları ele alırken, girdi mesajlarının alınmasından son analizlerine ve saklanmalarına kadar hafızanın işleyişinin tüm aşamalarına değinmemiz gerekiyordu. Bilginin kodlanması, depolanması ve geri alınmasıyla ilgili önceki on iki bölümde sunulan bilgilerin, bu son bölümün ayrıldığı iki özel yeteneğin analizinde yararlı olduğu kanıtlanmıştır. Bilişsel psikolojinin temsilcileri, bu bilginin insan hafızasının daha genel yönlerini ve zihinsel aktivitedeki rolünü anlamak için de yararlı olacağını umuyor.
>Referanslar
Adams 1. A., 1967. İnsan Hafızası, New York, McGraw-Hill.
Alien M., 1968. Serbest hatırlamada organizasyonun belirleyicileri olarak prova stratejileri ve yanıt ipuçları, J. of Verbal Learning and Verbal Behavior, 7,58-63.
Anderson JR, Bonier G. H, 1972. Serbest hatırlamada tanıma ve geri alma süreçleri.
Psikolojik İnceleme, 79, 97-123.
Anderson JR, Bonier G. H, 1973. İnsan İlişkisel Hafızası, Washington, DC, VH Winston and Sons.
Anderson JR, Bonier GH, 1974. Önermesel bir tanıma belleği teorisi, Memory and Cognition, 2, 406-412.
Atkinson RC, Juola JF, 1973. Kelime tanımanın hızını ve doğruluğunu etkileyen faktörler.
İçinde: S. Kornblum (ed.). Dikkat ve Performans IV, New York, Academic Press.
Atkinson RC, Shiffrin RM, 1968. İnsan hafızası: Önerilen bir Sistem ve kontrol süreçleri. İçinde: KW Sponce ve JT Spence (editörler), The Psychology of Learning and Motivation: Advances in Research and Theory (Cilt 2), New York, Academic Press.
Averbach E., Conell AS, 1961. Görmede kısa süreli hafıza, Bell System Technical J., 40, 309-328.
Averbach E., Sperling G., 1961. Bilginin vizyonda kısa süreli depolanması.
In: C. Cherry (ed.), Bilgi Teorisi Üzerine Dördüncü Londra Sempozyumu, Londra ve Washington, DC, Butterworth.
Baddeley AD, 1972. Kısa süreli bellekte geri getirme kuralları ve anlamsal kodlama, Psikolojik Bülten, 78, 379-385.
Baddeley AD, Dale HCA, 1966. Anlamsal benzerliğin uzun ve kısa süreli bellekte geriye dönük girişim üzerindeki etkisi, J. of Verbal Learning and Verbal Behavior, 5, 417-420.
Barclay JR, 1973. Cümleleri hatırlamada anlamanın rolü, Bilişsel Psikoloji, 4, 229-254.
Barnes JM, Underwood B. L, 1959. transfer teorisinde birinci sıradaki çağrışımlar, J. of Experimental Psychology, 58, 97-105.
Bartlett F.C., 1932. Hatırlama: Deneysel ve Sosyal Psikolojide Bir Araştırma, Cambridge, Cambridge University Press.
Battig WF, Montague WE, 1969. 56 kategorideki sözlü öğeler için kategori normları: Connecticut kategori normlarının bir kopyası ve uzantısı, J. of Experimental Psychology Monograph, 80 (3, Pt. 2).
Begg J., Paivio A., 1969. Cümle anlamında somutluk ve imge, J. of Verbal Learning and Verbal Behavior, 8, 821-827.
Bobrovs SA, Bower 0. H., 1969. Cümlelerin anlaşılması ve hatırlanması, J. of Experimental Psychology, 80, 455-461.
Bousfield AK. Bousfield WA, 1966. Tekrarlanan serbest hatırlamada kümelenme ve sıralı sabitliklerin ölçümü, Psychological Reports, 19, 935-942.
Bousfield W. A, 1951. Dil davranışında sıklık ve kullanılabilirlik ölçütleri, yıllık toplantıda sunulan bildiri, American Psychological Association, Chicago.
Bousfield WA, 1953. Rastgele düzenlenmiş ortakların hatırlanmasında kümelenme oluşumu, J. of General Psychology, 49, 229-240.
Bousfield WA, Cohen B. H., 1953. Rastgele düzenlenmiş ortakların anımsanmasında kümelenme oluşumunda pekiştirmenin etkileri, J. of Psychology, 36, 67-81.
Bousfeld WA, Cohen B. H., Whitmarsh GA, 1958. Farklı taksonomik oluşum sıklıklarına sahip kelimelerin hatırlanmasında çağrışımsal kümeleme, Psikolojik Raporlar, 4, 39-44.
Bousfeld W. A, Puff CR, 1964. Tepki baskınlığının bir fonksiyonu olarak kümeleme, J. of Experimental Psychology, 67, 76-79.
Bower GH, 1970. Hafızadaki organizasyonel faktörler, Bilişsel Psikoloji, 1,18-46.
Bower GH, 1972a. Hafızadaki organizasyonel faktörlerin seçici bir incelemesi.
İçinde: E. Tulving ve W. Donaldson (editörler). Hafıza Organizasyonu, New York, Academic Press.
Cower 0.H., 1972b. Zihinsel görüntüleme ve ilişkisel öğrenme. İçinde: L. Gregg (ed.), Cognition in Learning and Memory, New York, Wiley, Bower GH, 1973. Tanıdığım hafıza ucubeleri, Psychology Today, 7, 64-65.
Bower GH, dark M. C" Lesgold AM, Winzenz D., 1969. Kategorize kelime listelerinin hatırlanmasında hiyerarşik alma şemaları, J. of Verbal Learning and Verbal Behavior, 8, 323-343.
Bower GH, MunorR., Arnold PG, 1972. Ayırt edici semantik ve imgesel anımsatıcılar üzerine. yayınlanmamış el yazması.
Bower GH, Springston F., 1970. İkinci dizide kayıt noktaları olarak duraklamalar, J. of Experimental Psychology, 83, 421-430.
Bower GH, Winzenz D., 1970. İlişkisel öğrenme stratejilerinin karşılaştırılması, Psychonomic Science, 20, 119-120.
Bransford SD, Barclay}. R., Franks f. }., 1972. Cümle belleği: Yapıcıya karşı yorumlayıcı bir yaklaşım, Bilişsel Psikoloji, 3, 193.209.
Bransford SD, Franks. L, 1971. Dilsel fikirlerin soyutlanması, Bilişsel Psikoloji, 2,331-350.
Briggs GE, 1954. Geriye dönük engellemede edinim, yok olma ve iyileşme işlevleri, J. of Experimental Psychology, 47, 285-293.
Briggs GE, 1957. Orijinal ve enterpolasyonlu öğrenme derecesinin bir fonksiyonu olarak geriye dönük engelleme, J. of Experimental Psychology, 53, 60-67.
Broadbent DE, 1958. Algı ve İletişim, Londra, Pergamon Press.
Kahverengi. 1. A., 1958. Anlık belleğin çürüme teorisinin bazı testleri, Quarterly J. of Experimental Psychology, 10, 12-21.
Brown RW, McNeill D., 1966. The fenomen, J. of Verbal Learning and Verbal Behavior, 5, 325-337.
Bruce D., Fagan RL, 1970. Organize listelerin tanınması ve ücretsiz olarak hatırlanması hakkında daha fazla bilgi, J. of Experimental Psychology, 85, 153-154.
Ceraso J., Henderson A., 1965. R1 ve PI'de bulunmama ve ilişkisel kayıp, J. of Experimental Psychology, 70, 300-303.
Chase WG, Simon HA, 1973. Satrançta algı, Bilişsel Psikoloji, 4, 55-81.
Cherry EC, 1953. Bir ve iki kulakla konuşmanın tanınması üzerine bazı deneyler, J. of the Acoustical Society of America, 25, 975979.
Clifton C., Jr., Tash 1., 1973. Heceli sözcük uzunluğunun bellek arama hızı üzerindeki etkisi, J. of Experimental Psychology, 99, 231-235.
Cofer CN, 1965. Serbest hatırlamanın örgütsel özelliklerindeki bazı faktörler üzerine, American Psychoologist, 20, 261-272.
Cofer CN, Bruce DR, Reicher GM, 1966. Belirli metodolojik varyasyonların bir işlevi olarak serbest hatırlamada kümeleme, J. of Experimental Psy. Koloji, 71, 858-866.
Cohen BH, 1966. Kodlama davranışının bazı ya da hiç özellikleri, J. Verbal Learning and Verbal Behavior, 5, 182-187.
Collins AM, Quillian MR. 1969. Anlamsal bellekten geri alma süresi, J. of Verbal Learning and Verbal Behavior, 8, 240-247.
Collins AM, Quillian MR, 1970. Kategori boyutu kategorizasyon süresini etkiler mi? J. of Verbal Learning and Verbal Behavior, 9, 432-438.
Conrad R., 1963. Akustik karışıklıklar ve kelimeler için hafıza aralığı, Nature, 197,1029-1030.
Conrad R., 1964. Anlık bellekte akustik karışıklıklar, British J. of Psychology, 55,75-84.
Cooper LA, Shepard RN, 1973. Zihinsel görüntülerin dönüşünün kronometrik çalışmaları. İçinde: WG Chase (ed.). Görsel Bilgi İşleme.
New York, Akademik Basın.
Craik F. 1. M., Lockhart RS, 1972. İşleme düzeyleri: Bellek araştırması için bir çerçeve, J. of Verbal Learning and Verbal Behavior, II, 671684.
Craik F. 1. M., Watkins M.], 1973. Kısa süreli bellekte provanın rolü, J. of Verbal Learning and Verbal Behavior, 12, 599-607.
Crossman ERFW, 1958. Ulusal Fizik Laboratuvarı Sempozyumunda Makale 7'nin Tartışılması. İçinde: Düşünce Süreçlerinin Mekanizasyonu (Cilt 2).
Londra, HM Kırtasiye Ofisi.
Grouse JH, 1971. Düzyazı materyallerini okumada geriye dönük müdahale, J. of Educational Psychology, 62, 39-44.
Crowder RG, Morion J., 1969. Kategori öncesi akustik depolama (PAS), Perception and Psychophysics, 5, 365-373.
D'Agostino PR, 1969. Hatırlama ve tanımada engellenmiş rastgele etki, J. of Verbal Learning and Verbal Behavior, 8, 815-820.
Darwin CT, Turvey MT, Crowder R. 0., 1972. Sperling kısmi rapor prosedürünün işitsel bir "bilgisi": Kısa işitsel depolama için kanıt, Bilişsel Psikoloji, 3, 255-267.
Davis R., Sutherland NS, ludd BR, 1961. Tanıma ve hatırlamada bilgi içeriği, J. of Experimental Psychology, 61, 422-429.
de Groot AD, 1965. Satrançta Düşünce ve Seçim, The Hague, Mouton.
de Groot AD, 1966. Düşünmeye karşı algı ve hafıza. İçinde: B. Kleinmuntz (ed.). Problem Çözme, New York, Wiley.
Delin PS, 1969. Anımsatıcı yönergeler içeren ve içermeyen bir seri listenin ölçütünün öğrenilmesi, Psychonomic Science, 16, 169-170.
Deutsch D., 1970. Tonlar ve sayılar: Anlık bellekte girişimin özgüllüğü. Bilim, 168,1604-1605.
Deutsch JA, Deutsch D., 1963. Dikkat: Bazı teorik düşünceler, Psychological Review, 70, 80-90.
Donders F.C., 1862. Die Schnelligkeit psychischer Processe, Arch. Anat.PhysioL, 657-681.
Ebbinghaus H., 1885. Ober das Gedachtnis, Leipzig, Duncker ve Humblot.
Franks JJ, Branşford 1. D., 1971. Görsel kalıpların soyutlanması, J. of Experimental Psychology, 90, 65-74.
Franks JJ, Bransford JD, 1972. Soyut fikirlerin kazanılması, J. of Verbal Learning and Verbal Behavior, II, 311-315.
Freud S., 1940. [A note on the ] (J. Strachey, çev.), International J. of Psycho-Analysis, 21, 469.
Friedman MJ, Reynolds 1. H., 1967. Tepki sınıfı benzerliğinin bir işlevi olarak geriye dönük engelleme, J. of Experimental Psychology, 74, 351355.
Frost N., 1972. Görsel bellek görevlerinde kodlama ve geri alma, J. of Experimental Psychology, 95,317-326.
Cardiner JM, Craik F. 1. M., Birtwistle L. 1972. Geri alma ipuçları ve proaktif engellemeden salıverme, J. of Verbal Learning and Verbal Behavior, 11, 778-783.
Gray JA, Wedderburn AA /., 1960. Eşzamanlı uyaranlarla gruplama stratejileri. Quarterly J. of Experimental Psychology, 12, 180-184.
Green DM, Svsets JA, 1966. Signal Detection Theory and Psychophysics, New York, Wiley. Guttman N., iulesz B., 1963. İşitsel periyodiklik analizinin alt sınırları, J. of the Acoustical Society of America, 35, 610.
Haber R.N., 1969. Giriş. İçinde: RN Haber (ed.), Görsel Algıya Bilgi İşleme Yaklaşımları, New York, Holt.
Halle M., Stevens KN, 1959. Sentez yoluyla analiz. İçinde: W. Wathen-Dunn ve LE Woods (editörler). Konuşmayı Anlama ve İşleme Semineri Tutanakları, Bedford, Mass., Air Force Cambridge Research Laboratories.
Halle M., Stevens KN, 1964. Konuşma tanıma: Araştırma için bir model ve program. içinde: J.
A. Fodor ve JJ Katz (editörler), The Structure of Language: Readings in the Psychology of Language, Englewood Cliffs, New Jersey, Prentice-Hall.
Hebb D. 0., 1949. Davranış Organizasyonu, New York, Wiley.
Hebb D. 0.. 1958. A Textbook of Psychology, Philadelphia, WB Saunders.
Herman T., Broussard 1. G., Todd ff R., 1951. Denemeler arası aralık ve sıralı resimli uyaranları öğrenme hızı, J. of General Psychology, 45, 245-254.
Houston 1. P., 1966. Birinci liste tutma ve hatırlama zamanı ve yöntemi, J. of Experimental Psychology, 71, 839-843.
Hubel DH, Wiesel TN, 1962. Kedilerin görsel korteksinde alıcı alanlar, binoküler etkileşim ve işlevsel mimari, J. of Physiology, 160, 106-154.
Hunt E., Love T., 1972. Hafıza ne kadar iyi olabilir? İçinde: AW Melton ve E. Martin (editörler). İnsan Belleğinde Kodlama İşlemleri, Washington, DC, VH Winston and Sons.
Jakobson R., Fant GGM, Halle M., 1961. Preliminaries to Speech Analysis: The Distinctive Features and Their Correlates, Cambridge, M. 1. T. Press.
James W., 1890. Psikolojinin İlkeleri (Cilt 1), New York, Henry Holt and Co.
Jenkins 1. J., Mink WD, Russell WA, 1958. Sözel çağrışım gücünün bir işlevi olarak çağrışımsal kümeleme, Psikolojik Raporlar, 4, 127-136.
Jenkins JJ, Russell WA, 1952. Hatırlama sırasında ilişkisel kümeleme, J. of Abnormal and Social Psychology, 47, 818-821.
Johnson MK, Bransford 1. D., Nyberb SE, Cleary JJ, 1972. Soyut ve somut cümleler için hafızayı yorumlamada anlama faktörleri, J. of Verbal Learning and Verbal Behavior, II, 451-454.
Johnson NF, 1968. Sıralı sözlü davranış. İçinde: TR Dixon ve DL Horton (editörler). Sözel Davranış ve Genel Davranış Teorisi, Englewood Cliffs, New Jersey, Prentice-Hall.
Rahneman D., 1973. Dikkat ve Çaba, Englewood Cliffs, New Jersey, Prentice-Hall.
Katz JJ, Fodor JA, 1963. Semantik teorinin yapısı, Language, 39,170-210. Keppel G., Underwood BJ, 1962. Tek öğelerin kısa süreli akılda tutulmasında proaktif engelleme, J. of Verbal Learning and Verbal Behavior, I,. 153-1.61.
Kinney O.C., Marsetta M., Şovmen D. L, 1966. Ekran Simgelerinin Okunabilirliği Üzerine Çalışmalar, Bölüm XII. The Legibility of Alphanumeric Symbols for Digitalized Television, Bedford, Mass., The Mitre Corp., Kasım, ESD-TR-66-117.
Kintsch W., 1967. Tanıma öğreniminin bellek ve karar yönleri, Psychological Review, 74,496-504.
Kintsch W., 1968. Organize listelerin tanınması ve serbest olarak hatırlanması, J. of Experimental Psychology, 78,481-487.
Kintsch W., 1970. Serbest hatırlama ve tanıma için modeller. İçinde: DA Norman (ed.). İnsan Hafızası Modelleri, New York, Academic Press.
Klatzky RL, Atkinson RC, 1971. Kısa süreli bellekte Bilgi taramada serebral hemisferlerin uzmanlaşması. Algı ve Psikofizik, 10,335-338.
Koppenall RJ, 1963. A–B, A–C listelerinin güçlü yönlerindeki zaman değişiklikleri; kendiliğinden iyileşme? J. of Verbal Behavior, 2, 310-319.
Lachman R., Tuttle AV, 1965. İngilizceye Yaklaşım ve kısa süreli hafıza: İnşaat mı yoksa depolama mı? J. of Experimental Psychology, 70, 386-393.
Landauer TK, 1962. Örtük konuşma oranı, Algısal ve Motor Beceriler, 15, 646.
Landauer TK, Freedman JL, 1968. Uzun süreli bellekten bilgi alma: Kategori boyutu ve tanıma süresi, J. of Verbal Learning and Verbal Behavior, 7, 291-295.
Landauer TK, Meyer DE, 1972. Kategori boyutu ve semantik-hafıza alımı, J. of Verbal Learning and Verbal Behavior, II, 539-549.
Lettvin JY, Matiurana İK. McCulloch WS, Pitts WH, 1959. Kurbağa gözü kurbağanın beynini anlatır, Proceedings of the IRE, 47, İ9401951.
Lewis MQ, 1972. İşaretli hatırlamada işaret etkinliği. Psychonomic Society'nin yıllık toplantısında sunulan bildiri, St. Louis.
Lindsay PH, Norman D. A, 1972. İnsan Bilgi İşleme, NewYork, Academic Press
Luria, A.R., 1968. The Mind of a Mnemonist, New York, Basic Books.
Mandier 0., 1972. Organizasyon ve tanıma. İçinde: E. Tulving ve W. Donaldson (editörler), Hafıza Organizasyonu, New York, Academic Press.
Mandler 0., Pearlstone Z., 1966. Özgür ve kısıtlı kavram öğrenimi ve müteakip hatırlama, J. of Verbal Learning and Verbal Behavior, 5, 126131.
Mandler 0., Pearlstone Z., Koopmans HS, 1969. Organizasyon ve semantik benzerliğin hatırlama ve tanıma üzerindeki etkileri, J. of Verbal Learning and Verbal Behavior, 8, 410-423.
Massaro DW, 1972. İşitsel algıda algı öncesi görüntüler, işlem süresi ve algısal birimler, Psychological Review, 79, 124-145.
Mayhem A. i., 1967. Serbest hatırlama öğrenimi sırasında öznel organizasyondaki değişiklikleri listeler arası, J. of Experimental Psychology, 74, 425-430.
McDougall R., 1904. Tanıma ve hatırlama, J. of Philosophical and Scientific Methods, 1,229-233.
McOeoch JA, 1942. The Psychology of Human Learning, New York, Longmans Green and Co, Melton AW, Irwin JM, 1940. The effect of degree of enterpolated) learning on retroactive ketleme ve açık transfer belirli tepkiler, American J. of Psikoloji, 53, 173-203.
Meyer DE, 1970. Depolanan anlamsal Bilginin temsili ve geri alınması üzerine, Cognitive Psychology, 1, 242-300.
Miller 0. A., 1956. Sihirli yedi sayısı, artı veya eksi iki: Bilgi işleme kapasitemizin bazı sınırları, Psychological Review, 63,81-97.
Miller OA, 1962. Bazı psikolojik gramer çalışmaları, American Psychoologist, 17,748-762.
Miller 0. A., 1972. İngilizce hareket fiilleri: Anlambilim ve sözcüksel bellekte bir vaka çalışması. İçinde: AW Melton ve E. Martin (editörler). İnsan Belleğinde Kodlama İşlemleri, Washington, DC, VH Winston and Sons.
Miller 0. A., Heise GA, Lichten W., 1951. Test materyallerinin bağlamının bir işlevi olarak konuşmanın anlaşılırlığı, J. of Experimental Psychology, 41,329-335.
Miller 0. A., Selfridge JA, 1950. Sözel bağlam ve anlamlı materyalin hatırlanması, American J. of Psychology, 63, 176-187.
Milner B., 1959. İki taraflı hipokampal lezyonlarda hafıza bozukluğu, Psikiyatrik Araştırma Raporları, II, 43-58.
Montague WE, Adams JA, Kiess H. 0., 1966. Unutma ve doğal dil aracılığı, J. of Experimental Psychology, 72, 829-833.
Moray N., 1959. Dikotik dinlemede dikkat: Duygusal ipuçları ve talimatların etkisi. Quarterly J. of Experimental Psychology, II, 56-60.
Moray N., Bates A, Bamett T., 1965. Dört kulaklı adam üzerinde deneyler, J. Amerika Akustik Derneği, 38, 196-201.
Morion i., 1970. Hafıza için duygusal model. İçinde: D.A. Norman (ed.), Models of Human Memory, New York, Academic Press.
Morion J., Crowder RG, Prussin H. A, 1971. Uyaran eki etkisi ile deneyler, J. of Experimental Psychology Monograph, 91, 169-190.
Murdoch B. B., Jr., 1961. Bireysel öğelerin tutulması, J. of Experimental Psychology, 62,618-625.
Murdoch B. B., Jr., 1962. Serbest hatırlamanın seri konum etkisi, J. of Experimental Psychology, 64,482-488.
Murdoch BB, Jr., Walker K. D., 1969. Serbest hatırlamada modalite etkileri, J. of Verbal Learning and Verbal Behavior, 8, 665-676.
Neisser U., 1964. Görsel arama, Scientific American, 210, 94-102.
Neisser U., 1967. Bilişsel Psikoloji, New York, Appleton-Century-Crofts.
Neisser U., Novick R., Lazar R., 1963. Eşzamanlı olarak on hedef aramak, Perceptual and Motor Skills, 17, 955-961.
Nelson T. 0., Metzler }., Reed DA, 1974. Resimlerin ve sözlü açıklamaların uzun süreli tanınmasında ayrıntıların rolü, J. of Experimental Psychology, 102,184-186.
Nickerson RS, 1972. İkili sınıflandırma reaksiyon süresi: İnsanın bilgi işleme yeteneklerine ilişkin bazı çalışmaların gözden geçirilmesi, Psychonomic Monograph Supplements, 4, 275-318.
Noble CE, 1961. İngiliz alfabesinin 2100 CVC kombinasyonu için ilişkilendirme değeri (a), derecelendirilmiş ilişkilendirmeler (a) ve ölçeklendirilmiş anlamlılık (m) ölçümleri, Psychological Reports, 8, 487-521.
Norman DA, 1969. Hafıza ve Dikkat, New York, John Wiley and Sons.
Osgood CE, 1952. Anlamın doğası ve ölçümü, Psychological Bulletin, 49,197-237.
Paivio A., 1963. Sıfat-ad kelime sırası ve ad soyutluğunun bir işlevi olarak sıfat-ad çiftlerinin-ilişkilendirilmelerinin öğrenilmesi, Canadian J. of Psychology, 17,370-379.
Paivio A., 1965. Eşli-ilişkili öğrenmede soyutluk, imgeleme ve anlamlılık, J. of Verbal Learning and Verbal Behavior, 4, 32-38.
Paivio A., 1969. İlişkisel öğrenme ve hafızada zihinsel görüntüleme, Psychological Review, 76,241-263.
Paivio A., 1971. Görüntü ve Sözel Süreçler, New York, Holt, Rinehart ve Winston.
Paivio A., Csapo K., 1969. Somut-imge ve sözel bellek kodları, J. of Experimental Psychology, 80, 279-285.
Paivio A., Yiiille 1. C., Rogers TB, 1969. Serbest ve seri hatırlamada isim imgesi ve anlamlılık, J. of Experimental Psychology, 79, 509514.
Penfield W., 1959. Yorumlayıcı korteks, Science, 129, 1719-1725.
Peterson LR, Peterson MJ, 1959. Bireysel sözlü öğelerin kısa süreli akılda tutulması, J. of .Experimental Psychology, 58, 193-198.
Pollack, I., 1959. Mesaj belirsizliği ve mesaj alımı, J. of the Acoustical Society of America, 31, 1500-1508.
Posner M.I., 1969. Soyutlama ve tanıma süreci. İçinde: JT Spence ve G. H. Bower (editörler), Advances in Learning and Motivation (Cilt 3), New York, Academic Press.
Pozner M.I. Boies S.}., Eichelman WH, Taylor RL, 1969. Tek harflerin görsel ve isim kodlarının tutulması, J. of Experimental Psychology, 79 (I, Pt. 2).
Pozner M.I. Goldsmith R., Welton K. E., IT., 1967. Algılanan mesafe ve çarpık kalıpların sınıflandırılması, J. of Experimental Psychology, 73, 28-38.
Posner MI, Keele SW, 1968. Soyut fikirlerin doğuşu üzerine, J. of Experimental Psychology, 77,353-363.
Posner MI, Konick AF, 1966. Kısa süreli akılda tutmada müdahalenin rolü üzerine, J. of Experimental Psychology, 72, 221-231.
Posner MI, Mitchell RF, 1967. Kronometrik sınıflandırma analizi, Psychological Review, 74, 392-409.
Posner MI, Rossman E., 1965. Bilgi dönüşümlerinin boyutunun ve konumunun kısa süreli akılda tutma üzerindeki etkisi, J. of Experimental Psychology, 70,496-505.
Postman L., 1972. Organizasyon teorisine pragmatik bir bakış. İçinde: E. Tulving ve M. Donaldson (editörler). Hafıza Organizasyonu, New York, Academic Press.
Postman L., Keppel G., Stark K., 1965. Ardışık tepki sınıfları arasındaki ilişkinin bir sonucu olarak öğrenmeyi unutma, J. of Experimental Psy. chology,69,lll-118.
Postman L., Phillips L., 1965. Serbest hatırlamada kısa vadeli zamansal değişiklikler, Quarterly J. of Experimental Psychology, 17, 132-138.
Postman L., Rail L., 1957. Ölçüm yönteminin bir işlevi olarak akılda tutma, California Üniversitesi Psikoloji Yayınları, Berkeley, 8,217-270.
(Postman L., Stark K.., 1969. Aktarım ve müdahalede yanıt mevcudiyetinin rolü, J. of Experimental Psychology, 79, 168-177.
Postman L., Stark K., Fraser J., 1968. Interferanstaki geçici değişiklikler, J. of Verbal Learning and Verbal Behavior, 7, 672-694.
Postman L., Stark K., Henschel D., 1969. Unlearning sonrası iyileşme koşulları, J. of Experimental Psychology Monograph, 82 (I, Pt. 2).
Postman L., Underwood B. L, 1973. Müdahale teorisindeki kritik sorunlar, Memory and Cognition, 1, 19-40.
Prytulak LS, 1971. Doğal dil aracılığı, Bilişsel Psikoloji, 2, 1-56.
Pylyshyn ZW, 1973. Zihnin gözü zihnin beynine ne anlatır: Zihinsel imgelemenin eleştirisi, Psikolojik Bülten, 80.1-24.
QuilUan MR, 1969. Öğretilebilir dil kavrayıcı: Bir simülasyon programı ve dil teorisi, Communications of the Association for Computing Machinery, 12, 459-476.
Reicher GM, 1969. Uyarıcı materyalin anlam doluluğunun bir fonksiyonu olarak algısal tanıma, J. of Experimental Psychology, 81, 275-280.
Reitman JS, 1971. Kısa süreli bellekte unutma mekanizmaları. Bilişsel Psikoloji, 2, 185-195.
Reitman]. S., 1974. Örtülü prova olmaksızın, Kısa süreli hafızadaki bilgiler bozulur, J. of Verbal Learning and Verbal Behavior, 13, 365-377.
Rips L. L, Shoben EJ, Smith EE, 1973. Anlamsal mesafe ve anlamsal ilişkilerin doğrulanması, J. of Verbal Learning and Verbal Behavior, 12.1-20.
Rohwer WD, ]r., 1966. Eşli ortak öğrenmede sözlü ve görsel detaylandırma. Proje Okuryazarlık Raporları, Corneli Üniversitesi, no. 7:18-28.
Rosch E., 1973. Algısal ve anlamsal kategorilerin iç yapısı üzerine. In: TE Moore (ed.). Bilişsel Gelişim ve Dil Edinimi, New York, Academic Press.
Rumelhart DE, 1971. Kısa süreli görsel gösterimlerin çok bileşenli bir algı teorisi, J. of Mathematical Psychology, 91, 326-332.
Rumelhart DE, Lindsay PH, Norman DA, 1972. Uzun süreli bellek için bir süreç modeli. İçinde: E. Tulving ve W. Donaldson (editörler), Hafıza Organizasyonu, New York, Academic Press.
Rundus D., 1971. Serbest hatırlamada prova süreçlerinin analizi, J. of Experimental Psychology, 89,63-77.
Rundus D., Atkinson RC, 1970. Serbest hatırlamada prova süreçleri: Doğrudan gözlem için bir prosedür, J. of Verbal Learning and Verbal Behavior, 9.99-105.
kese/dir/. DS, 1967. Bağlı söylemin sözdizimsel ve anlamsal yönleri için tanıma belleği. Algı ve Psikofizik, 2, 437-442.
Salzinger K., Portnoy S., Feldman RS, 1962. İngilizcenin istatistiksel yapısına yaklaşıklık sırasının sözel tepkilerin yayılması üzerindeki etkisi, J. of Experimental Psychology, 64, 52-57.
Schwartz M., 1969. Eşli öğrenmede sözel arabulucuları kullanma talimatları, J. of Experimental Psychology, 79.1-5.
Selfridge 0. G., 1959. Pandemonium: Öğrenme için bir paradigma. İçinde: Düşünce Süreçlerinin Mekanizasyonu, Londra, HM Kırtasiye Ofisi.
Shepard RN, 1966. Organizasyon ve arama olarak öğrenme ve hatırlama, J. of Verbal Learning and Verbal Behavior, 5, 201-204.
Shepard RN, 1967. Sözcükler, cümleler ve resimler için tanıma belleği, J. of Verbal Learning and Verbal Behavior, 6, 156-163.
Shepard RN, 1968. Bilişsel psikoloji: U. Neisser'in kitabına ilişkin bir inceleme, American J. of Psychology, 81, 285-289.
Shepard RN, Chipman S., 1970. İç temsillerin ikinci dereceden izomorfizmi: Shapes of State, Cognitive Psychology, 1,1-17.
Shepard RN, Metzler }., 1971. Üç boyutlu nesnelerin zihinsel dönüşü, Science, 171,701-703.
Shepard RN, Teghtsoonian M., 1961. İstikrarlı duruma yaklaşan koşullar altında Bilginin Saklanması, J. of Experimental Psychology, 62, 302-309.
Shiffrin R. M-, 1970. Hafıza araştırması. İçinde: DA Norman (ed.). İnsan Hafızası Modelleri, New York, Academic Press.
Shiffrin RM, 1973. Kısa süreli bellekte bilgi kalıcılığı, J. of Experimental Psychology, 100, 39-49.
Shulman HG, 1971. Kısa süreli bellekte benzerlik etkileri. Psikoloji Bülteni, 75, 399-415.
Shulman HG, 1972. Kısa süreli bellekte anlamsal güven hataları, J. of Verbal Learning and Verbal Behavior, II, 221-227.
Simon H. A.. 1974 Bilim, 183, 482-488.
Simon HA, Barenfeld M., 1969. Problem çözmede algısal süreçlerin bilgi işleme analizi, Psychological Review, 76, 473-483.
Simon HA, Gilmartin K.., 1973. Satranç pozisyonları için hafıza simülasyonu, Bilişsel Psikoloji, 5, 29-46.
Slamecka N.1., 1960a. Uygulama düzeyinin bir işlevi olarak bağlantılı söylemin geriye dönük engellenmesi, J. of Experimental Psychology, 59, 104108.
Slamecka N.}., 1960b. Konu benzerliğinin bir sonucu olarak bağlantılı söylemin geriye dönük engellenmesi, J. of Experimental Psychology, 60, 245-249.
Slamecka N.}., 1966. Sözel çağrışımların öğrenilmesine karşı farklılaşma, J. of Experimental Psychology, 71, 822-828.
Slamecka NJ, 1968. Serbest hatırlamada eser depolamanın incelenmesi, J. of Experimental Psychology, 76, 504-513.
Slamecka NJ, 1969. Çoklu deneme hatırlamada çağrışımsal depolama için test etme, J. of Experimental Psychology, 81, 557-560.
Smith EE, 1967. Aşinalığın uyarıcı tanıma ve sınıflandırma üzerindeki etkileri, J. of Experimental Psychology, 74, 324-332.
Smith EE, Shoben E. L, Rips LJ, 1974. Anlamsal bellekte yapı ve süreç: Anlamsal karar için bir özellik modeli, Psychological Review, 81,214-241.
Smith EE, Spoehr K..R.., 1974. Basılı İngilizce algısı: Teorik bir bakış açısı. In: B. H. Kantowitz (ed.), Human Information Processing: Tutorials in Performance and Cognition, Potomac, Md., Eribaum Press.
Sperling 0., 1960. Kısa görsel sunumlarda bulunan Bilgiler, Psychological Monographs, 74 (Bütün No. 498).
Sperling G., 1967. Kısa süreli bellek için bir modele başarılı yaklaşımlar, Açta Psychologica, 27, 285-292.
Sperling G., Speelman RG, 1970. Akustik benzerlik ve işitsel kısa süreli bellek: Deneyler ve bir model. İçinde: D.A. Norman (ed.), Models of Human Memory, New York, Academic Press.
Ayakta L., Conezio J., Haber RN, 1970. Resimler için algı ve hafıza: 2560 görsel uyaranın tek deneme öğrenimi, Psychonomic Science, 19, 73-74.
Sternberg S., 1966. İnsan hafızasında yüksek hızlı tarama. İlim, 153, 652-654.
Sternberg S., 1967. Karakter tanımada iki işlem: RT ölçümünden bazı kanıtlar. Algı ve Psikofizik, 2, 45-53.
Sternberg S., 1969. Memory-scanning: Reaksiyon zamanı deneyleriyle ortaya çıkarılan zihinsel süreçler, American Scientist, 57, 421-457.
Tejirian E., 1968. İngilizceye yakınlaştırma emirlerinin hatırlanmasında sözdizimsel ve anlamsal yapı, J. of Verbal Learning and Verbal Behavior, 7,1010-1015.
Theios }., Smith P. G, Haviland SE, Traupmann }., Moy MC, 1973. Kendi kendini sonlandıran bir seri olarak bellek taraması, J. of Experimental Psychology, 97,323-336.
Thomson D. No., Tulving E., 1970. İlişkisel kodlama ve alma: Zayıf ve güçlü ipuçları, J. of Experimental Psychology, 86, 255262.
Thorndike EL, Büyük /., 1944. The Teachers Word Book of 30.000 Words, New York, Teachers College Press, Columbia Üniversitesi.
Tieman D. G" 1971. Karşılaştırmalı cümleler için tanıma belleği, Yayınlanmamış doktora tezi, Stanford Üniversitesi.
Townsend}. T.. 1972. Paralel ve seri süreçlerin tanımlanabilirliğine ilişkin bazı sonuçlar, British J. of Mathematical and Statistical Psychology, 25,168-199.
Treisman AM, 1960. Seçici dinlemede bağlamsal ipuçları, Quarterly J. of Experimental Psychology, 12, 242-248.
Treisman AM, 1964. Seçici dikkatte sözel ipuçları, dil ve anlam, American J. of Psychology, 77, 206-219.
Tulving E., 1962. Sözcüklerin serbest hatırlanmasında öznel organizasyon.
Psikolojik İnceleme, 69, 344-354.
Tulving E., 1964. Deneme içi ve denemeler arası akılda tutma: Serbest hatırlama sözel öğrenme teorisine yönelik notlar. Psikolojik İnceleme, 71, 219-237.
Tulving E., 1972. Olaysal ve anlamsal bellek. İçinde; E. Tulving ve W. Donaldson (editörler). Hafıza Organizasyonu, New York, Academic Press.
Tulving E., Osier S., 1968. Sözcükler için bellekte geri alma ipuçlarının etkinliği, J. of Experimental Psychology, 77, 593-601.
Tulving E., Patkau SE, 1962. Sözel materyalin anında hatırlanması ve öğrenilmesi üzerinde bağlamsal kısıtlama ve kelime sıklığının eşzamanlı etkileri, Canadian J. of Psychology, 16, 83-95.
Tulving E., Pearlstone Z., 1966. Kelimeler için bellekte Bilginin kullanılabilirliğine karşı erişilebilirliği, J. of Verbal Learning and Verbal Behavior, 5, 381-391.
Tulving E., Thompson DM, 1973. Olaysal bellekte kodlama özgüllüğü ve geri alma süreçleri. Psikolojik İnceleme, 80, 352-373.
Underwood BJ, 1948a. Beş kırk sekiz saat sonra geriye dönük ve proaktif engelleme, J. of Experimental Psychology, 38, 29-38.
Underwood BJ, 1948b. sözel çağrışımların kurtarılması, J. of Experimental Psychology, 38, 429-439.
Underwood BJ, 1949. Önceki öğrenmenin derecesi ve zamanın bir fonksiyonu olarak proaktif ketleme, J. of Experimental Psychology, 39, 24-34.
Underwood. BJ, 1965. Örtük sözel tepkilerin ürettiği yanlış tanıma, J. of Experimental Psychology, 70, 122-129.
Underwood BJ, Ekstrand BR, 1966. Bazı eksikliklerin analizi.
unutmanın müdahale teorisinde. Psikolojik İnceleme, 73, 540549.
Underwood BJ, Freund JS, 1968. Tanıma öğrenme ve akılda tutmadaki hatalar, J. of Experimental Psychology, 78, 55-63.
Underwood BJ, Freund}. S., 1970. Sözcük sıklığı ve kısa süreli tanıma belleği, American J. of Psychology, 83, 343-351.
Underwood BJ, Postman L., 1960. Unutmada deneyim dışı müdahale kaynakları, Psychological Review, 67, 73-95.
Wanner HE, 1968. Cümleleri hatırlama, unutma ve anlama üzerine: Derin yapı hipotezi üzerine bir çalışma. Yayımlanmamış doktora tezi, Harvard Üniversitesi.
Watkins MJ, Watkins O. C., 1973. Seri hatırlamada modalite etkisinin kategori sonrası durumu, J. of Experimental Psychology, 99, 226230.
Watkins MJ, Watkins OC, Craik F. 1. M., Mazuryk G., 1973. Sözel olmayan dikkat dağıtmanın kısa süreli depolama üzerindeki etkisi, J. of Experimental Psychology, 101,296-300.
Waugh NC, Norman D. A., 1965. Birincil bellek, Psikolojik İnceleme, 72.89-104.
Waugh NC, Norman D. A., 1968. Birincil bellekte girişimin ölçülmesi, J. of Verbal Learning and Verbal Behavior, 7, 617626.
Weber D. I, Castleman I, 1970. Hayal etmek için geçen süre, Perception and Psychophysics, 8, 165-168.
Wheeler DD, 1970. Sözcük yeniden tutuşmadaki süreçler, Bilişsel Psikoloji, 1, 59-85.
Wickelgren WA, 1965. Kısa süreli bellekte akustik benzerlik ve geriye dönük girişim, J. of Verbal Learning and Verbal Behavior, 4, 53-61.
Wickelgren WA, 1966. İngilizce ünsüzler için kısa süreli bellekte ayırt edici özellikler ve hatalar, J. of the Acoustical Society of America, 39, 388-398.
Wickelgren WA, 1973. Uzun ve kısa hafıza, Psychological Bulletin, 80,425-438.
Wickens DD, 1972. Kelime kodlamanın özellikleri. İçinde: A. W. Melton ve E. Martin (editörler), Coding Processes in Human Memory, New York, V. H. Winston and Sons.
Wickens D.D., Doğuştan D.G. Alien CK, 1963. Kısa süreli bellekte proaktif engelleme ve öğe benzerliği, J. of Verbal Learning and Verbal Behavior, 2,440-445.
Wilkins A., 1971. Birleşik frekans, kategori büyüklüğü ve kategorizasyon süresi, J. of Verbal Learning and Verbal Behavior, 10, 382-385.
Winograd E., 1968. Frekans ve tutma aralığının bir fonksiyonu olarak farklılaşmayı listeleyin, J. of Experimental Psychology, 76(2, Pt. 2.).
Wiseman G., Neisser U., 1971. Görsel tanıma belleğinin belirleyicisi olarak algısal organizasyon. Eastern Psychological Assn.
Wood G, 1972, Örgütsel süreçler ve yangın geri çağırma. İçinde: E. Tulving ve W. Donaldson (editörler). Hafıza Organizasyonu, New York, Academic Press.
Wood G, Underwood BJ, 1967. Örtük tepkiler ve kavramsal benzerlik, J. of Verbal Learning and Verbal Behavior, 6.1-10.
Woodward AE, }r., Bjork RA, longevnard RH, lr., 1973. Birincil provanın bir işlevi olarak hatırlama ve tanıma, J. of Verbal Learning and Verbal Behavior, 12, 608-617.
Zlusne L., 1970. Visual Perception of Form, New York, Academic Press.
Not: Bazen Büyük Dosyaları tarayıcı açmayabilir...İndirerek okumaya Çalışınız.
Yorumlar
Yorum Gönder